Clear Sky Science · es
OBIMD: Un conjunto de datos multimodal para la interpretación contextual de las inscripciones sobre huesos oraculares
Descifrando mensajes de huesos antiguos
Hace más de tres milenios, los adivinos reales en China grababan preguntas a los espíritus sobre huesos de animal y caparazones de tortuga, y luego los calentaban hasta que se agrietaban. Estos huesos oraculares conservan parte de la escritura plena más antigua del mundo, pero hoy sobreviven como frágiles fragmentos dispersos por museos y libros. Este estudio presenta OBIMD, una nueva colección digital que reúne imágenes y lecturas de expertos de estas inscripciones, ofreciendo a historiadores y ordenadores por igual una herramienta poderosa para estudiar cómo funcionaba esta escritura antigua y qué revela sobre la sociedad china temprana.
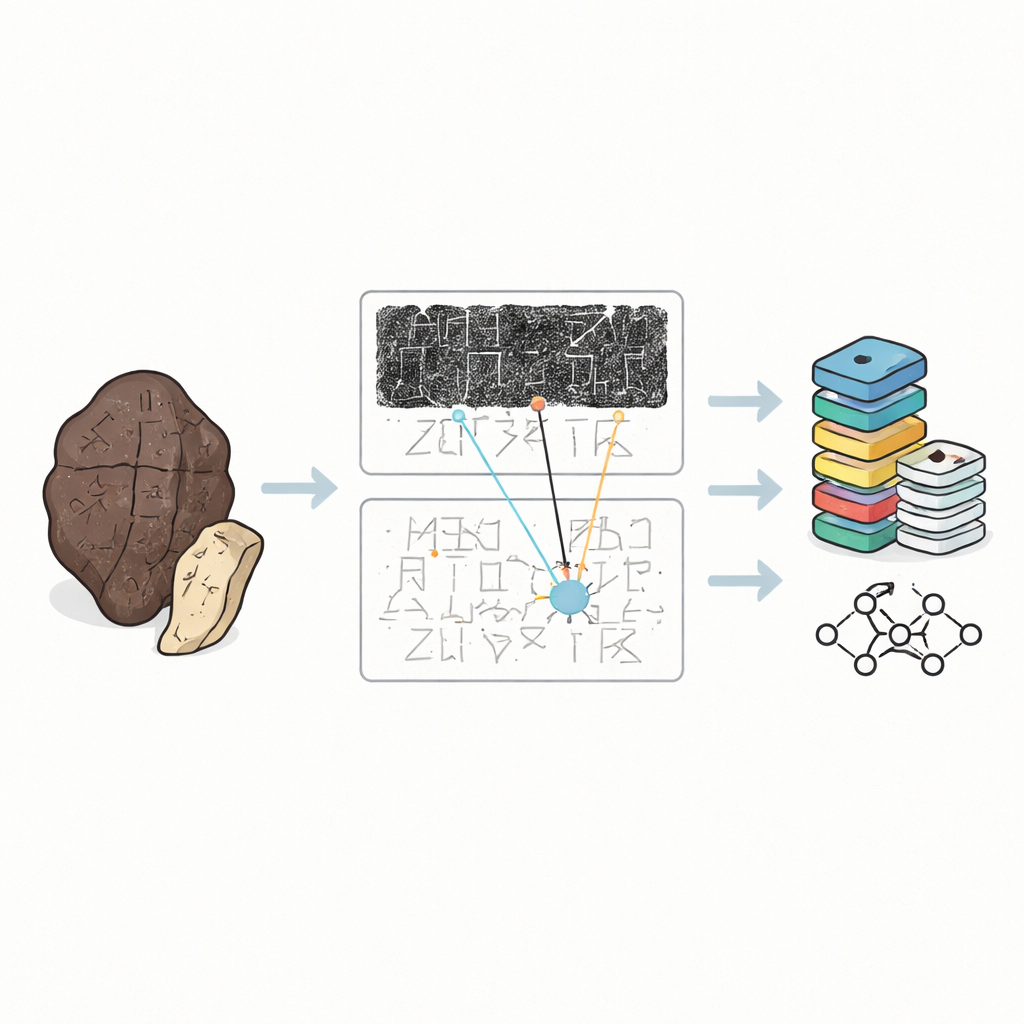
Por qué es difícil leer los huesos antiguos
Los huesos oraculares no son páginas ordenadas de texto. Están astillados, quemados y a menudo partidos en trozos, con la escritura serpenteando por la superficie curva en direcciones desconcertantes. Los especialistas rara vez manipulan los originales. En su lugar, se apoyan en tres tipos de sustitutos: frottages entintados tomados de la superficie del hueso, facsímiles dibujados a mano que aclaran los trazos, y transcripciones impresas que muestran cómo los expertos piensan que debe leerse el texto. Hasta ahora, la mayoría de las colecciones digitales trataban caracteres individuales recortados de los frottages como imágenes aisladas. Eso es útil para entrenar ordenadores a reconocer formas, pero ignora el contexto más amplio que los expertos humanos realmente usan para descifrar signos poco claros o dañados.
Un mapa digital rico de cada hueso inscrito
OBIMD cambia esta perspectiva tratando cada hueso como un pequeño mundo estructurado por sí mismo. Para más de diez mil inscripciones, los autores proporcionan una imagen emparejada de frottage y facsímil, y luego marcan la ubicación de cada carácter legible con una caja delimitadora. También registran lugares donde un carácter falta claramente porque el hueso se ha desprendido, colocando cajas vacías especiales como marcadores. Estos caracteres y huecos se agrupan en oraciones u otras unidades funcionales, y el orden de lectura —a menudo en bucle y no lineal— se escribe explícitamente en los datos. Como resultado, el conjunto de datos no solo dice qué formas aparecen en un hueso, sino también cómo forman líneas de texto, qué secuencia siguen y dónde se ha perdido el texto.
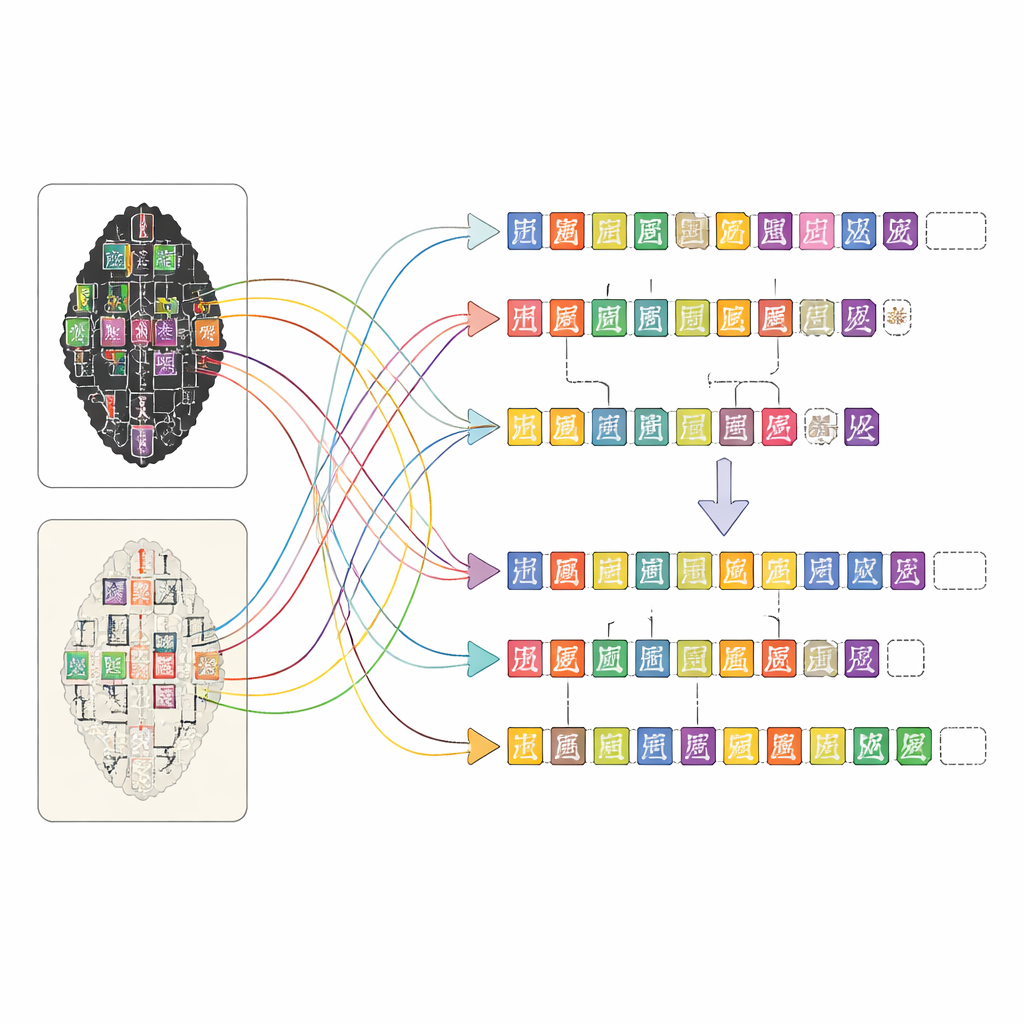
Combinando la pericia humana y la ayuda de las máquinas
Construir un mapa tan detallado para miles de inscripciones complejas sería imposible solo a mano. El equipo diseñó una plataforma web que permite que personas con distintos niveles de formación trabajen juntas de manera eficiente. Primero, herramientas de visión por ordenador escanean las imágenes de frottage y facsímil para sugerir dónde podrían estar los caracteres y a qué entradas de una biblioteca especializada de caracteres se parecen. Luego, anotadores no especialistas refinan estas sugerencias comparando las imágenes y consultando páginas escaneadas de transcripciones de expertos. Estudiantes de posgrado con formación en estudios sobre huesos oraculares revisan su trabajo, y expertos veteranos resuelven los casos difíciles, como signos muy dañados o lecturas disputadas. Este enfoque por capas mantiene alta la calidad a la vez que hace manejable la monumental tarea de anotación.
Enseñar a las máquinas a leer escrituras antiguas
Para ver lo que permite OBIMD, los autores lo usaron para entrenar y evaluar modelos modernos de aprendizaje automático en varias tareas inspiradas en cómo los expertos humanos leen los huesos. Un modelo aprendió a localizar e identificar caracteres directamente en las imágenes completas, no solo en parches recortados, obteniendo mejores resultados en los dibujos facsímiles más limpios y teniendo más dificultades con variantes sutiles en los frottages ruidosos. Otro modelo aprendió a agrupar caracteres en oraciones según sus posiciones y formas, teniendo éxito en su mayoría pero todavía confundiendo límites cuando las líneas de texto se superponían. Un tercer modelo fue entrenado para restaurar el orden de lectura original de caracteres desordenados dentro de una oración, adivinando correctamente el orden exacto en la mayoría de los casos y aproximándose en muchos otros. En conjunto, estas pruebas muestran que OBIMD puede tanto impulsar el progreso como revelar los desafíos pendientes en la lectura automática de escrituras antiguas.
Qué significa esto para nuestra visión del pasado
Para los no especialistas, el mensaje clave es que OBIMD convierte los restos dispersos y frágiles de la escritura china temprana en un recurso coherente y legible por ordenador. Al alinear imágenes, dibujos de expertos y lecturas a nivel de oración, y al marcar con cuidado lo que falta además de lo que sobrevive, el conjunto de datos refleja cómo los estudiosos humanos reconstruyen el significado a partir de artefactos dañados. Abre la puerta a estudios a gran escala sobre el cambio lingüístico, las prácticas de los escribas y la vida real en la dinastía Shang, y ofrece un banco de pruebas exigente para sistemas de inteligencia artificial que aspiran a leer el pasado. En resumen, OBIMD no es una traducción de los huesos oraculares, pero sí es el mapa detallado que los futuros historiadores y algoritmos usarán para explorarlos.
Cita: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Palabras clave: inscripciones sobre huesos oraculares, escritura antigua, humanidades digitales, conjunto de datos multimodal, reconocimiento de texto por IA