Clear Sky Science · de
OBIMD: Ein multimodales Datenset zur kontextuellen Interpretation von Orakelknochenschriften
Nachrichten aus alten Knochen entschlüsseln
Vor über dreitausend Jahren ritzen königliche Wahrsager in China Fragen an die Geister in Tierknochen und Schildkrötenpanzer und erhitzten sie, bis sie rissen. Diese Orakelknochen bewahren einen Teil der frühesten vollständigen Schrift der Welt, überdauern aber heute nur als fragile Fragmente in Museen und Büchern. Diese Studie führt OBIMD ein, eine neue digitale Sammlung, die Bilder und fachkundige Lesungen dieser Inschriften zusammenführt und Historikern wie Computern gleichermaßen ein mächtiges Mittel liefert, um zu untersuchen, wie diese antike Schrift funktionierte und was sie über die frühe chinesische Gesellschaft verrät.
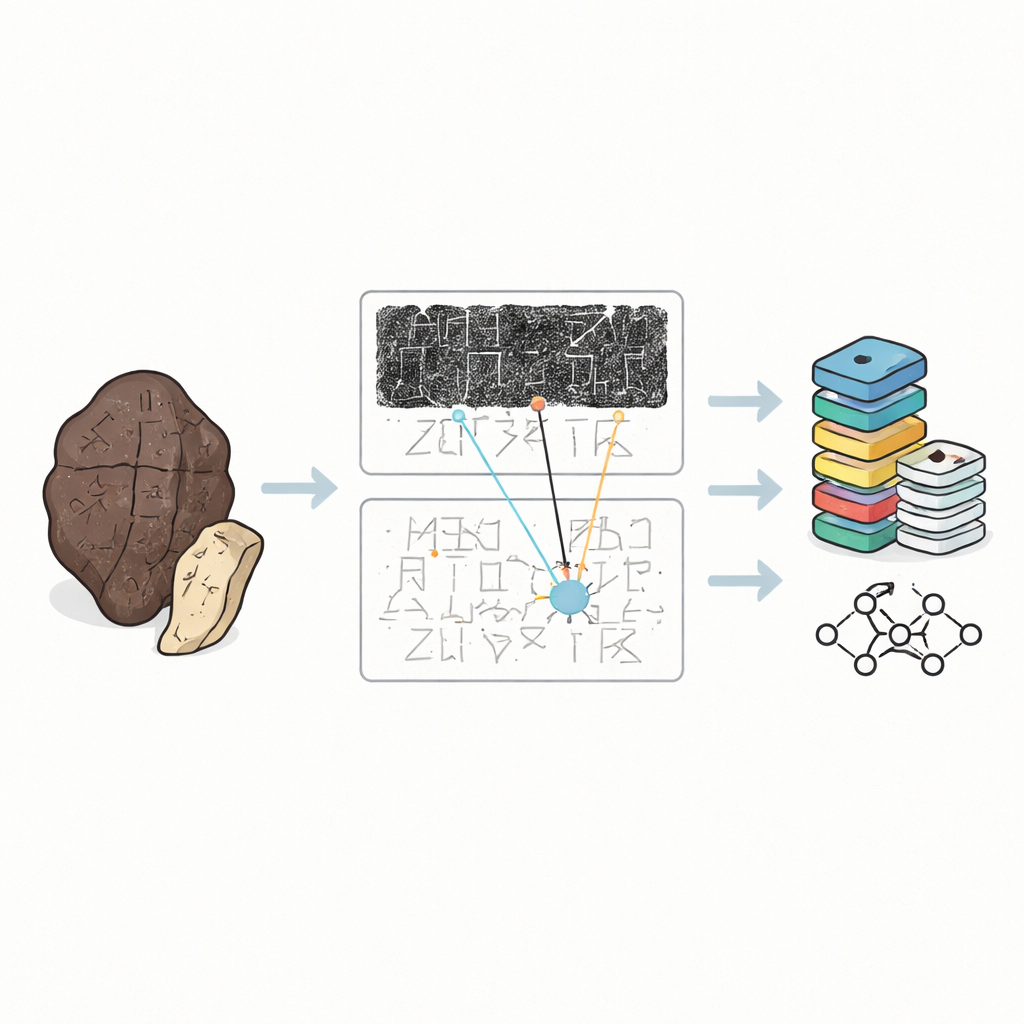
Warum alte Knochen schwer zu lesen sind
Orakelknochen sind keine ordentlichen Textseiten. Sie sind abgesplittert, verbrannt und oft in Stücke gebrochen, wobei die Schrift sich um die gebogene Oberfläche windet und in verwirrenden Richtungen verläuft. Gelehrte berühren die Originale nur selten. Stattdessen arbeiten sie mit drei Arten von Stellvertretern: dunklen Tusche-Abreibungen, die von der Oberfläche des Knochens genommen werden, handgezeichneten Facsimiles, die die Striche klären, und gedruckten Transkriptionen, die zeigen, wie Expertinnen und Experten den Text lesen. Bislang behandelten die meisten digitalen Sammlungen einzelne aus Abreibungen ausgeschnittene Zeichen als isolierte Bilder. Das ist nützlich, um Computern das Erkennen von Formen beizubringen, ignoriert aber den größeren Kontext, den menschliche Expertinnen und Experten tatsächlich nutzen, um unklare oder beschädigte Zeichen zu entziffern.
Eine reichhaltige digitale Karte jedes beschrifteten Knochens
OBIMD verändert dieses Bild, indem jedes Knochenstück als eine kleine, strukturierte Welt für sich behandelt wird. Für mehr als zehntausend Inschriften stellen die Autorinnen und Autoren eine passende Abreibung und ein Facsimile-Bild bereit und markieren dann die Lage jedes lesbaren Zeichens mit einer Begrenzungsbox. Sie verzeichnen auch Stellen, an denen ein Zeichen klar fehlt, weil der Knochen abgebrochen ist, und setzen besondere leere Boxen als Platzhalter. Diese Zeichen und Lücken werden zu Sätzen oder anderen funktionalen Einheiten gruppiert, und die Lesereihenfolge — oft verschlungen und nicht-linear — wird explizit in den Daten vermerkt. Dadurch sagt das Datenset nicht nur, welche Zeichen auf einem Knochen erscheinen, sondern auch, wie sie Textzeilen bilden, welche Sequenz sie folgen und wo Text verloren gegangen ist.
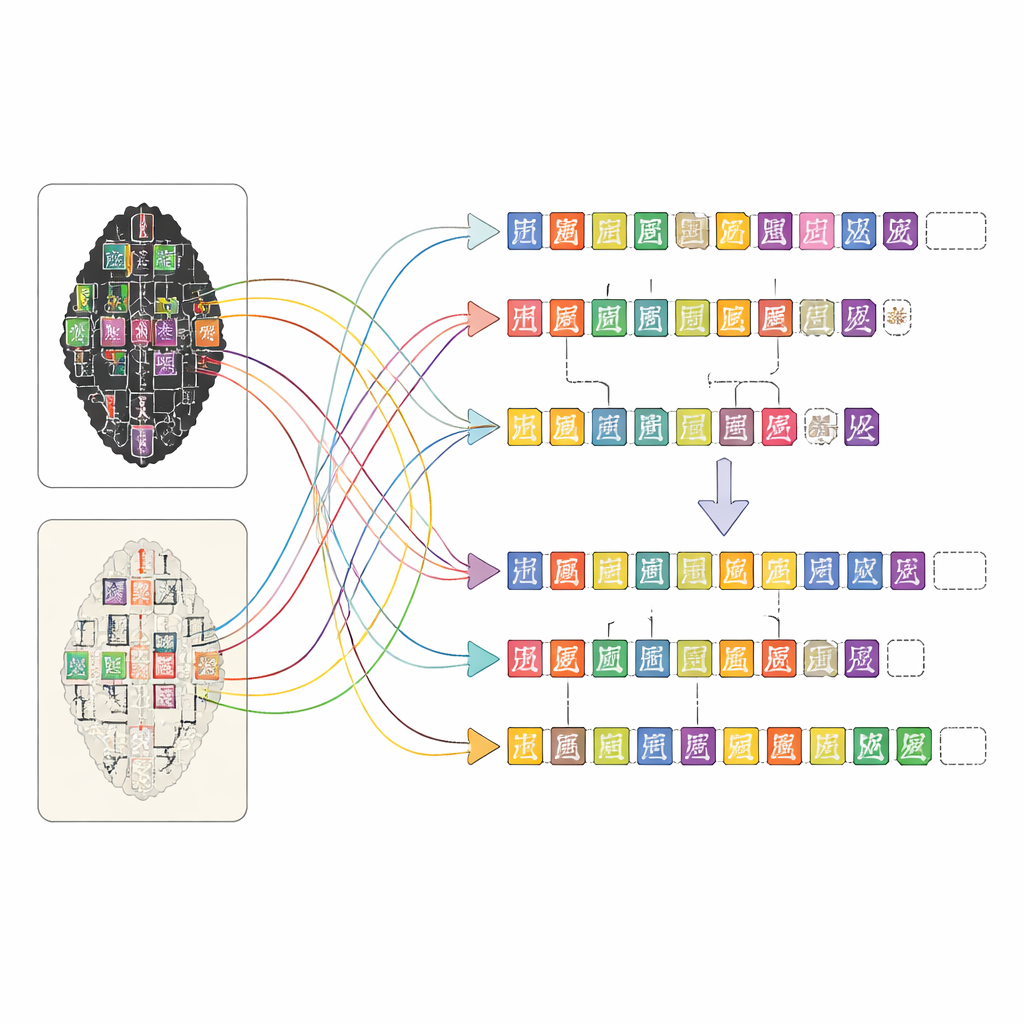
Menschliche Expertise und maschinelle Unterstützung kombinieren
Eine so detaillierte Karte für tausende komplexer Inschriften zu erstellen, wäre allein von Hand unmöglich. Das Team entwickelte eine webbasierte Plattform, die es Menschen mit unterschiedlichem Ausbildungsgrad erlaubt, effizient zusammenzuarbeiten. Zuerst scannen Computer-Vision-Tools die Abreibungs- und Facsimile-Bilder, um vorzuschlagen, wo Zeichen sein könnten und welchen Einträgen einer Spezialzeichenbibliothek sie ähneln. Dann verfeinern nicht-spezialisierte Annotatorinnen und Annotatoren diese Vorschläge, indem sie die Bilder vergleichen und gescannte Seiten mit Experten‑Transkriptionen konsultieren. Doktorandinnen und Doktoranden mit Ausbildung in Orakelknochenforschung überprüfen ihre Arbeit, und erfahrene Fachleute klären die schwierigen Fälle, etwa stark beschädigte Zeichen oder strittige Lesungen. Dieser mehrstufige Ansatz sichert hohe Qualität und macht die monumentale Aufgabe der Annotation handhabbar.
Computern das Lesen antiker Schrift beibringen
Um zu zeigen, was OBIMD ermöglicht, nutzten die Autorinnen und Autoren das Datenset, um moderne Machine‑Learning‑Modelle für mehrere Aufgaben zu trainieren und zu testen, die davon inspiriert sind, wie menschliche Expertinnen und Experten Knochen lesen. Ein Modell lernte, Zeichen direkt auf den Vollbildern zu lokalisieren und zu identifizieren, nicht nur auf vorab ausgeschnittenen Ausschnitten; es erzielte die besten Ergebnisse bei den saubereren Facsimile‑Zeichnungen und hatte die größten Schwierigkeiten mit subtilen Varianten in verrauschten Abreibungen. Ein anderes Modell lernte, Zeichen anhand ihrer Positionen und Formen zu Sätzen zu gruppieren, was meist gelang, aber weiterhin Grenzen verwechselte, wenn Textzeilen sich überlappten. Ein drittes Modell wurde darauf trainiert, die ursprüngliche Lesereihenfolge durcheinandergeratener Zeichen innerhalb eines Satzes wiederherzustellen, wobei es in den meisten Fällen die exakte Reihenfolge richtig vorhersagte und in vielen anderen nahe dran war. Zusammen zeigen diese Tests, dass OBIMD sowohl Fortschritt antreiben als auch die verbleibenden Herausforderungen beim automatischen Lesen antiker Schriften aufdecken kann.
Was das für unser Bild der Vergangenheit bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass OBIMD verstreute, fragile Spuren früher chinesischer Schrift in eine kohärente, computerlesbare Ressource verwandelt. Indem Bilder, Expertenzeichnungen und satzbezogene Lesungen zusammengeführt und sorgfältig markiert wird, was fehlt wie auch was überdauert hat, spiegelt das Datenset wider, wie Gelehrte tatsächlich Bedeutung aus beschädigten Artefakten zusammensetzen. Es öffnet die Tür zu groß angelegten Studien zu Sprachwandel, Schreibpraxis und königlichem Leben in der Shang‑Dynastie und bietet ein anspruchsvolles Testfeld für KI‑Systeme, die die Vergangenheit lesen wollen. Kurz: OBIMD ist keine Übersetzung der Orakelknochen, aber es ist die detaillierte Karte, die zukünftige Historikerinnen, Historiker und Algorithmen nutzen werden, um sie zu erkunden.
Zitation: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Schlüsselwörter: Orakelknochenschriften, antike Schrift, digitale Geisteswissenschaften, multimodales Datenset, KI-Texterkennung