Clear Sky Science · pt
OBIMD: Um Conjunto de Dados Multimodal para Interpretação Contextual de Inscrições em Ossos Oraculares
Decodificando Mensagens de Ossos Milenares
Há mais de três mil anos, adivinhos da corte na China gravavam perguntas aos espíritos em ossos de animais e em carapaças de tartaruga e, em seguida, aqueciam-nos até que rachassem. Esses ossos oraculares preservam parte das formas mais antigas de escrita completa do mundo, mas hoje sobrevivem como fragmentos frágeis espalhados por museus e livros. Este estudo apresenta o OBIMD, uma nova coleção digital que reúne imagens e leituras de especialistas dessas inscrições, oferecendo a historiadores e a computadores uma ferramenta poderosa para estudar como esse sistema de escrita funcionava e o que revela sobre a sociedade chinesa antiga.
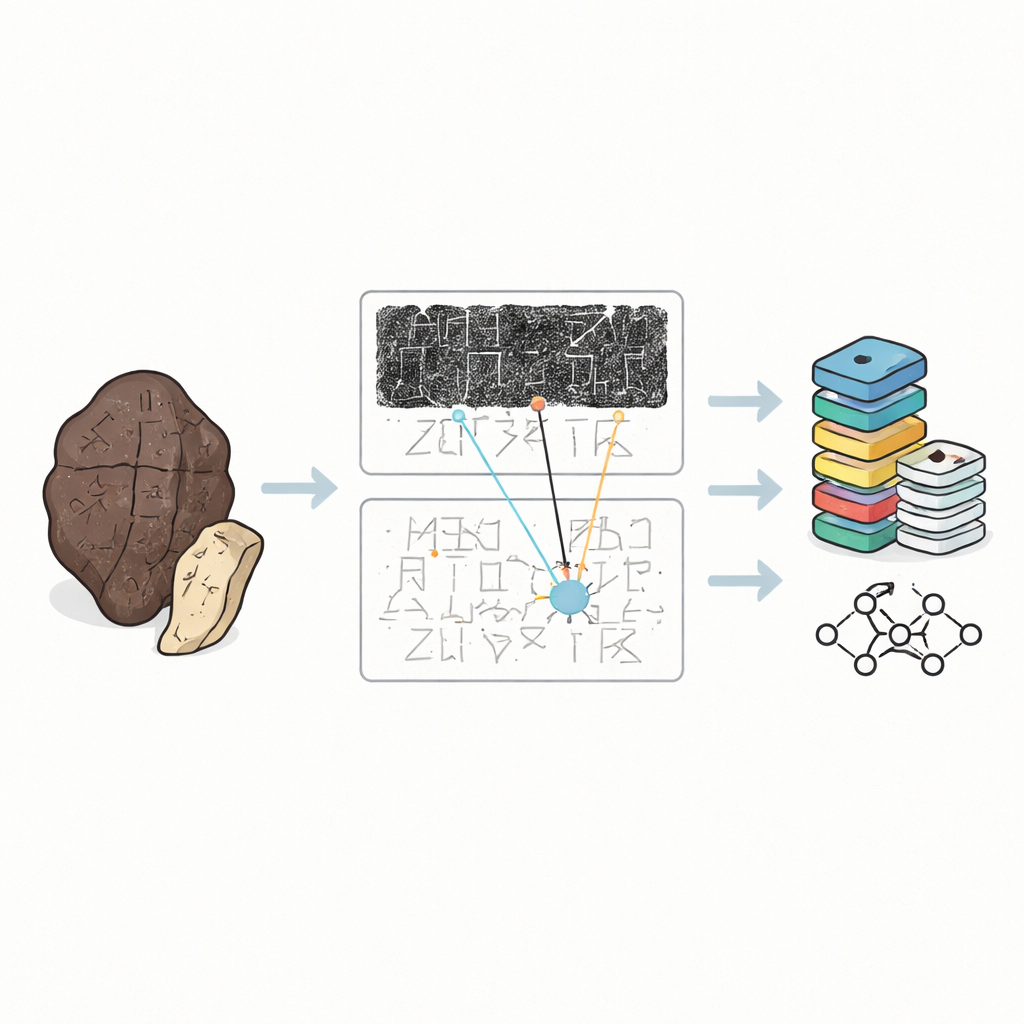
Por que Ossos Antigos São Difíceis de Ler
Ossos oraculares não são páginas organizadas de texto. Eles estão lascados, queimados e frequentemente quebrados em pedaços, com a escrita contornando superfícies curvas em direções desconcertantes. Os estudiosos raramente manuseiam os originais. Em vez disso, dependem de três tipos de substitutos: estampagens em tinta escura feitas a partir da superfície do osso, fac-símiles desenhados à mão que clarificam os traços e transcrições impressas que mostram como os especialistas acreditam que o texto deve ser lido. Até agora, a maioria das coleções digitais tratava caracteres isolados recortados de estampagens como imagens individuais. Isso é útil para treinar computadores a reconhecer formas, mas ignora o contexto maior que especialistas humanos realmente usam para decifrar sinais pouco claros ou danificados.
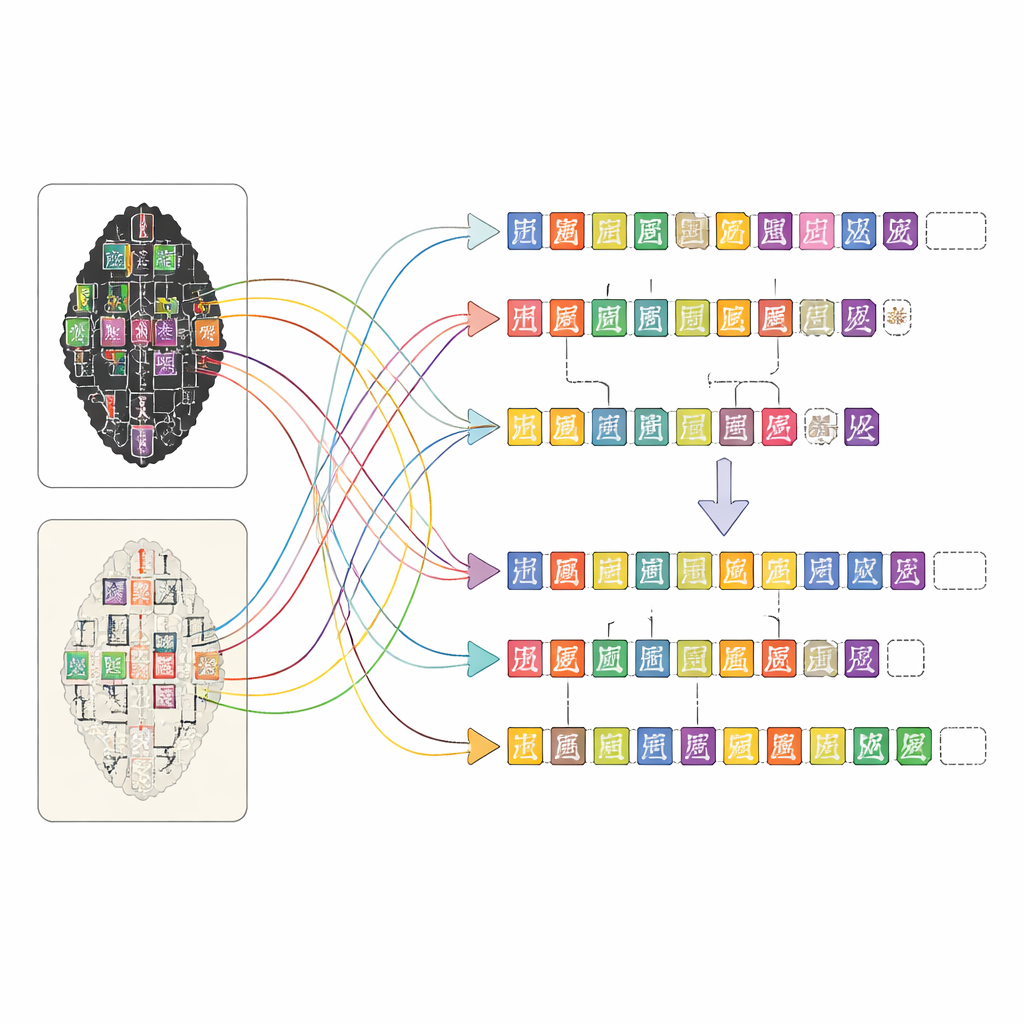
Um Mapa Digital Rico de Cada Osso Inscrito
O OBIMD muda essa perspectiva ao tratar cada osso como um pequeno mundo estruturado. Para mais de dez mil inscrições, os autores fornecem uma estampagem correspondente e uma imagem fac-símile, e então marcam a localização de cada caráter legível com uma caixa delimitadora. Também registram pontos onde um caráter está claramente ausente porque o osso se quebrou, colocando caixas vazias especiais como marcadores. Esses caracteres e lacunas são agrupados em sentenças ou outras unidades funcionais, e a ordem de leitura — frequentemente em loop e não-linear — é explicitamente escrita nos dados. Como resultado, o conjunto de dados não apenas indica quais formas aparecem em um osso, mas também como elas formam linhas de texto, qual sequência seguem e onde o texto foi perdido.
Combinando Conhecimento Humano e Ajuda da Máquina
Construir um mapa tão detalhado para milhares de inscrições complexas seria impossível apenas manualmente. A equipe projetou uma plataforma web que permite que pessoas com diferentes níveis de treinamento trabalhem juntas de forma eficiente. Primeiro, ferramentas de visão computacional analisam as imagens de estampagem e fac-símile para sugerir onde os caracteres podem estar e a quais entradas de uma biblioteca especializada de caracteres eles se assemelham. Em seguida, anotadores não especialistas refinam essas sugestões comparando as imagens e consultando páginas digitalizadas de transcrições de especialistas. Estudantes de pós-graduação com formação em estudos de ossos oraculares revisam o trabalho, e especialistas experientes resolvem os casos difíceis, como sinais muito danificados ou leituras contestadas. Essa abordagem em camadas mantém a qualidade alta enquanto torna a tarefa monumental de anotação administrável.
Ensinando Computadores a Ler Escritas Antigas
Para demonstrar o que o OBIMD possibilita, os autores o usaram para treinar e testar modelos modernos de aprendizado de máquina em várias tarefas inspiradas em como especialistas humanos leem os ossos. Um modelo aprendeu a localizar e identificar caracteres diretamente nas imagens completas, não apenas em recortes pré-cortados, obtendo melhor desempenho nos desenhos fac-símile mais limpos e tendo mais dificuldade com variantes sutis em estampagens ruidosas. Outro modelo aprendeu a agrupar caracteres em sentenças com base em suas posições e formas, conseguindo em grande parte mas ainda confundindo limites quando linhas de texto se sobrepunham. Um terceiro modelo foi treinado para restaurar a ordem original de leitura de caracteres embaralhados dentro de uma sentença, acertando a ordem exata na maioria dos casos e chegando perto em muitos outros. Juntos, esses testes mostram que o OBIMD pode impulsionar o progresso e expor os desafios remanescentes na leitura automática de escritas antigas.
O Que Isso Significa para Nossa Visão do Passado
Para não especialistas, a mensagem principal é que o OBIMD transforma vestígios dispersos e frágeis da escrita chinesa antiga em um recurso coerente e legível por computador. Ao alinhar imagens, desenhos de especialistas e leituras em nível de sentença, e ao marcar cuidadosamente o que está faltando além do que sobreviveu, o conjunto de dados espelha como os estudiosos humanos realmente juntam sentido a partir de artefatos danificados. Ele abre a porta para estudos em grande escala sobre mudança linguística, prática de escribas e vida real na dinastia Shang, e oferece um campo de testes exigente para sistemas de inteligência artificial que visam ler o passado. Em suma, o OBIMD não é uma tradução dos ossos oraculares, mas é o mapa detalhado que futuros historiadores e algoritmos usarão para explorá-los.
Citação: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Palavras-chave: inscrições em ossos oraculares, escrita antiga, humanidades digitais, conjunto de dados multimodal, reconhecimento de texto por IA