Clear Sky Science · it
OBIMD: Un dataset multimodale per l’interpretazione contestuale delle iscrizioni su ossa oracolari
Decifrare i messaggi dalle ossa antiche
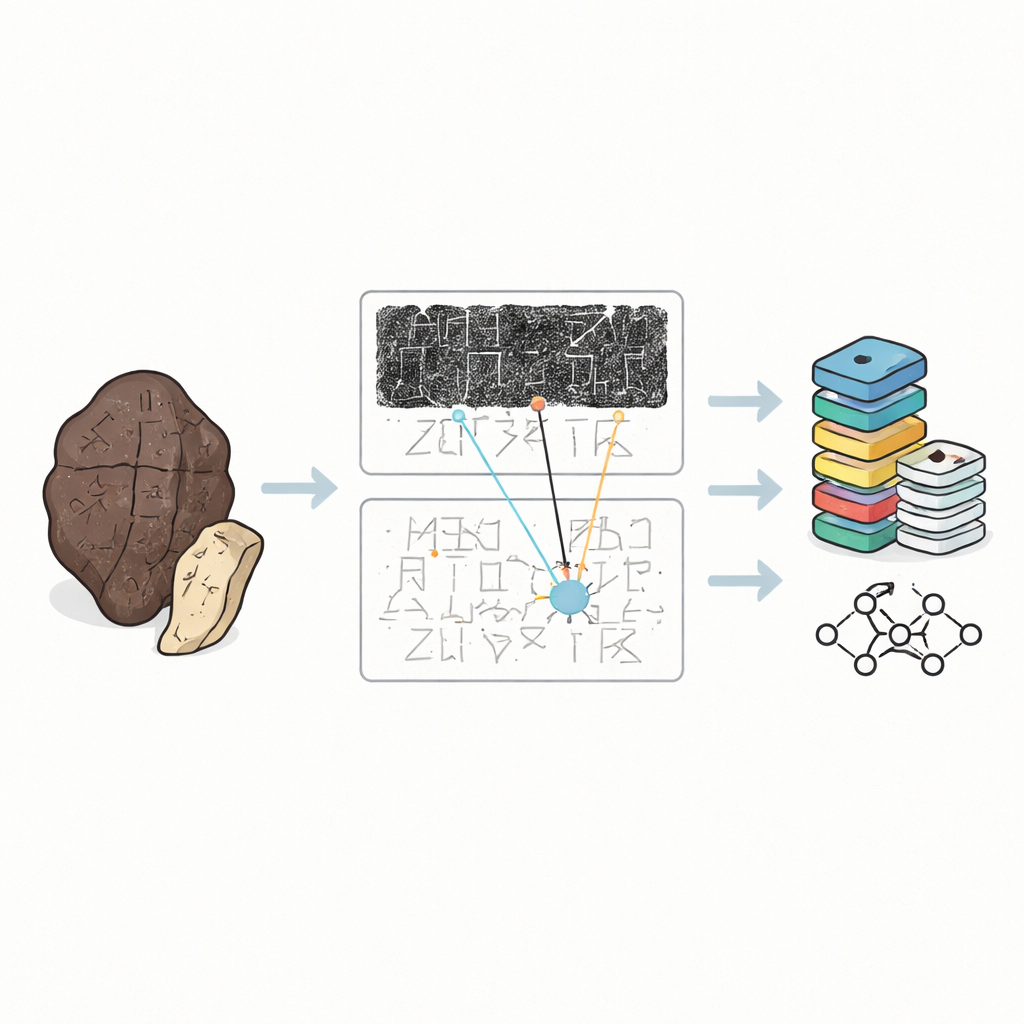
Più di tremila anni fa, i divinatori reali in Cina incidevano domande agli spiriti su ossa di animali e gusci di tartaruga, poi li riscaldavano finché non si crepavano. Queste ossa oracolari conservano alcune delle prime scritture complete al mondo, ma oggi sopravvivono come frammenti fragili sparsi in musei e libri. Questo studio presenta OBIMD, una nuova collezione digitale che riunisce immagini e trascrizioni di esperti di queste iscrizioni, offrendo a storici e computer uno strumento potente per studiare come funzionava questo antico sistema di scrittura e cosa rivela sulla società cinese primitiva.
Perché le ossa antiche sono difficili da leggere
Le ossa oracolari non sono pagine di testo ordinate. Sono scheggiate, bruciate e spesso rotte in più pezzi, con la scrittura che si avvolge intorno a superfici curve in direzioni spesso enigmatiche. Gli studiosi raramente maneggiano gli originali. Si basano invece su tre tipi di sostituti: frotti oscuri presi dalla superficie dell’osso, facsimili disegnati a mano che chiariscono i tratti, e trascrizioni stampate che mostrano come gli esperti ritengono che il testo debba essere letto. Finora, la maggior parte delle raccolte digitali trattava i singoli caratteri ritagliati dai frotti come immagini isolate. Questo è utile per addestrare i computer a riconoscere forme, ma ignora il contesto più ampio che gli esperti umani usano realmente per decifrare segni poco chiari o danneggiati.
Una mappa digitale ricca per ogni osso inciso
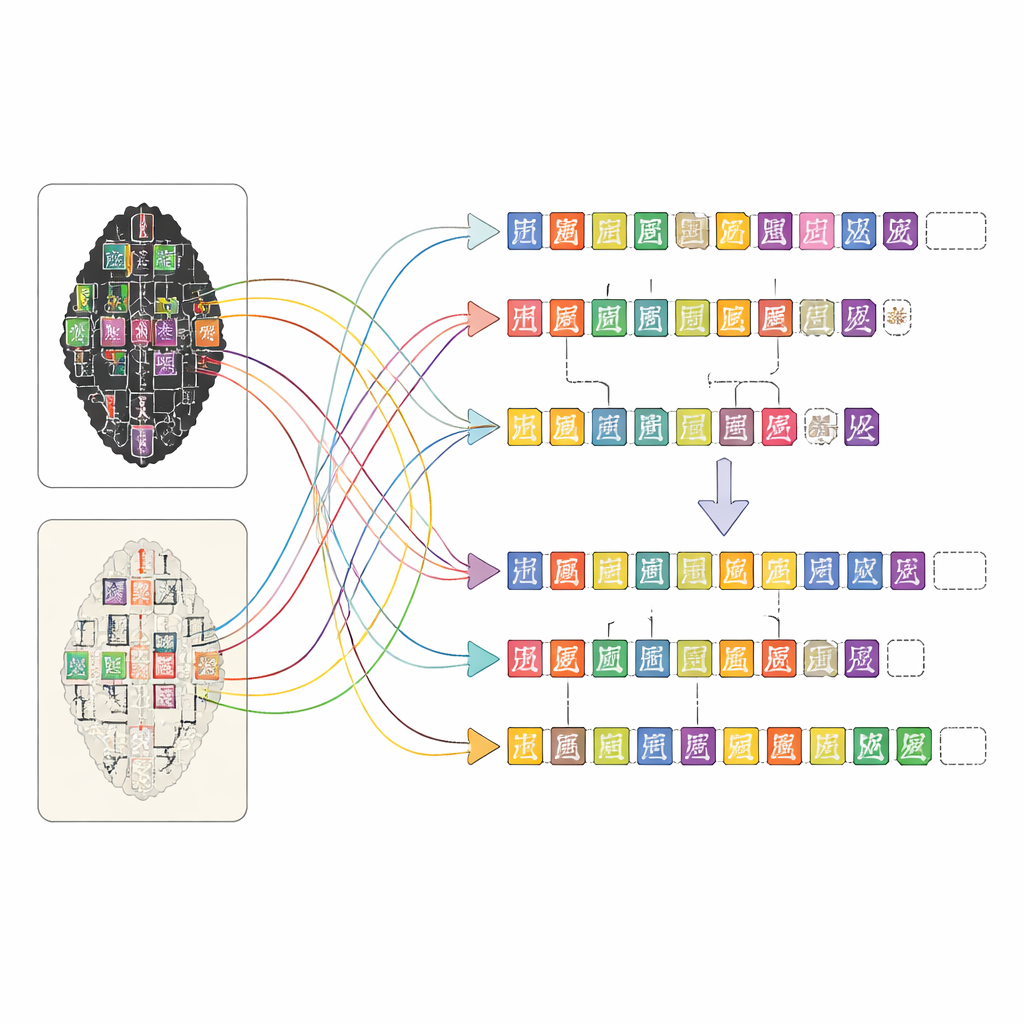
OBIMD cambia questa prospettiva trattando ogni osso come un piccolo mondo strutturato a sé. Per oltre diecimila iscrizioni, gli autori forniscono un frottis e un’immagine facsimile corrispondenti, e segnano la posizione di ogni carattere leggibile con una casella di delimitazione. Registrano anche i punti in cui un carattere manca chiaramente perché l’osso si è spezzato, posizionando apposite caselle vuote come segnaposto. Questi caratteri e lacune sono raggruppati in frasi o altre unità funzionali, e l’ordine di lettura — spesso circolare e non lineare — è esplicitamente scritto nei dati. Di conseguenza, il dataset non si limita a indicare quali forme compaiono su un osso, ma mostra anche come formano linee di testo, quale sequenza seguono e dove il testo è andato perduto.
Combinare competenza umana e aiuto delle macchine
Costruire una mappa così dettagliata per migliaia di iscrizioni complesse sarebbe impossibile solo a mano. Il team ha progettato una piattaforma web che permette a persone con diversi livelli di formazione di lavorare insieme in modo efficiente. Prima, strumenti di visione artificiale analizzano le immagini di frottis e facsimili per suggerire dove potrebbero trovarsi i caratteri e a quali voci di una libreria specialistica di caratteri somigliano. Poi annotatori non specialisti perfezionano questi suggerimenti confrontando le immagini e consultando pagine scansionate di trascrizioni di esperti. Studenti laureandi con formazione nello studio delle ossa oracolari revisionano il lavoro e specialisti esperti risolvono i casi difficili, come segni gravemente danneggiati o letture controverse. Questo approccio stratificato mantiene alta la qualità rendendo al contempo gestibile l’enorme compito di annotazione.
Insegnare ai computer a leggere la scrittura antica
Per mostrare cosa abilita OBIMD, gli autori lo hanno usato per addestrare e testare modelli di machine learning moderni su diversi compiti ispirati a come gli esperti umani leggono le ossa. Un modello ha imparato a localizzare e identificare i caratteri direttamente sulle immagini complete, non solo su ritagli predefiniti, ottenendo le migliori prestazioni sui disegni facsimili più puliti e incontrando maggiori difficoltà con varianti sottili nei frottis rumorosi. Un altro modello ha imparato a raggruppare i caratteri in frasi in base alle loro posizioni e forme, riuscendo per lo più nell’intento ma confondendo ancora i confini quando le linee di testo si sovrapponevano. Un terzo modello è stato addestrato a ripristinare l’ordine di lettura originale di caratteri disordinati all’interno di una frase, indovinando correttamente l’ordine esatto nella maggior parte dei casi e avvicinandosi in molti altri. Insieme, questi test mostrano che OBIMD può sia stimolare il progresso sia mettere in luce le sfide rimaste nella lettura automatica delle scritture antiche.
Cosa significa per la nostra immagine del passato
Per i non specialisti, il messaggio principale è che OBIMD trasforma tracce frammentarie e fragili della scrittura cinese primitiva in una risorsa coerente e leggibile dalle macchine. Allineando immagini, disegni di esperti e letture a livello di frase, e segnando con cura ciò che manca tanto quanto ciò che sopravvive, il dataset rispecchia il modo in cui gli studiosi umani ricompongono il significato da manufatti danneggiati. Apre la strada a studi su larga scala sui cambiamenti linguistici, sulle pratiche degli scribi e sulla vita reale nella dinastia Shang, e offre un banco di prova esigente per sistemi di intelligenza artificiale che mirano a leggere il passato. In breve, OBIMD non è una traduzione delle ossa oracolari, ma è la mappa dettagliata che storici e algoritmi futuri useranno per esplorarle.
Citazione: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Parole chiave: iscrizioni su ossa oracolari, scrittura antica, umanities digitali, dataset multimodale, riconoscimento testuale AI