Clear Sky Science · zh
OBIMD:用于甲骨文语境解读的多模态数据集
从古老骨片中解读信息
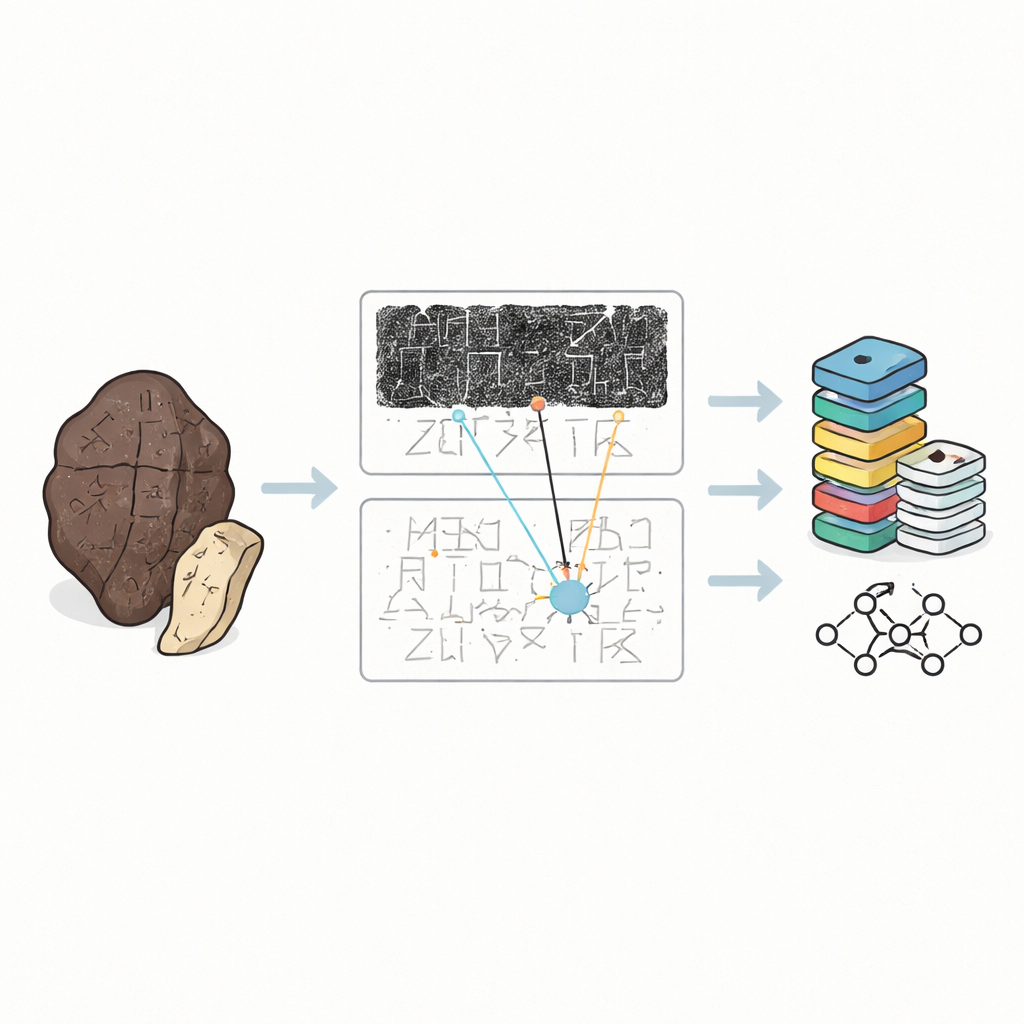
三千多年前,中国的皇家占卜者在兽骨和龟甲上刻下向神灵提问的文字,然后用火加热直到裂开。这些甲骨保存着世界上最早完整文字之一,但如今它们作为脆弱的碎片散落在博物馆和文献中。本文介绍了 OBIMD,这是一套新的数字收藏,汇集了这些铭文的影像与专家校读,为历史学家和计算机提供了一种强有力的途径,以研究这种古老文字的运作方式以及它所揭示的早期中国社会。
为什么古甲骨难以辨认
甲骨并非整齐的文本页。它们有缺口、被烧焦,常常破裂成碎片,文字沿着弯曲的表面以令人费解的方向延展。学者们很少直接触碰原件。取而代之的是,他们依赖三种替代资料:从骨面取下的黑色拓片、拼清笔画的手绘摹本,以及显示专家如何解读文本的印刷校读本。迄今为止,大多数数字收藏把从拓片中剪切出来的单个字符视为孤立的图像。这对训练计算机识别形状有用,但却忽视了人类专家在辨认不清或受损的字形时所倚赖的更大语境。
每块有铭骨的详尽数字化地图
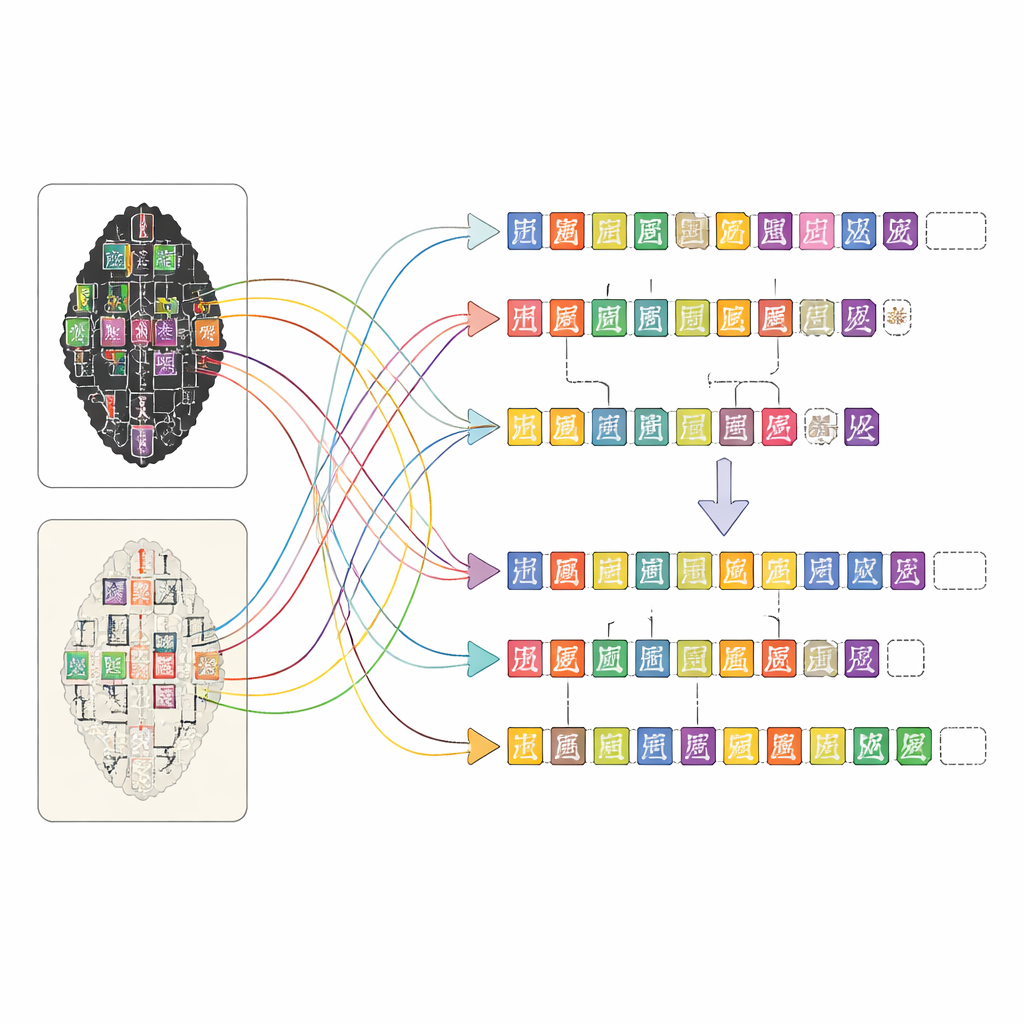
OBIMD 改变了这种做法,把每块骨头当作一个小而有结构的世界来处理。在一万多处铭刻中,作者为每件提供了配对的拓片和摹本图像,并用边界框标注每个可辨认字符的位置。他们还记录了因骨片缺失而明显丢失的字符位置,用特殊的空框作为占位符。这些字符与空缺被分组为句子或其他功能单元,且阅读顺序——常常是环绕或非线性的——被明确写入数据。因此,该数据集不仅指出骨片上出现了哪些形状,还说明了这些形状如何构成文本行、遵循何种顺序以及文本的哪些部分已遗失。
结合人类专业知识与机器辅助
为数千份复杂铭文构建如此详尽的地图,单靠人工几乎不可能完成。研究团队设计了一个基于网络的平台,让不同训练水平的人协同高效工作。首先,计算机视觉工具扫描拓片与摹本图像,建议字符可能的位置并指出它们与专业字库中条目的相似性。然后非专业注释员通过比较影像和查阅已扫描的专家校读页来细化这些建议。受过甲骨学训练的研究生会复核他们的工作,经验丰富的专家则解决难题,例如严重损坏的字或有争议的读法。这种分层流程在保持高质量的同时,使繁重的注释任务可管理。
教机器阅读古代文字
为了展示 OBIMD 的用途,作者用它训练和测试了现代机器学习模型,完成若干受人类专家阅读甲骨方式启发的任务。一种模型学会在完整图像上直接定位和识别字符,而不是仅在预切分的图块上作业,在较干净的摹本图上表现最好,在噪声较多的拓片上则对细微变体最为吃力。另一种模型学会根据字符的位置和形状将其分组为句子,大多能成功,但在文本行重叠时仍会混淆边界。第三种模型则被训练来恢复句子中打乱字符的原始阅读顺序,在多数情况下准确猜出确切顺序,并在很多其他情况下接近。总体而言,这些测试表明 OBIMD 既能推动进展,又能揭示自动阅读古文字时仍存的挑战。
这对我们理解过去意味着什么
对非专业读者来说,关键结论是 OBIMD 将零散、脆弱的早期汉字痕迹转化为一致且可被计算机读取的资源。通过对齐影像、专家摹本和句级校读,并谨慎标注缺失与保存之处,该数据集反映了人类学者如何从受损文物中拼凑意义。它为大规模研究语言变化、书写实践和商代王室生活打开了大门,也为旨在“读”过去的人工智能系统提供了苛刻的测试平台。简言之,OBIMD 不是对甲骨的直接翻译,但它是未来历史学家与算法探索这些文物时将依赖的详尽地图。
引用: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
关键词: 甲骨文, 古代文字, 数字人文, 多模态数据集, AI 文本识别