Clear Sky Science · nl
OBIMD: Een multimodaal dataset voor contextuele interpretatie van orakelbeenderinscripties
Berichten ontsluiten uit oude beenderen
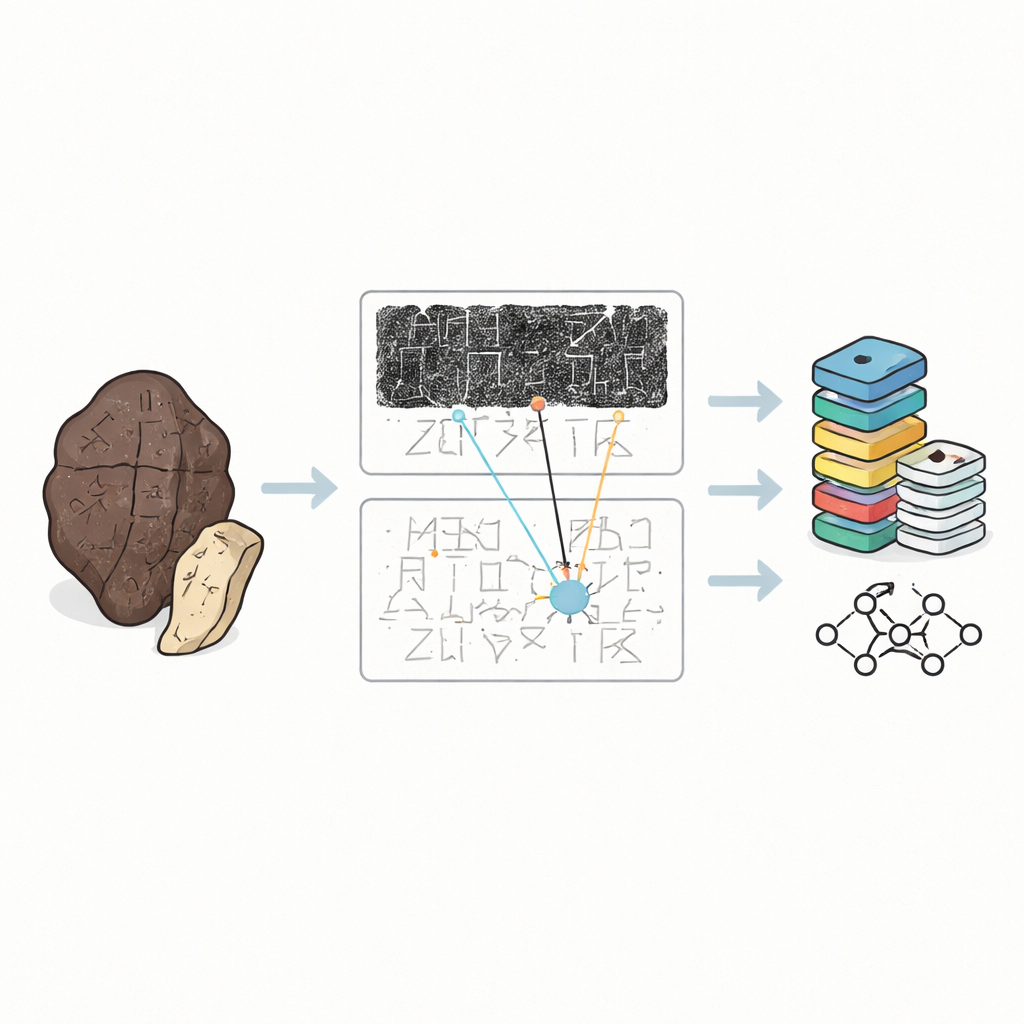
Meer dan drie millennia geleden kerfden koninklijke waarzeggers in China vragen aan de geesten in dierlijke botten en schildpaddenplaten en verhitten die tot ze barstten. Deze orakelbeenderen bewaren een van de vroegste volledige vormen van schrift ter wereld, maar ze zijn nu kwetsbare fragmenten verspreid over musea en boeken. Deze studie introduceert OBIMD, een nieuwe digitale collectie die beelden en deskundige lezingen van deze inscripties samenbrengt, en historici en computers een krachtig middel geeft om te bestuderen hoe dit oude schrift werkte en wat het ons vertelt over de vroeg-Chinese samenleving.
Waarom oude beenderen moeilijk leesbaar zijn
Orakelbeenderen zijn geen nette tekstpagina’s. Ze zijn afgebladderd, verbrand en vaak in stukken gebroken, waarbij het schrift zich om de gebogen oppervlakte slingert in verwarrende richtingen. Wetenschappers hanteren zelden de originelen. In plaats daarvan vertrouwen ze op drie soorten vervangers: donker met inkt genomen wrijfafdrukken van het oppervlak van het bot, met de hand getekende facsimiles die de streken verduidelijken, en gedrukte transcripties die laten zien hoe deskundigen denken dat de tekst gelezen moet worden. Tot nu toe behandelden de meeste digitale collecties afzonderlijk uitgesneden karakters uit wrijfafdrukken als geïsoleerde afbeeldingen. Dat is nuttig om computers vormen te leren herkennen, maar het negeert de bredere context die menselijke experts daadwerkelijk gebruiken om onduidelijke of beschadigde tekens te ontcijferen.
Een rijke digitale kaart van elk beschreven bot
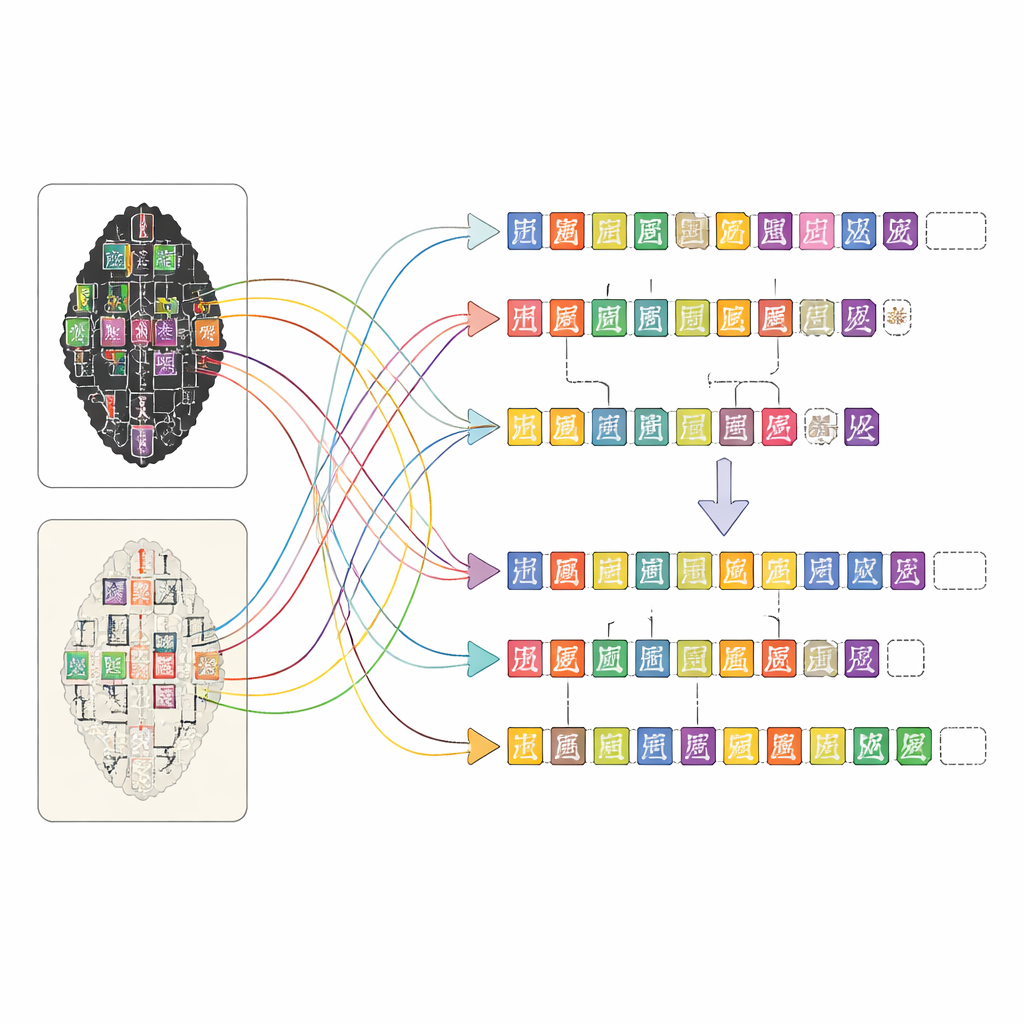
OBIMD verandert dat beeld door elk bot als een klein, gestructureerd wereldje op zich te behandelen. Voor meer dan tienduizend inscripties leveren de auteurs een bijpassende wrijving en facsimile-afbeelding, en markeren vervolgens de locatie van elk leesbaar karakter met een begrenzingsvak. Ze leggen ook plekken vast waar een karakter duidelijk ontbreekt omdat het bot is afgebroken, en plaatsen speciale lege vakken als plaatsaanduiders. Deze karakters en gaten worden gegroepeerd in zinnen of andere functionele eenheden, en de leesvolgorde — vaak cirkelend en niet-lineair — wordt expliciet in de data vastgelegd. Daardoor zegt de dataset niet alleen welke vormen op een bot voorkomen, maar ook hoe ze regels tekst vormen, welke volgorde ze volgen en waar de tekst verloren is gegaan.
Menselijke expertise combineren met machinehulp
Het maken van zo’n gedetailleerde kaart voor duizenden complexe inscripties zou niet haalbaar zijn met alleen handwerk. Het team ontwierp een webplatform waarmee mensen met verschillende niveaus van opleiding efficiënt kunnen samenwerken. Eerst scannen computer-vision-tools de wrijving- en facsimile-afbeeldingen om suggesties te doen waar karakters zouden kunnen staan en op welke ingangen uit een specialistische karakterbibliotheek ze lijken. Vervolgens verfijnen niet-specialistische annotatoren deze suggesties door de afbeeldingen te vergelijken en geraadpleegde pagina’s met deskundige transcripties te raadplegen. Promovendi met opleiding in orakelbeenstudies beoordelen hun werk, en ervaren experts beslissen in moeilijke gevallen, zoals sterk beschadigde tekens of betwiste lezingen. Deze gelaagde aanpak houdt de kwaliteit hoog en maakt de monumentale taak van annotatie beheersbaar.
Computers leren lezen van oud schrift
Om te laten zien wat OBIMD mogelijk maakt, gebruikten de auteurs het om moderne machine-learningmodellen te trainen en te testen op meerdere taken die geïnspireerd zijn door hoe menselijke experts botten lezen. Een model leerde karakters rechtstreeks op de volledige afbeeldingen te lokaliseren en identificeren, niet alleen op vooraf uitgeknipte stukjes, en presteerde het beste op de schonere facsimiletekeningen en het minst goed op subtiele varianten in lawaaierige wrijvingen. Een ander model leerde karakters op basis van hun positie en vorm in zinnen te groeperen, hetgeen meestal goed lukte maar nog foutjes gaf wanneer tekstlijnen overlappen. Een derde model werd getraind om de oorspronkelijke leesvolgorde van door elkaar geraakte karakters binnen een zin te herstellen, waarbij het in de meeste gevallen de exacte volgorde correct raadde en in veel andere gevallen dichtbij kwam. Samen tonen deze tests aan dat OBIMD zowel vooruitgang kan stimuleren als de resterende uitdagingen blootlegt in het automatisch lezen van oude schriftsystemen.
Wat dit betekent voor ons beeld van het verleden
Voor niet-specialisten is de kernboodschap dat OBIMD verspreide, kwetsbare sporen van vroeg-Chinees schrift verandert in een coherent, computerleesbaar hulpmiddel. Door afbeeldingen, deskundige tekeningen en zinsniveau-lezingen op elkaar af te stemmen, en zorgvuldig te markeren wat ontbreekt evenals wat bewaard is gebleven, weerspiegelt de dataset hoe menselijke onderzoekers daadwerkelijk betekenis reconstrueren uit beschadigde artefacten. Het opent de deur naar grootschalige studies van taalverandering, schrijverspraktijken en het koninklijke leven in de Shang-dynastie, en biedt een veeleisende testomgeving voor kunstmatige-intelligentiesystemen die het verleden willen lezen. Kortom: OBIMD is geen vertaling van orakelbeenderen, maar het is de gedetailleerde kaart die toekomstige historici en algoritmen zullen gebruiken om ze te verkennen.
Bronvermelding: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Trefwoorden: orakelbeenderinscripties, oud schrift, digitale humaniora, multimodale dataset, AI-tekstherkenning