Clear Sky Science · sv
OBIMD: En multimodal datamängd för kontextuell tolkning av orakelbensinskrifter
Att låsa upp budskap från forntida ben
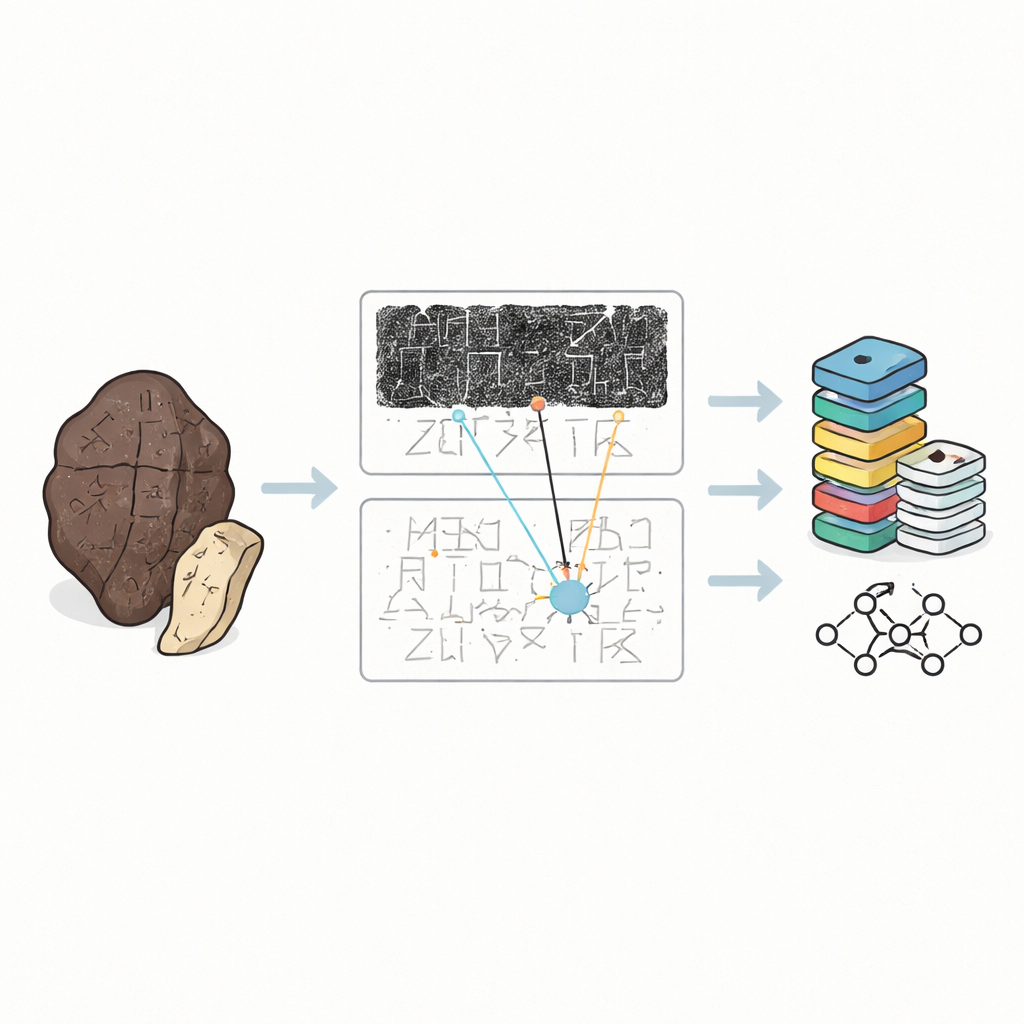
För drygt tre årtusenden sedan ristade kungliga spåmän i Kina frågor till andarna på djurben och sköldpaddsskal och värmde dem tills de sprack. Dessa orakelben bevarar några av världens tidigaste kompletta skriftfynd, men idag finns de kvar som sköra fragment spridda i museer och i tryckta samlingar. Den här studien introducerar OBIMD, en ny digital samling som förenar bilder och sakkunniga avläsningar av dessa inskrifter, och som ger både historiker och datorer ett kraftfullt verktyg för att studera hur denna forntida skrift fungerade och vad den kan berätta om det tidiga kinesiska samhället.
Varför gamla ben är svåra att läsa
Orakelben är inte prydliga textsidor. De är kantstötta, brända och ofta sönderslitna i bitar, med skriften som slingrar sig runt den böjda ytan i förvirrande riktningar. Forskare hanterar sällan originalen. Istället förlitar de sig på tre typer av ersättningar: mörka bläckade avtryck tagna från benytan, handritade facsimiler som klargör strecken, och tryckta transkriptioner som visar hur experter menar att texten bör läsas. Fram tills nu behandlade de flesta digitala samlingar enskilda tecken utskurna från avtryck som isolerade bilder. Det är användbart för att träna datorer att känna igen former, men förbiser den större kontext som mänskliga experter faktiskt använder för att tyda suddiga eller skadade tecken.
En rik digital karta över varje inskrivet ben
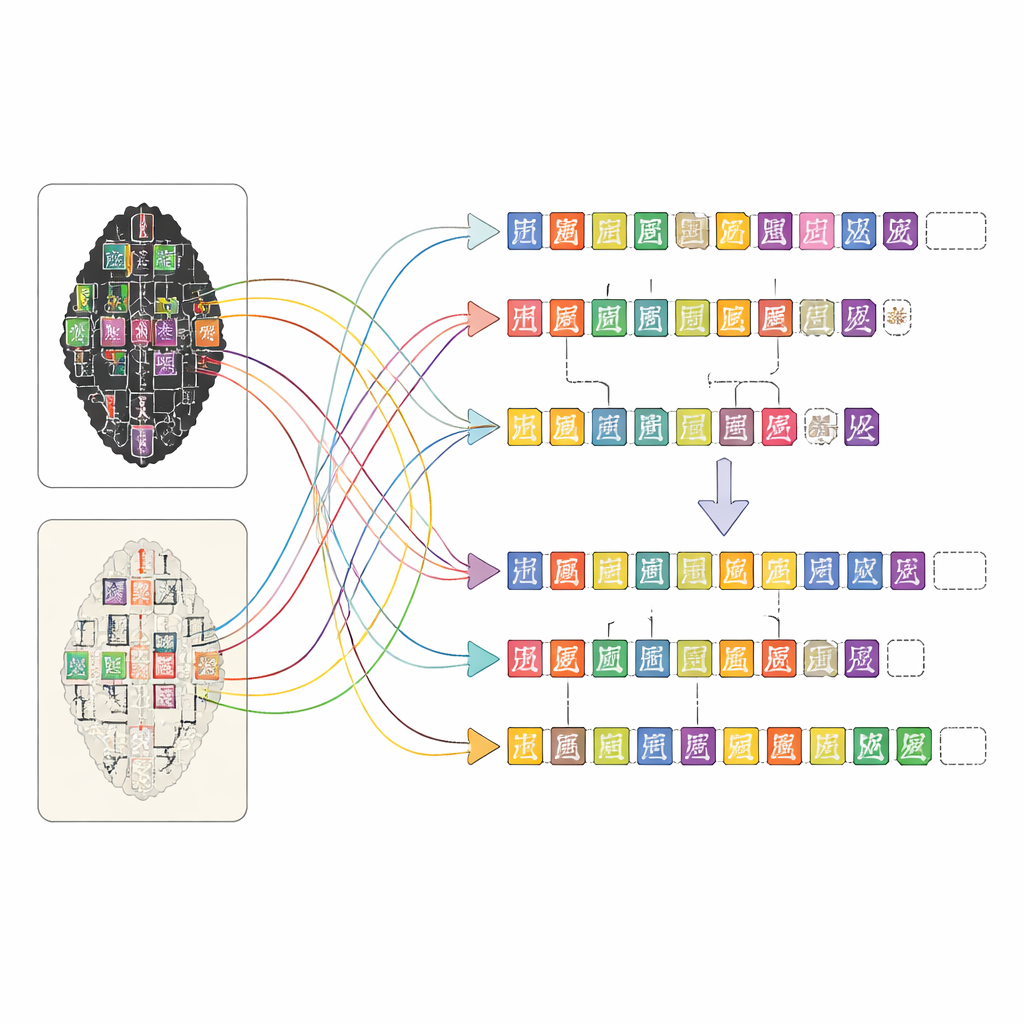
OBIMD förändrar bilden genom att behandla varje ben som en liten, strukturerad värld i sig. För mer än tiotusen inskrifter tillhandahåller författarna en matchande avtrycks- och facsimilebild, och markerar sedan varje läsbart teckens plats med en avgränsningsruta. De registrerar också platser där ett tecken tydligt fattas därför att benet har gått förlorat, genom att lägga särskilda tomma rutor som platshållare. Dessa tecken och luckor grupperas i meningar eller andra funktionella enheter, och läsordningen — ofta slingrande och icke-linjär — skrivs uttryckligen in i datan. Som en följd säger datamängden inte bara vilka former som syns på ett ben, utan också hur de bildar textlinjer, i vilken sekvens de följer varandra, och var texten har gått förlorad.
Kombinera mänsklig expertis och maskinhjälp
Att bygga en sådan detaljerad karta för tusentals komplexa inskrifter vore omöjligt för hand ensam. Teamet designade en webbaserad plattform som låter personer med olika utbildningsnivåer arbeta tillsammans effektivt. Först skannar datorseendet verktyg avtrycks- och facsimilebilderna för att föreslå var tecken kan finnas och vilka poster i ett specialistteckensbibliotek de liknar. Sedan förfinar icke-specialiserade annotatörer dessa förslag genom att jämföra bilderna och konsultera skannade sidor av experttranskriptioner. Doktorandstudenter med träning i orakelbensstudier granskar deras arbete, och erfarna experter avgör de svåra fallen, såsom kraftigt skadade tecken eller omtvistade avläsningar. Detta flerstegsförfarande håller kvaliteten hög samtidigt som det gör den monumentala annoteringsuppgiften hanterbar.
Att lära datorer läsa forntida skrift
För att visa vad OBIMD möjliggör använde författarna den för att träna och testa moderna maskininlärningsmodeller på flera uppgifter inspirerade av hur mänskliga experter läser benen. En modell lärde sig att lokalisera och identifiera tecken direkt på fulla bilder, inte bara på förut utskurna utsnitt, och presterade bäst på de renare facsimilerna samtidigt som den hade svårast för subtila varianter i brusiga avtryck. En annan modell lärde sig att gruppera tecken till meningar baserat på deras positioner och former, vilket mestadels lyckades men fortfarande blandade ihop gränser när textlinjer överlappade. En tredje modell tränades att återställa den ursprungliga läsordningen för hopblandade tecken inom en mening, och gissade korrekt den exakta ordningen i de flesta fall och kom nära i många andra. Tillsammans visar dessa tester att OBIMD både kan driva framsteg och blottlägga de kvarstående utmaningarna i automatisk läsning av forntida skriftsystem.
Vad detta betyder för vår bild av det förflutna
För icke-specialister är huvudbudskapet att OBIMD förvandlar spridda, sköra spår av tidig kinesisk skrift till en sammanhängande, datorläsbar resurs. Genom att alignera bilder, expertteckningar och meningnivå-avläsningar, och genom att noggrant markera vad som saknas såväl som vad som bevarats, speglar datamängden hur mänskliga forskare faktiskt pusslar samman mening ur skadade artefakter. Den öppnar dörren för storskaliga studier av språkutveckling, skrivpraxis och kungligt liv under Shangdynastin, och erbjuder ett krävande testfält för artificiella intelligenssystem som siktar på att läsa det förflutna. Kort sagt: OBIMD är inte en översättning av orakelbenen, men det är den detaljerade kartan som framtida historiker och algoritmer kommer att använda för att utforska dem.
Citering: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Nyckelord: orakelbensinskrifter, forntida skrift, digital humaniora, multimodal datamängd, AI-textigenkänning