Clear Sky Science · fr
OBIMD : un jeu de données multimodal pour l’interprétation contextuelle des inscriptions sur os d’oracle
Décoder les messages des os antiques
Il y a plus de trois millénaires, des devins royaux en Chine gravaient des questions aux esprits sur des os d’animaux et des carapaces de tortue, puis les chauffaient jusqu’à ce qu’elles se fissurent. Ces os d’oracle conservent une des plus anciennes écritures complètes au monde, mais aujourd’hui ils subsistent comme des fragments fragiles éparpillés dans des musées et des livres. Cette étude présente OBIMD, une nouvelle collection numérique qui rassemble images et lectures d’experts de ces inscriptions, offrant aux historiens comme aux ordinateurs un moyen puissant d’étudier le fonctionnement de cette écriture ancienne et ce qu’elle révèle sur la société chinoise primitive.
Pourquoi les vieux os sont difficiles à lire
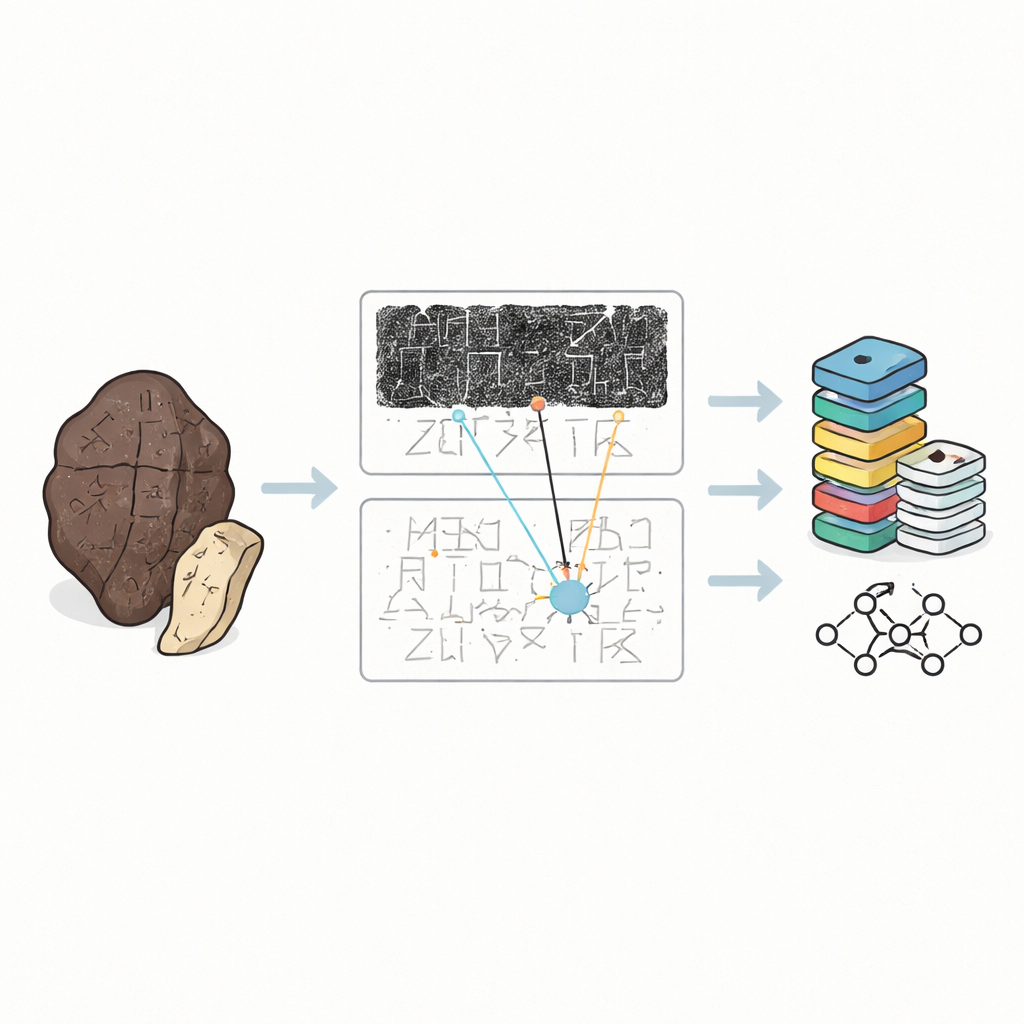
Les os d’oracle ne sont pas des pages de texte bien rangées. Ils sont ébréchés, brûlés et souvent cassés en morceaux, l’écriture serpentant autour de surfaces courbes dans des directions déroutantes. Les spécialistes manipulent rarement les originaux. Ils s’appuient plutôt sur trois types de substituts : des frottis à l’encre sombre pris sur la surface de l’os, des fac-similés dessinés à la main qui clarifient les traits, et des transcriptions imprimées montrant comment les experts pensent que le texte doit être lu. Jusqu’à présent, la plupart des collections numériques traitaient les caractères isolés extraits des frottis comme des images détachées. Cela sert à entraîner des machines à reconnaître des formes, mais ignore le contexte plus large que les experts humains utilisent réellement pour déchiffrer des signes obscurs ou endommagés.
Une carte numérique riche de chaque os inscrit
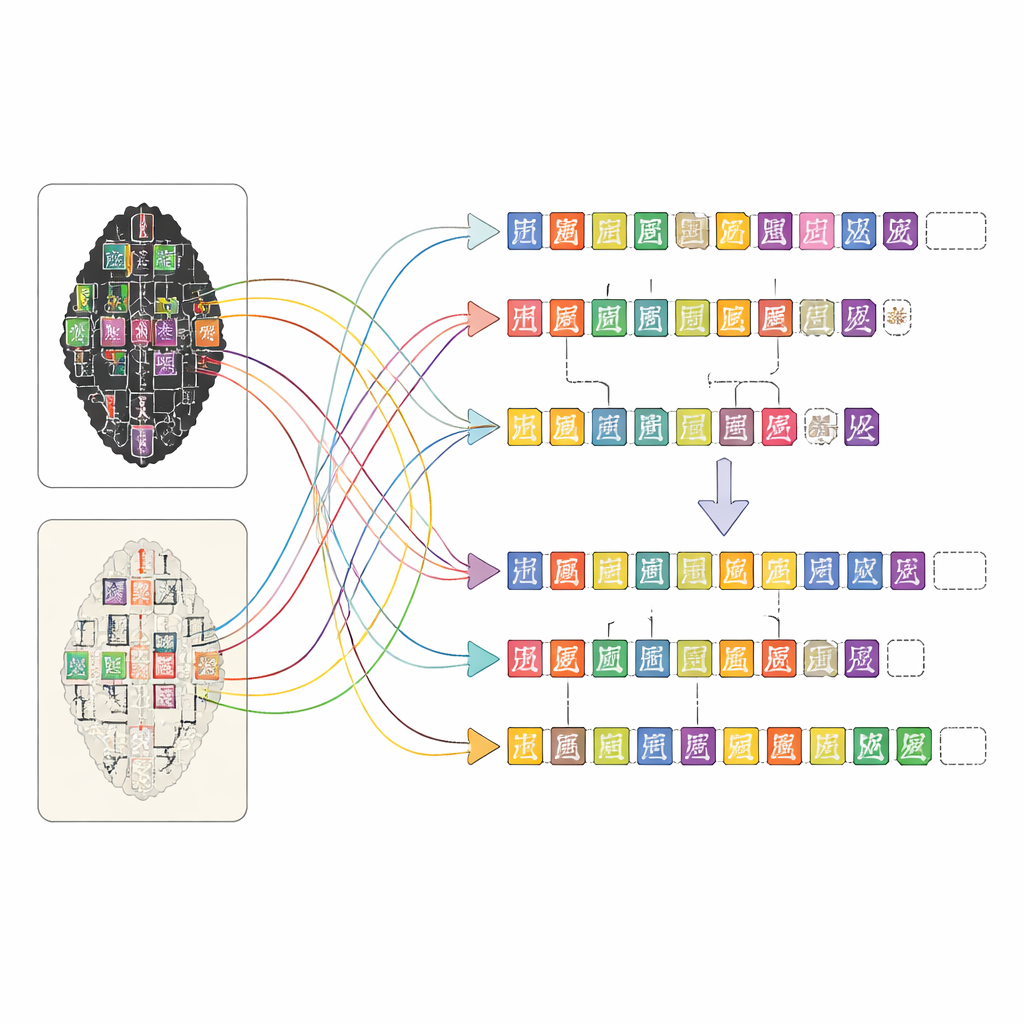
OBIMD change la donne en considérant chaque os comme un petit monde structuré à part entière. Pour plus de dix mille inscriptions, les auteurs fournissent une image de frottis et un fac-similé correspondants, puis marquent l’emplacement de chaque caractère lisible par une boîte englobante. Ils enregistrent aussi les endroits où un caractère manque clairement parce que l’os s’est détaché, en plaçant des boîtes vides spéciales comme espaces réservés. Ces caractères et lacunes sont regroupés en phrases ou en autres unités fonctionnelles, et l’ordre de lecture — souvent bouclé et non linéaire — est explicitement inscrit dans les données. En conséquence, le jeu de données n’indique pas seulement quelles formes apparaissent sur un os, mais aussi comment elles forment des lignes de texte, quelle séquence elles suivent et où le texte a été perdu.
Allier expertise humaine et aide mécanique
Construire une carte aussi détaillée pour des milliers d’inscriptions complexes serait impossible à la main seule. L’équipe a conçu une plateforme web qui permet à des personnes aux niveaux de formation variés de travailler ensemble efficacement. D’abord, des outils de vision par ordinateur analysent les images de frottis et de fac-similés pour suggérer où les caractères pourraient se trouver et à quelles entrées d’une bibliothèque spécialisée de signes ils ressemblent. Ensuite, des annotateurs non spécialistes affinent ces suggestions en comparant les images et en consultant des pages numérisées de transcriptions d’experts. Des doctorants formés aux études sur les os d’oracle révisent leur travail, et des spécialistes chevronnés tranchent les cas difficiles, comme les signes gravement abîmés ou les lectures contestées. Cette approche en couches maintient une haute qualité tout en rendant la tâche monumentale d’annotation gérable.
Apprendre aux ordinateurs à lire une écriture ancienne
Pour voir ce que permet OBIMD, les auteurs l’ont utilisé pour entraîner et tester des modèles modernes d’apprentissage automatique sur plusieurs tâches inspirées de la manière dont les experts humains lisent les os. Un modèle a appris à localiser et identifier des caractères directement sur les images complètes, pas seulement sur des fragments prédécoupés, donnant de meilleures performances sur les dessins fac-similés plus propres et peinant davantage face aux variantes subtiles des frottis bruités. Un autre modèle a appris à regrouper les caractères en phrases en se basant sur leur position et leur forme, réussissant pour la plupart mais confondant encore les limites lorsque les lignes de texte se chevaupaient. Un troisième modèle a été entraîné à restaurer l’ordre de lecture original de caractères en désordre au sein d’une phrase, devinant correctement l’ordre exact dans la plupart des cas et s’en approchant dans beaucoup d’autres. Ensemble, ces tests montrent qu’OBIMD peut à la fois stimuler le progrès et révéler les défis restants dans la lecture automatique des écritures anciennes.
Ce que cela change pour notre vision du passé
Pour les non-spécialistes, le message principal est que OBIMD transforme des traces éparses et fragiles de l’écriture chinoise ancienne en une ressource cohérente et lisible par ordinateur. En alignant images, dessins d’experts et lectures au niveau de la phrase, et en marquant soigneusement ce qui manque autant que ce qui subsiste, le jeu de données reflète la manière dont les chercheurs humains reconstituent réellement le sens à partir d’artefacts endommagés. Il ouvre la voie à des études à grande échelle sur l’évolution du langage, les pratiques scribales et la vie royale durant la dynastie Shang, et offre un banc d’essai exigeant pour les systèmes d’intelligence artificielle visant à lire le passé. En bref, OBIMD n’est pas une traduction des os d’oracle, mais c’est la carte détaillée que les historiens et algorithmes futurs utiliseront pour les explorer.
Citation: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Mots-clés: inscriptions sur os d’oracle, écriture ancienne, humanités numériques, jeu de données multimodal, reconnaissance de texte par IA