Clear Sky Science · nl
User eXperience Perception Insights Dataset (UXPID): Synthhetische gebruikersfeedback uit openbare industriële forums
Waarom online technische gesprekken ertoe doen
Dagelijks plaatsen mensen over de hele wereld vragen en klachten in supportforums van bedrijven wanneer hun software of industriële apparatuur niet goed werkt. In die threads zit een schat aan inzichten over waar echte gebruikers mee worstelen, wat ze goed vinden en wat ze nog nodig hebben. Toch is die informatie rommelig, verspreid en vaak gebonden aan privacyregels. Dit artikel introduceert een nieuwe manier om die verborgen kennis aan te boren zonder iemands persoonsgegevens prijs te geven.
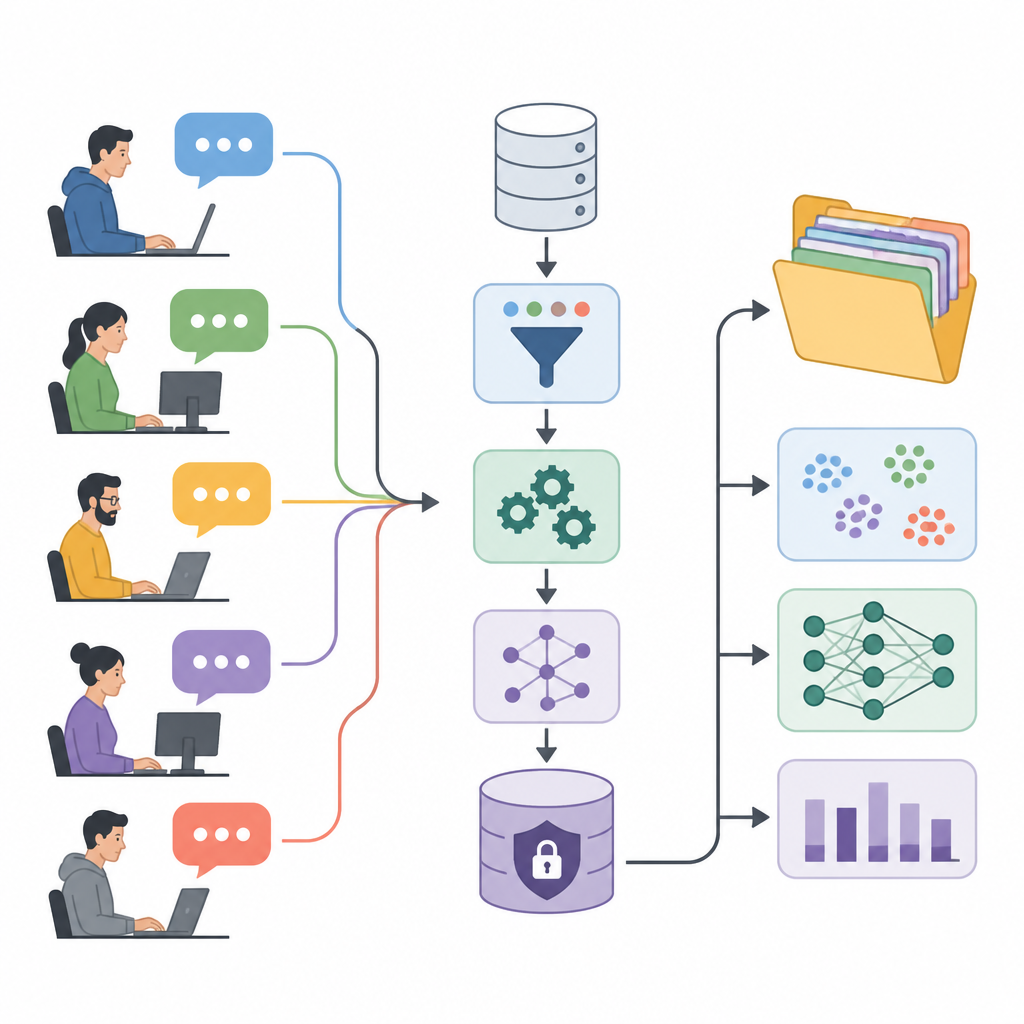
Forumpraat omzetten in onderzoeksbrandstof
De auteurs presenteren het User eXperience Perception Insights Dataset, of UXPID, een grote collectie synthetische gebruikersdiscussies gebaseerd op een openbaar forum voor industriële automatisering. In plaats van de oorspronkelijke berichten te delen, die namen, productcodes en bedrijfsgegevens kunnen bevatten, maakten ze zorgvuldig herschreven versies die de betekenis behouden maar gevoelige aanwijzingen verwijderen. Elk record beschrijft een volledige discussievertakking, beginnend bij de vraag van een gebruiker en inclusief alle antwoorden, zodat onderzoekers niet alleen individuele opmerkingen zien maar hele probleemoplossingsgesprekken.
Structuur toevoegen aan rommelige gesprekken
Wat UXPID onderscheidt is de rijke structuur die bovenop de ruwe tekst is aangebracht. Het team gebruikte een krachtig taalmodel om elke discussie te lezen en samenvattingen te maken van het hoofdprobleem, wat de gebruiker verwachtte dat er zou gebeuren en hoe ernstig het probleem leek. Het labelde ook elke tak met onderwerpen, gaf aan of de toon positief, negatief of neutraal was, en haalde korte zinnen naar voren over pijnpunten, voordelen en gevraagde functies. Dit verandert vrije conversatie in georganiseerde informatie waar computers van kunnen leren.
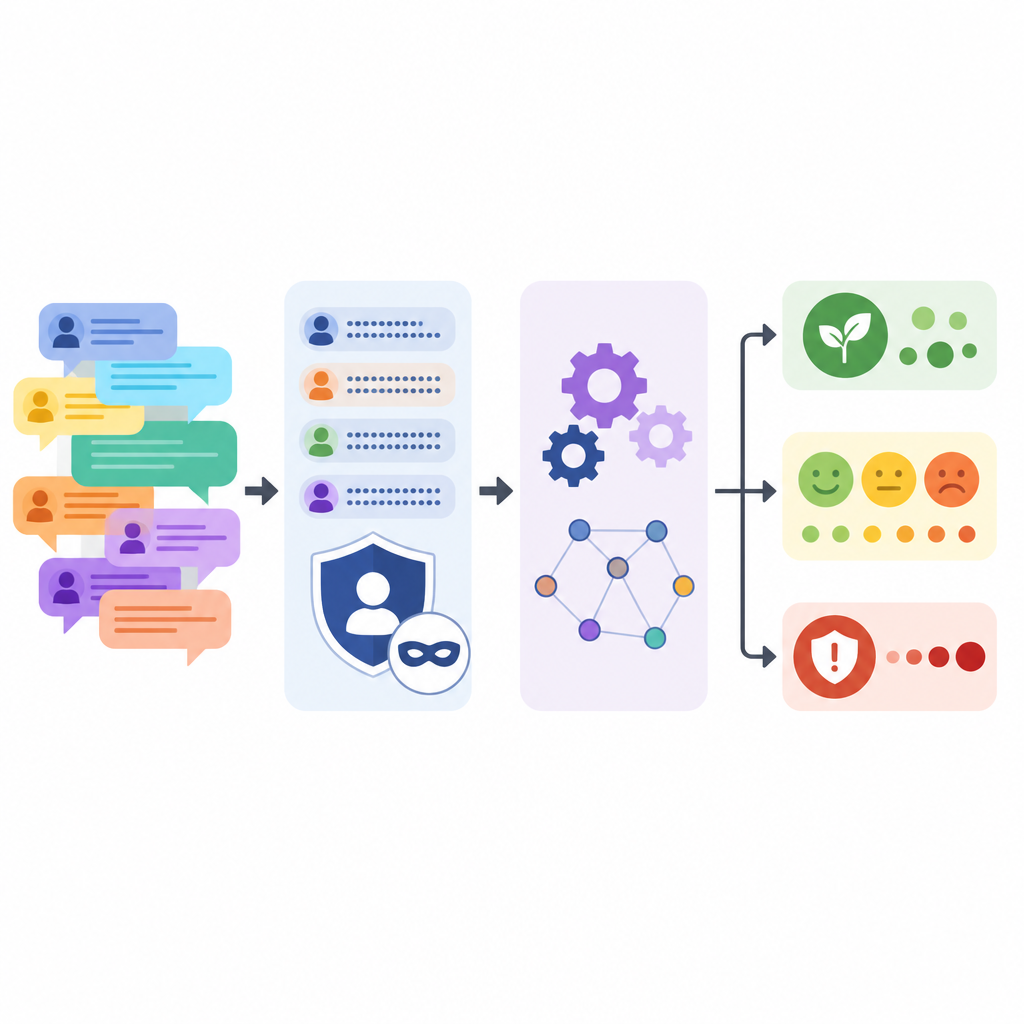
Mensen anoniem houden terwijl het verhaal behouden blijft
Het beschermen van forumdeelnemers was een centraal doel. Het taalmodel kreeg de opdracht bedrijfsnamen, productlabels, versienummers, persoonlijke namen, e‑mails en webkoppelingen te vervangen door eenvoudige plaatsaanduiders, terwijl het elke opmerking licht herformuleerde. Na deze geautomatiseerde stap voerde het team patroonherkenning uit om eventuele resterende aanwijzingen zoals e‑mail- of IP‑formaten te achterhalen, en controleerden ze steekproeven handmatig. Ze vergeleken ook de originele en verwerkte teksten, en lieten zien dat zinslengte en variatie vergelijkbaar bleven, ook al werden SCHREEUWEN IN HOOFDLETTERS en reeksen uitroeptekens afgezwakt.
De dataset op de proef stellen
Om te onderzoeken of de nieuwe dataset daadwerkelijk nuttig is, trainden de auteurs twee soorten computermodellen erop. Het ene was een klassieke woordtelt aanpak en het andere een modern transformermodel bekend als DistilBERT, dat context in zinnen kan vastleggen. Ze lieten deze modellen de onderwerplabels en de algemene stemming van elke discussie raden. De transformer presteerde consequent beter, vooral bij lastige gevallen met meerdere onderwerpen, wat suggereert dat UXPID rijk genoeg is om geavanceerde taalhulpmiddelen te ondersteunen voor taken zoals detectie van problemen en sentimentanalyse.
Wat dit betekent voor toekomstige tools
In eenvoudige termen laat het artikel zien dat het mogelijk is om rommelige, privéforumthreads om te zetten in een schone, deelbare bron die nog steeds het werkelijke productgebruik weerspiegelt. UXPID biedt duizenden geanonimiseerde, gelabelde gesprekken die anderen kunnen gebruiken om systemen te bouwen en te vergelijken die gebruikersfeedback op schaal lezen en begrijpen. Dit kan leiden tot slimmer supportgereedschap, betere productontwerpbeslissingen en nieuwe manieren om patronen in klantervaring te ontdekken, terwijl de privacy van de schrijvers van de oorspronkelijke berichten gerespecteerd wordt.
Bronvermelding: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Trefwoorden: gebruikersfeedback, technische forums, verwerking van natuurlijke taal, synthetische dataset, gebruikerservaring