Clear Sky Science · en
OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions
Unlocking Messages from Ancient Bones
Over three millennia ago, royal diviners in China carved questions to the spirits onto animal bones and turtle shells, then heated them until they cracked. These oracle bones preserve some of the world’s earliest full writing, but today they survive as fragile fragments scattered across museums and books. This study introduces OBIMD, a new digital collection that brings together images and expert readings of these inscriptions, giving historians and computers alike a powerful way to study how this ancient script worked and what it reveals about early Chinese society.
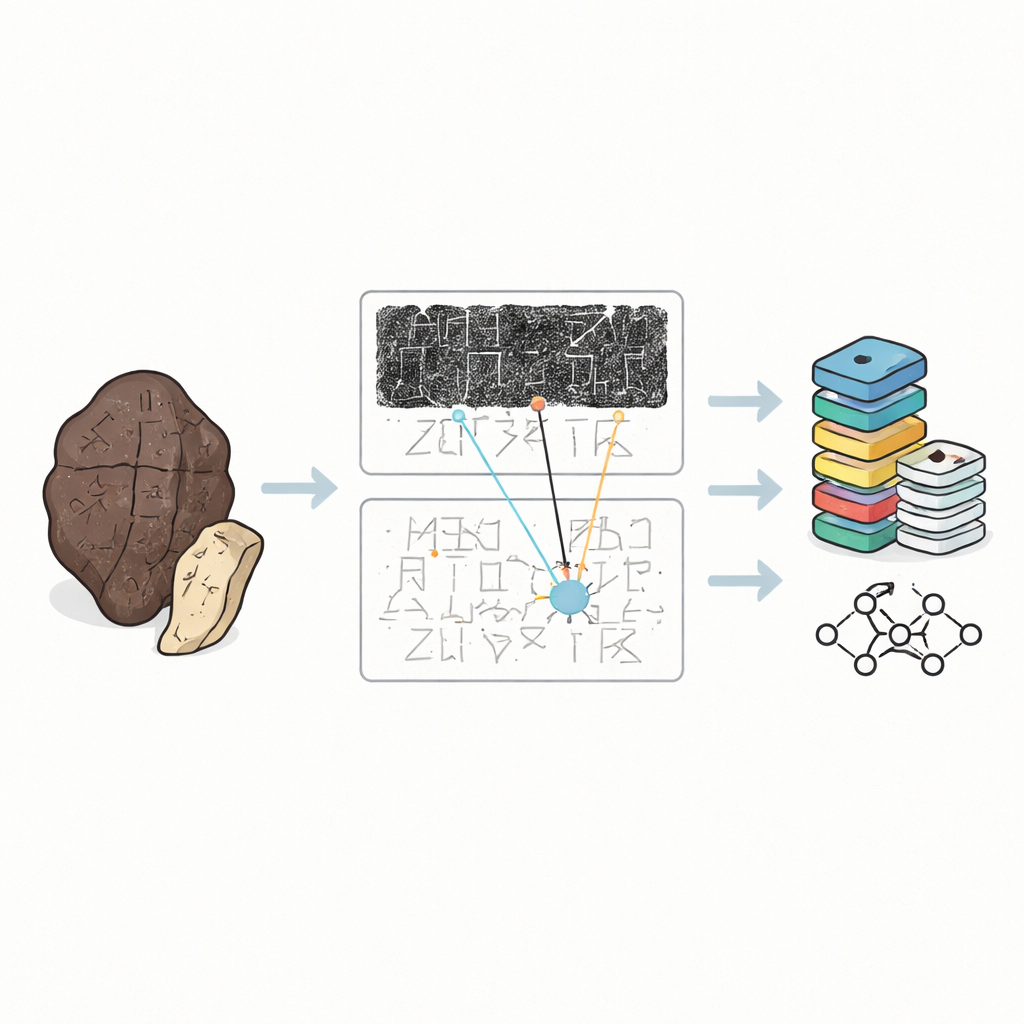
Why Old Bones Are Hard to Read
Oracle bones are not tidy pages of text. They are chipped, burnt, and often broken into pieces, with the writing winding around the curved surface in puzzling directions. Scholars rarely handle the originals. Instead, they rely on three kinds of stand-ins: dark inked rubbings taken from the surface of the bone, hand-drawn facsimiles that clarify the strokes, and printed transcriptions that show how experts think the text should be read. Until now, most digital collections treated single characters cut out from rubbings as isolated pictures. That is useful for training computers to recognize shapes, but it ignores the larger context that human experts actually use to decipher unclear or damaged signs.
A Rich Digital Map of Each Inscribed Bone
OBIMD changes this picture by treating each bone as a small, structured world of its own. For more than ten thousand inscriptions, the authors provide a matching rubbing and facsimile image, and then mark every legible character’s location with a bounding box. They also record spots where a character is clearly missing because the bone has broken away, placing special empty boxes as placeholders. These characters and gaps are grouped into sentences or other functional units, and the reading order—often looping and non-linear—is explicitly written into the data. As a result, the dataset does not just say what shapes appear on a bone, but also how they form lines of text, what sequence they follow, and where the text has been lost.
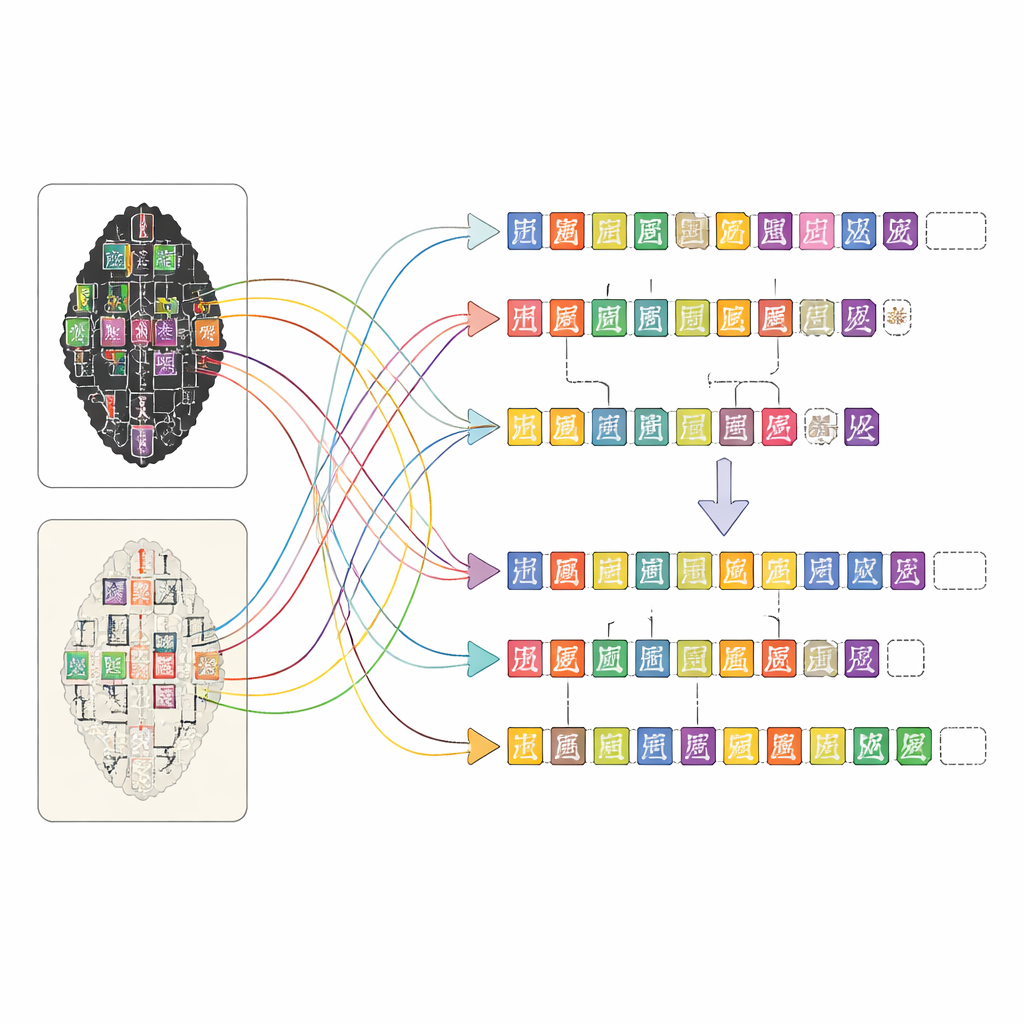
Combining Human Expertise and Machine Help
Building such a detailed map for thousands of complex inscriptions would be impossible by hand alone. The team designed a web-based platform that lets people with different levels of training work together efficiently. First, computer-vision tools scan the rubbing and facsimile images to suggest where characters might be and which entries in a specialist character library they resemble. Then non-specialist annotators refine these suggestions by comparing the images and consulting scanned pages of expert transcriptions. Graduate students with training in oracle bone studies review their work, and seasoned experts resolve the tough cases, such as badly damaged signs or disputed readings. This layered approach keeps the quality high while making the monumental task of annotation manageable.
Teaching Computers to Read Ancient Writing
To see what OBIMD enables, the authors used it to train and test modern machine-learning models on several tasks inspired by how human experts read bones. One model learned to locate and identify characters directly on the full images, not just on pre-cut patches, performing best on the cleaner facsimile drawings and struggling most with subtle variants in noisy rubbings. Another model learned to group characters into sentences based on their positions and shapes, mostly succeeding but still mixing up boundaries when lines of text overlapped. A third model was trained to restore the original reading order of jumbled characters within a sentence, correctly guessing the exact order in most cases and coming close in many others. Together, these tests show that OBIMD can both drive progress and expose the remaining challenges in automatic reading of ancient scripts.
What This Means for Our Picture of the Past
For non-specialists, the key message is that OBIMD turns scattered, fragile traces of early Chinese writing into a coherent, computer-readable resource. By aligning images, expert drawings, and sentence-level readings, and by carefully marking what is missing as well as what survives, the dataset mirrors how human scholars actually piece together meaning from damaged artifacts. It opens the door to large-scale studies of language change, scribal practice, and royal life in the Shang dynasty, and it offers a demanding testbed for artificial intelligence systems that aim to read the past. In short, OBIMD is not a translation of oracle bones, but it is the detailed map that future historians and algorithms will use to explore them.
Citation: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Keywords: oracle bone inscriptions, ancient writing, digital humanities, multimodal dataset, AI text recognition