Clear Sky Science · en
User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums
Why online tech chats matter
Every day, people around the world post questions and complaints in company support forums when their software or industrial devices misbehave. Buried in these threads is a gold mine of insight about what real users struggle with, what they like, and what they still need. Yet this information is messy, scattered, and often locked away by privacy rules. This article introduces a new way to tap into that hidden knowledge without exposing anyone’s personal details.
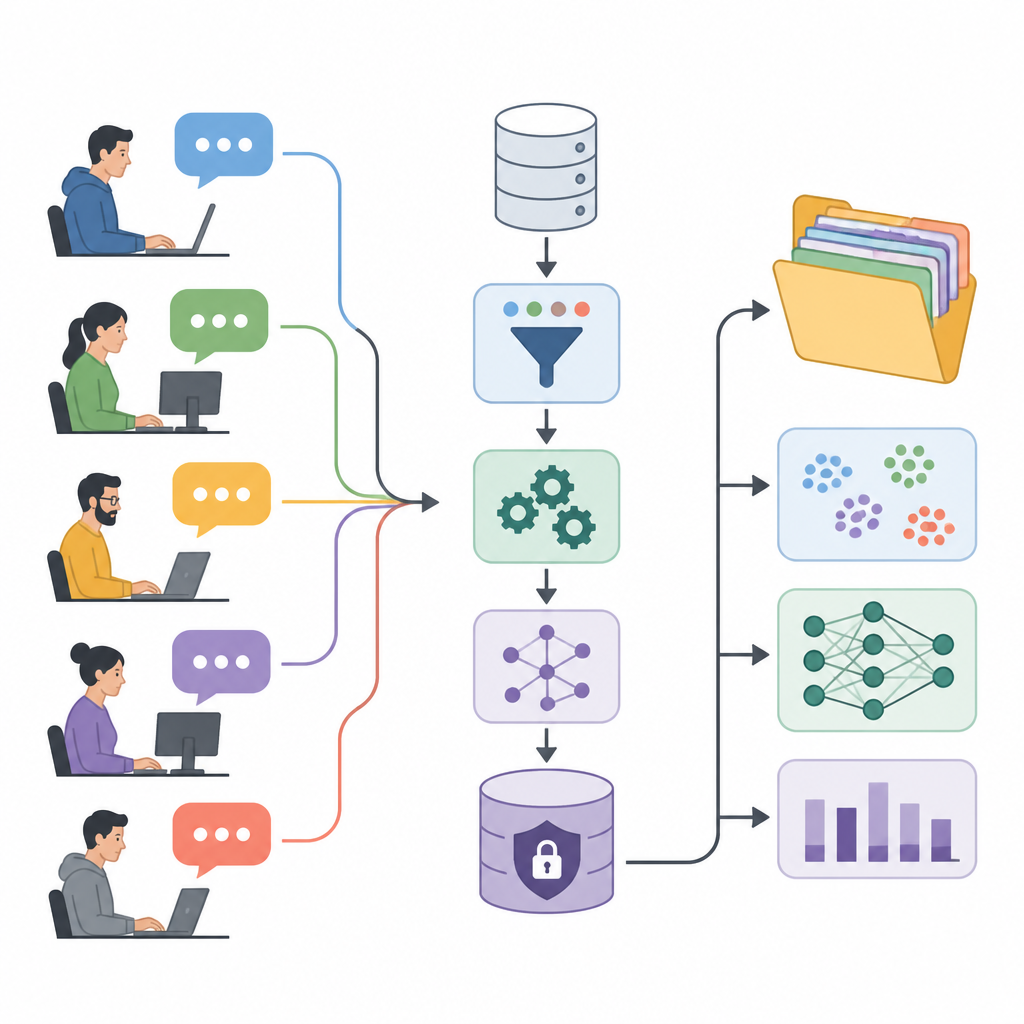
Turning forum talk into research fuel
The authors present the User eXperience Perception Insights Dataset, or UXPID, a large collection of synthetic user discussions based on a public industrial automation forum. Instead of sharing the original posts, which might contain names, product codes, and company details, they created carefully rephrased versions that keep the meaning but remove sensitive clues. Each record describes an entire discussion branch, starting from a user’s question and including all the replies, so that researchers can see not just single comments but whole problem solving conversations.
Adding structure to messy conversations
What makes UXPID stand out is the rich structure added on top of the raw text. The team used a powerful language model to read each discussion and produce summaries of the main issue, what the user expected to happen, and how severe the problem seemed. It also tagged each branch with topics, marked whether the tone was positive, negative, or neutral, and pulled out short phrases about pains, gains, and requested features. This turns free form chatter into organized information that computers can learn from.
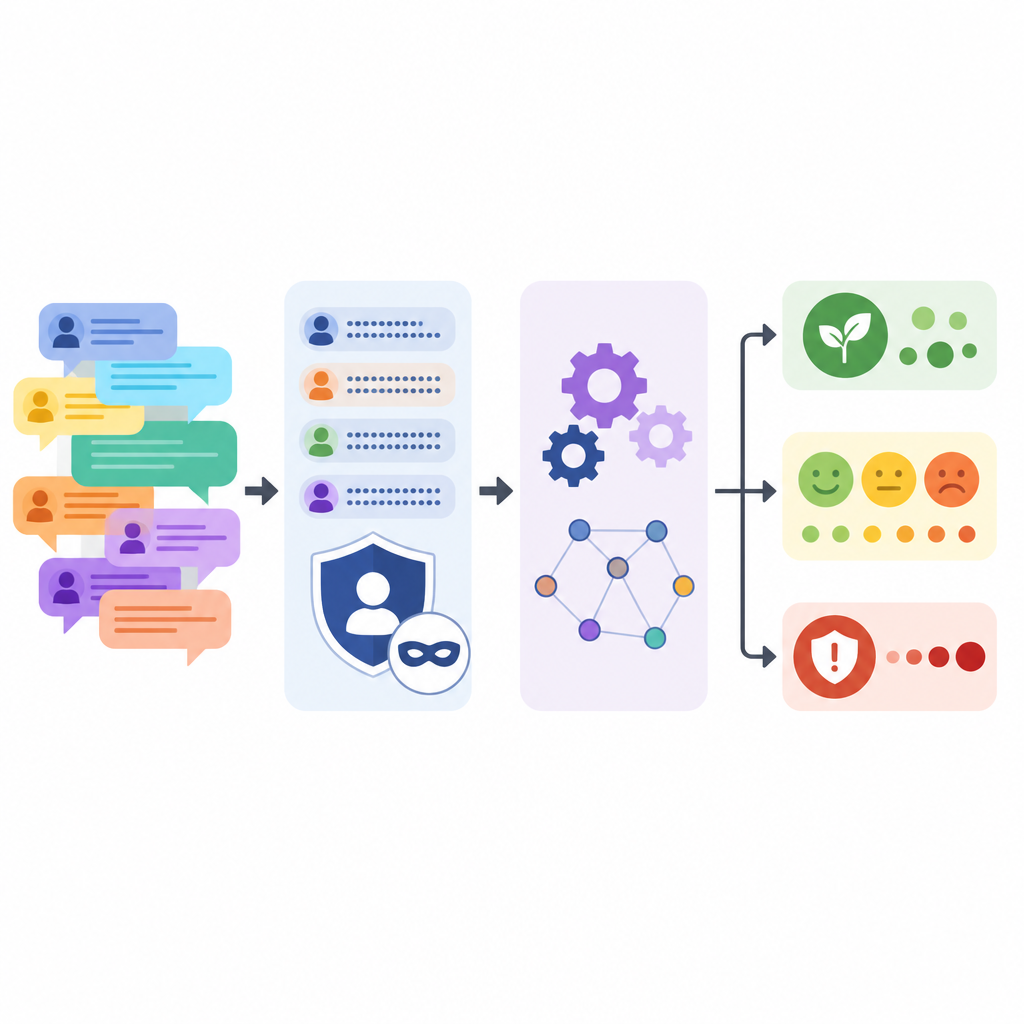
Keeping people anonymous while saving the story
Protecting forum participants was a central goal. The language model was instructed to replace company names, product labels, version numbers, personal names, emails, and web links with simple placeholders while lightly rewording each comment. After this automated pass, the team ran pattern matching to catch any remaining hints such as email or IP formats, and then manually checked samples. They also compared the original and processed texts, showing that sentence length and variety stayed similar, even though shouting in all caps and strings of exclamation marks were toned down.
Putting the dataset to the test
To see whether the new dataset is genuinely useful, the authors trained two kinds of computer models on it. One was a classic word counting approach, and the other was a modern transformer model known as DistilBERT that can capture context in sentences. They asked these models to guess the topic labels and the overall mood of each discussion. The transformer consistently did better, especially for tricky multi topic cases, which suggests that UXPID is rich enough to support advanced language tools for tasks like issue detection and sentiment analysis.
What this means for future tools
In simple terms, the paper shows that it is possible to turn noisy, private forum threads into a clean, shareable resource that still reflects real world product use. UXPID offers thousands of anonymized, labeled conversations that others can use to build and compare systems that read and understand user feedback at scale. This could lead to smarter support tools, better product design decisions, and new ways to spot patterns in customer experience, all while respecting the privacy of the people who wrote the original posts.
Citation: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Keywords: user feedback, technical forums, natural language processing, synthetic dataset, user experience