Clear Sky Science · ar
مجموعة بيانات رؤى إدراك تجربة المستخدم (UXPID): تغذية راجعة للمستخدمين اصطناعية من منتديات صناعية عامة
لماذا تهم دردشات التقنية على الإنترنت
يوماً بعد يوم، ينشر أشخاص حول العالم أسئلة وشكاوى في منتديات دعم الشركات عندما تتعطل برامجهم أو أجهزتهم الصناعية. مدفون في هذه السلاسل كنز من الرؤى حول ما يواجهه المستخدمون الحقيقيون من صعوبات، وما يحبونه، وما يزالون بحاجة إليه. ومع ذلك، هذه المعلومات فوضوية ومبعثرة وغالباً محجوزة بقواعد الخصوصية. تقدم هذه المقالة طريقة جديدة للوصول إلى تلك المعرفة المخفية من دون كشف تفاصيل شخصية لأي فرد.
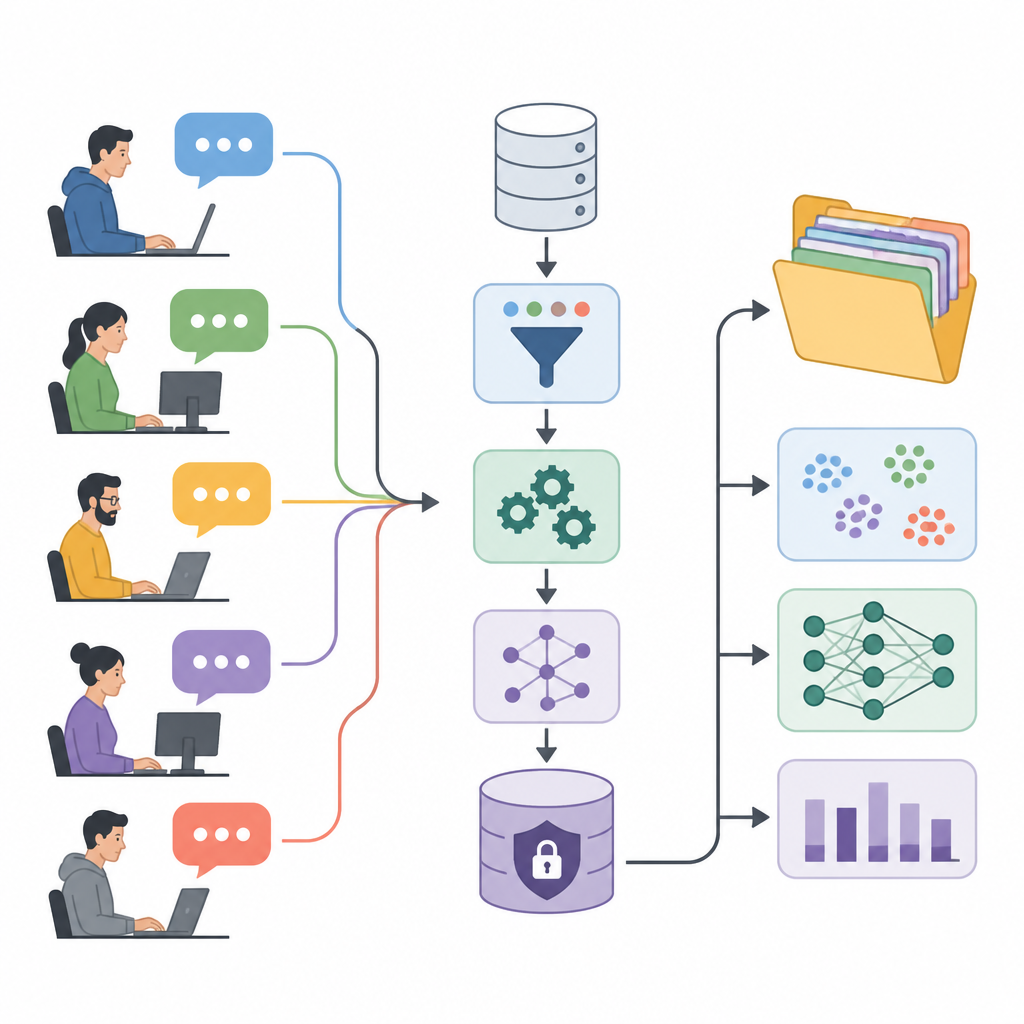
تحويل أحاديث المنتديات إلى وقود بحثي
يعرض المؤلفون مجموعة بيانات رؤى إدراك تجربة المستخدم، أو UXPID، وهي مجموعة كبيرة من المناقشات الاصطناعية للمستخدمين مستمدة من منتدى صناعي عام لأتمتة العمليات. بدلاً من مشاركة المنشورات الأصلية التي قد تحتوي على أسماء، رموز منتجات، وتفاصيل شركات، أنشأوا نسخاً معاد صياغتها بعناية تحافظ على المعنى لكنها تزيل المؤشرات الحساسة. يصف كل سجل فرع نقاش كامل، بدءاً من سؤال المستخدم وشاملةً جميع الردود، حتى يتمكن الباحثون من رؤية ليس تعليقاً واحداً فقط بل محادثات حل المشكلات بأكملها.
إضافة هيكل إلى المحادثات الفوضوية
ما يميز UXPID هو البنية الغنية المضافة فوق النص الخام. استخدمت الفريق نموذج لغة قوي لقراءة كل نقاش وإنتاج ملخصات للمشكلة الرئيسية، وما كان يتوقعه المستخدم أن يحدث، ومدى شدة المشكلة. كما وسم كل فرع بمواضيع، وحدد ما إذا كان النبرة إيجابية أو سلبية أو محايدة، واستخرج عبارات قصيرة حول الآلام، المكتسبات، والميزات المطلوبة. يحول هذا الثرثرة الحرة إلى معلومات منظمة يمكن للحواسيب أن تتعلم منها.
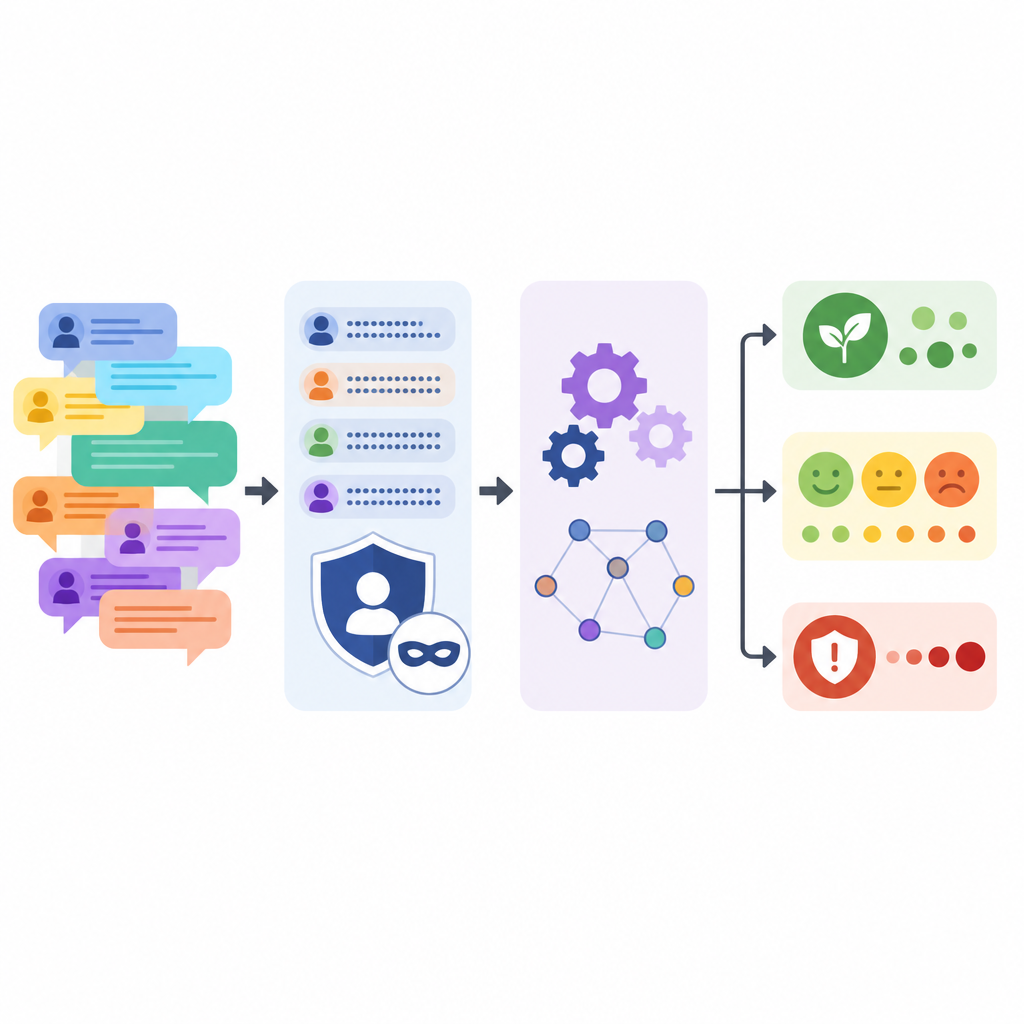
حفظ سرية الناس مع الاحتفاظ بالقصة
كان حماية المشاركين في المنتديات هدفاً مركزياً. طُلب من نموذج اللغة استبدال أسماء الشركات، تسميات المنتجات، أرقام الإصدارات، الأسماء الشخصية، عناوين البريد الإلكتروني، وروابط الويب بعناصر نائبة بسيطة مع إعادة صياغة طفيفة لكل تعليق. بعد هذه المرحلة الآلية، نفذ الفريق مطابقة أنماط لالتقاط أي إشارات متبقية مثل صيغ البريد الإلكتروني أو عناوين IP، ثم راجعوا عينات يدوياً. كما قارنوا النصوص الأصلية والمعالجة، مبينين أن طول الجملة وتنوعها بقي متشابهاً، رغم أن الصراخ بالحروف الكبيرة وسلاسل علامات التعجب تم تلطيفها.
اختبار مجموعة البيانات
لفحص ما إذا كانت المجموعة الجديدة مفيدة فعلاً، درب المؤلفون نوعين من النماذج الحاسوبية عليها. أحدهما كان نهج احتساب الكلمات الكلاسيكي، والآخر كان نموذج محول حديث يعرف باسم DistilBERT الذي يمكنه التقاط السياق داخل الجمل. طلبوا من هذه النماذج تخمين تسميات الموضوعات والمزاج العام لكل نقاش. تفوق نموذج المحول باستمرار، خصوصاً في الحالات متعددة المواضيع المعقدة، مما يشير إلى أن UXPID غني بما يكفي لدعم أدوات لغوية متقدمة لمهام مثل كشف المشاكل وتحليل المشاعر.
ماذا يعني هذا للأدوات المستقبلية
بعبارة بسيطة، تُظهر الورقة أنه من الممكن تحويل سلاسل منتديات فوضوية وخاصة إلى مورد نظيف وقابل للمشاركة يعكس مع ذلك استخدام المنتج في العالم الحقيقي. تقدم UXPID آلاف المحادثات المعمّية والمعنونة التي يمكن للآخرين استخدامها لبناء ومقارنة أنظمة تقرأ وتفهم تغذية المستخدمين على نطاق واسع. قد يقود هذا إلى أدوات دعم أذكى، قرارات تصميم منتج أفضل، وطرق جديدة لاكتشاف أنماط تجربة العملاء، كل ذلك مع احترام خصوصية من كتبوا المنشورات الأصلية.
الاستشهاد: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
الكلمات المفتاحية: تغذية راجعة من المستخدمين, منتديات تقنية, معالجة اللغة الطبيعية, مجموعة بيانات اصطناعية, تجربة المستخدم