Clear Sky Science · sv
User eXperience Perception Insights Dataset (UXPID): Syntetisk användarfeedback från offentliga industriforum
Varför tekniksamtal på nätet spelar roll
Varje dag postar människor världen över frågor och klagomål i företags supportforum när deras mjukvara eller industriella enheter inte fungerar som de ska. Begravda i dessa trådar finns ett rikt källmaterial om vad verkliga användare kämpar med, vad de gillar och vad de fortfarande saknar. Men denna information är rörig, utspridd och ofta låst av sekretessregler. Denna artikel introducerar ett nytt sätt att ta tillvara den dolda kunskapen utan att utsätta någon för intrång i deras personliga uppgifter.
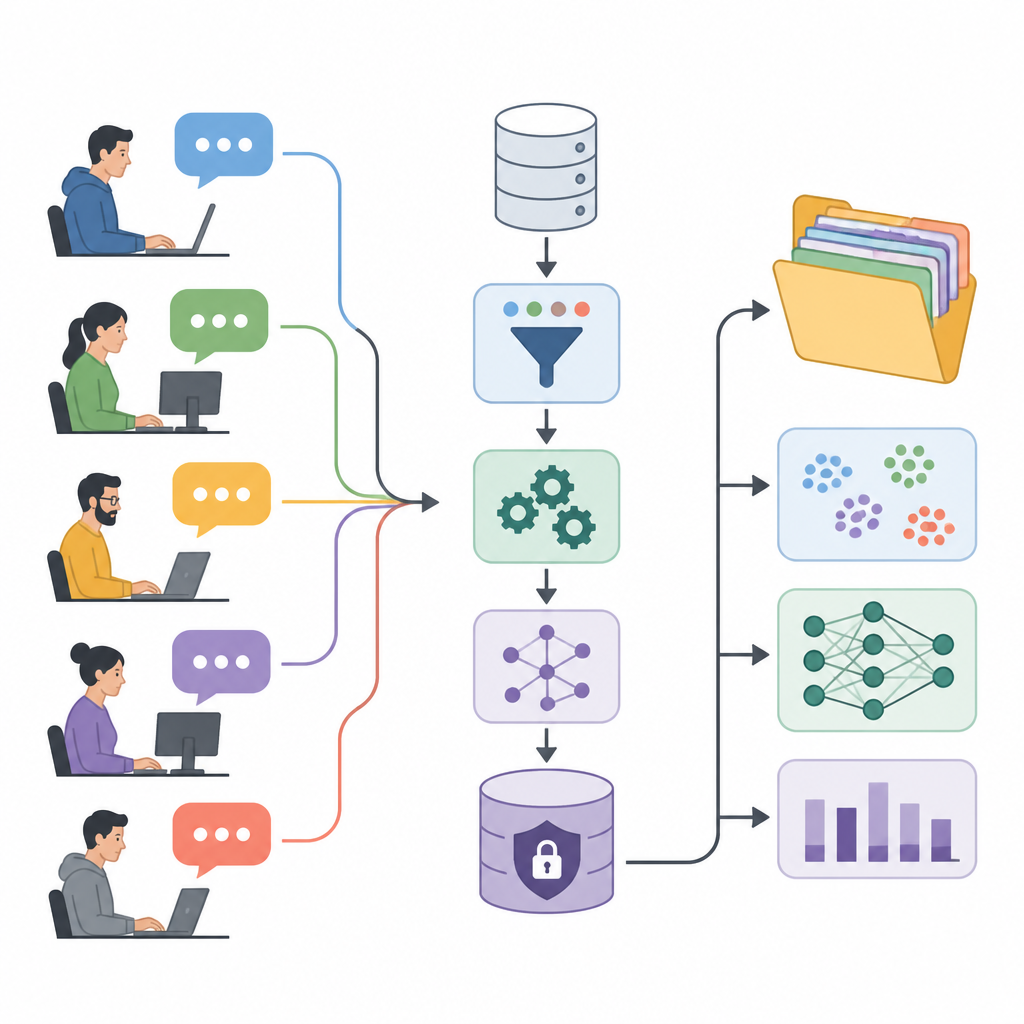
Att omvandla forumprat till forskningsbränsle
Författarna presenterar User eXperience Perception Insights Dataset, eller UXPID, en stor samling syntetiska användardiskussioner baserade på ett offentligt industriforum för automation. Istället för att dela originalinläggen, som kan innehålla namn, produktkoder och företagsdetaljer, skapade de noggrant omformulerade versioner som behåller innebörden men tar bort känsliga ledtrådar. Varje post beskriver en hel diskussionsgren, med start i en användares fråga och inklusive alla svar, så att forskare kan se inte bara enstaka kommentarer utan hela problemlösningskonversationer.
Att lägga struktur på röriga samtal
Det som gör UXPID särskilt är den rika struktur som lagts ovanpå råtexten. Teamet använde en kraftfull språkmodell för att läsa varje diskussion och producera sammanfattningar av huvudproblemet, vad användaren förväntade sig skulle hända och hur allvarligt problemet verkade vara. Den taggade också varje gren med ämnen, angav om tonen var positiv, negativ eller neutral, och plockade ut korta fraser om smärtpunkter, vinster och önskade funktioner. Detta förvandlar fritt formulerat prat till organiserad information som datorer kan lära sig från.
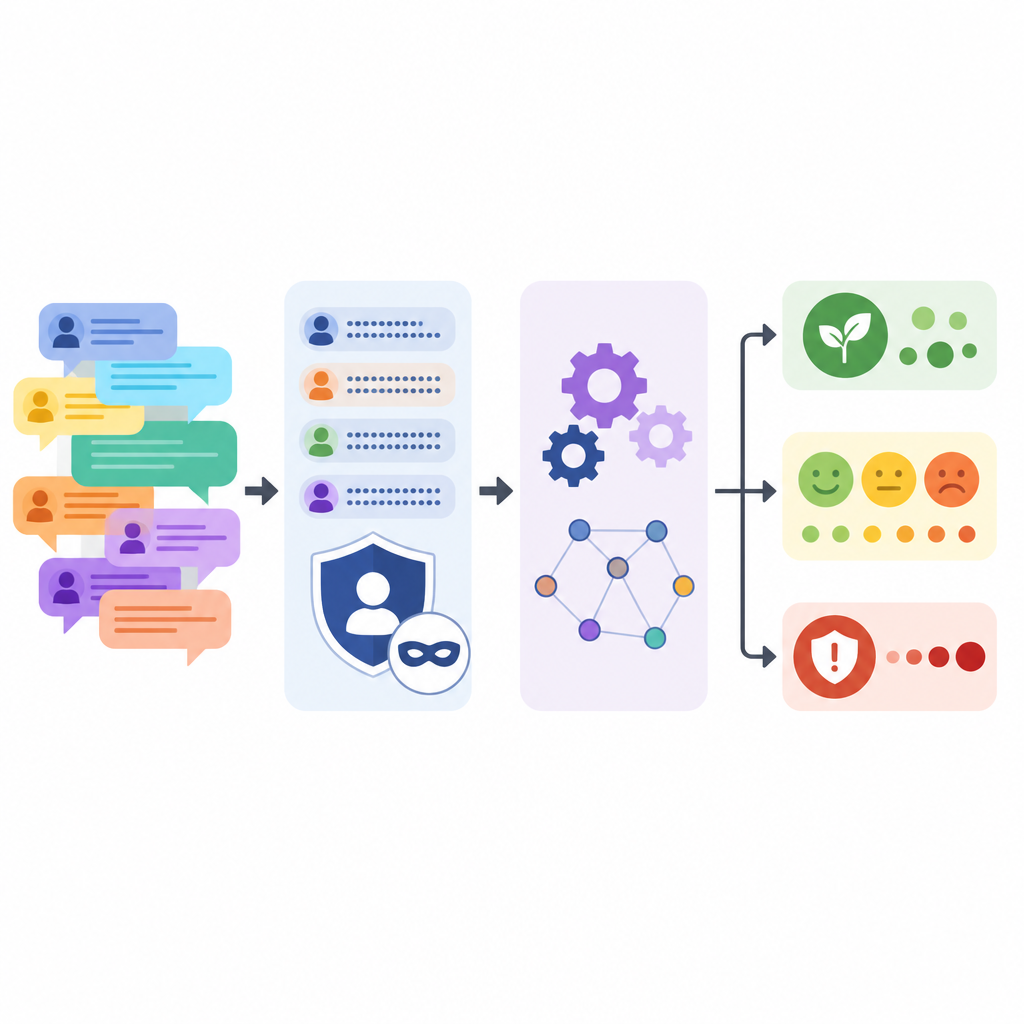
Att hålla människor anonyma samtidigt som berättelsen sparas
Att skydda forumdeltagarna var ett centralt mål. Språkmodellen fick instruktioner att ersätta företagsnamn, produktbeteckningar, versionsnummer, personnamn, e-postadresser och webblänkar med enkla platshållare samtidigt som varje kommentar lätt omformulerades. Efter detta automatiserade steg körde teamet mönstermatchning för att fånga eventuella återstående ledtrådar som e-post- eller IP-format, och sedan granskade man manuella stickprov. De jämförde också original- och bearbetade texter och visade att meningslängd och variation förblev liknande, även om skrikande text i versaler och lång rad utropstecken dämpades.
Sätta datamängden på prov
För att se om den nya datamängden verkligen är användbar tränade författarna två typer av datorbaserade modeller på den. Den ena var en klassisk räkningsbaserad ordmodell och den andra en modern transformer-modell känd som DistilBERT som fångar kontext i meningar. De bad dessa modeller att gissa ämnesetiketterna och den övergripande stämningen i varje diskussion. Transformern presterade konsekvent bättre, särskilt i svåra fall med flera ämnen, vilket tyder på att UXPID är tillräckligt rik för att stödja avancerade språkinstrument för uppgifter som felupptäckt och sentimentanalys.
Vad detta betyder för framtida verktyg
Enkelt uttryckt visar artikeln att det är möjligt att omvandla brusiga, privata forumtrådar till en ren, delbar resurs som ändå speglar verklig produktanvändning. UXPID erbjuder tusentals anonymiserade, etiketterade konversationer som andra kan använda för att bygga och jämföra system som läser och förstår användarfeedback i stor skala. Detta kan leda till smartare supportverktyg, bättre produktdesignbeslut och nya sätt att upptäcka mönster i kundupplevelser — allt samtidigt som man respekterar integriteten hos dem som skrev de ursprungliga inläggen.
Citering: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Nyckelord: användarfeedback, tekniska forum, behandling av naturligt språk, syntetisk datamängd, användarupplevelse