Clear Sky Science · ru
OBIMD: Мультимодальный набор данных для контекстной интерпретации надписей на гадательных костях
Расшифровывая послания с древних костей
Более трёх тысяч лет назад царские гадатели в Китае вырезали вопросы духам на костях животных и панцирях черепах, а затем нагревали их до появления трещин. Эти гадательные кости сохраняют одни из самых ранних полных вариантов письма в мире, но сегодня они дошли до нас в виде хрупких фрагментов, разбросанных по музеям и книгам. В этом исследовании представлен OBIMD — новая цифровая коллекция, которая собирает вместе изображения и экспертные чтения этих надписей, предоставляя историкам и компьютерам мощный инструмент для изучения того, как работал этот древний шрифт и что он сообщает о раннем китайском обществе.
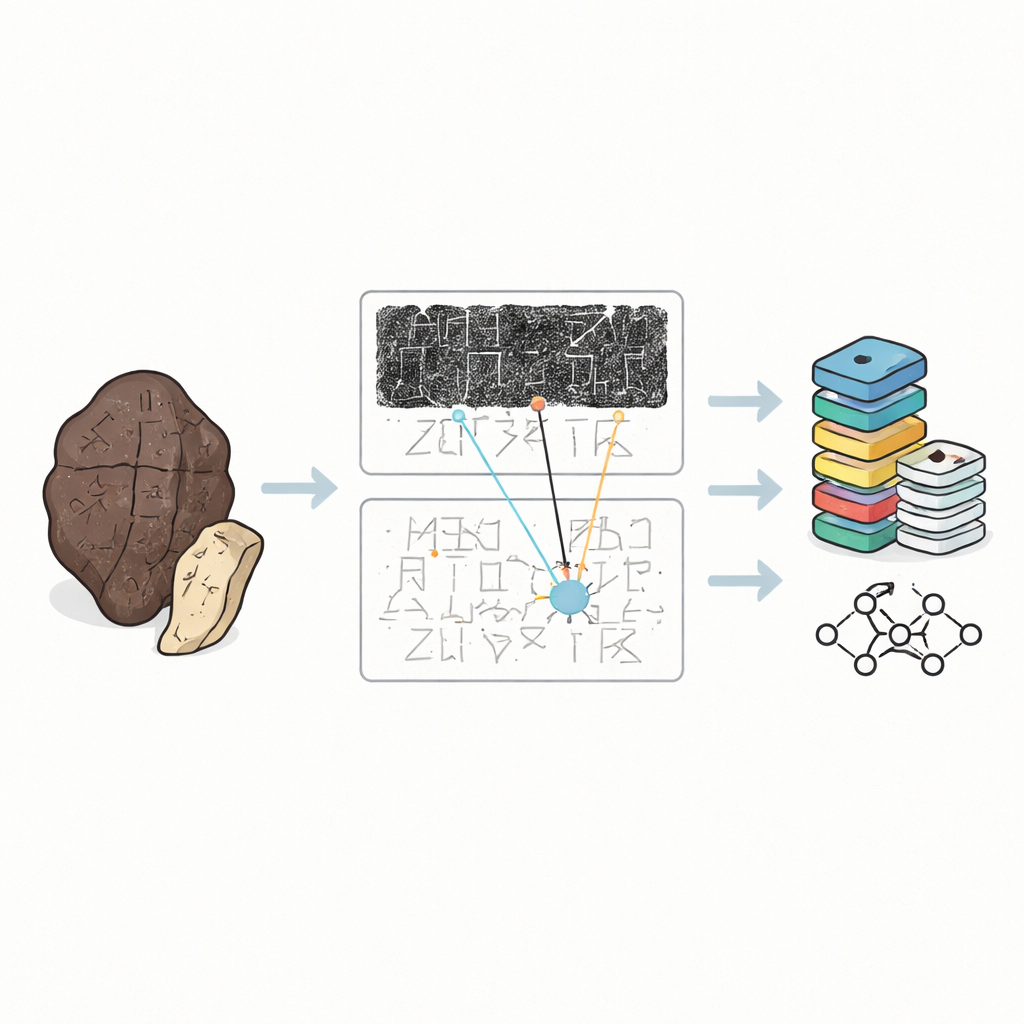
Почему старые кости трудно прочесть
Гадательные кости — это не аккуратные страницы текста. Они обломаны, обожжены и часто расколоться на куски, а надписи извиваются по изогнутой поверхности в запутанных направлениях. Учёные редко работают с оригиналами. Вместо этого они опираются на три вида заменителей: тёмные оттиски тушью, снятые с поверхности кости; рукописные фасимиле, которые проясняют штрихи; и печатные транскрипции, показывающие, как эксперты считают, что текст должен читаться. До сих пор большинство цифровых коллекций рассматривали отдельные знаки, вырезанные из оттисков, как изолированные изображения. Это полезно для обучения компьютеров распознавать формы, но игнорирует более широкий контекст, который на самом деле используют человеческие специалисты для расшифровки неясных или повреждённых знаков.
Богатая цифровая карта каждой надписанной кости
OBIMD меняет этот подход, рассматривая каждую кость как небольшой, структурированный мир. Для более чем десяти тысяч надписей авторы предоставляют сопоставимые изображения оттиска и фасимиле, а затем отмечают местоположение каждого читаемого знака с помощью ограничивающей рамки. Они также фиксируют места, где знак явно отсутствует из‑за отлома кости, помещая специальные пустые рамки в качестве заплат‑заполнителей. Эти знаки и пропуски сгруппированы в предложения или другие функциональные единицы, а порядок чтения — часто петляющий и нелинейный — явно записан в данных. В результате набор данных сообщает не только о том, какие формы присутствуют на кости, но и о том, как они образуют строки текста, в каком порядке следуют и где текст утерян.
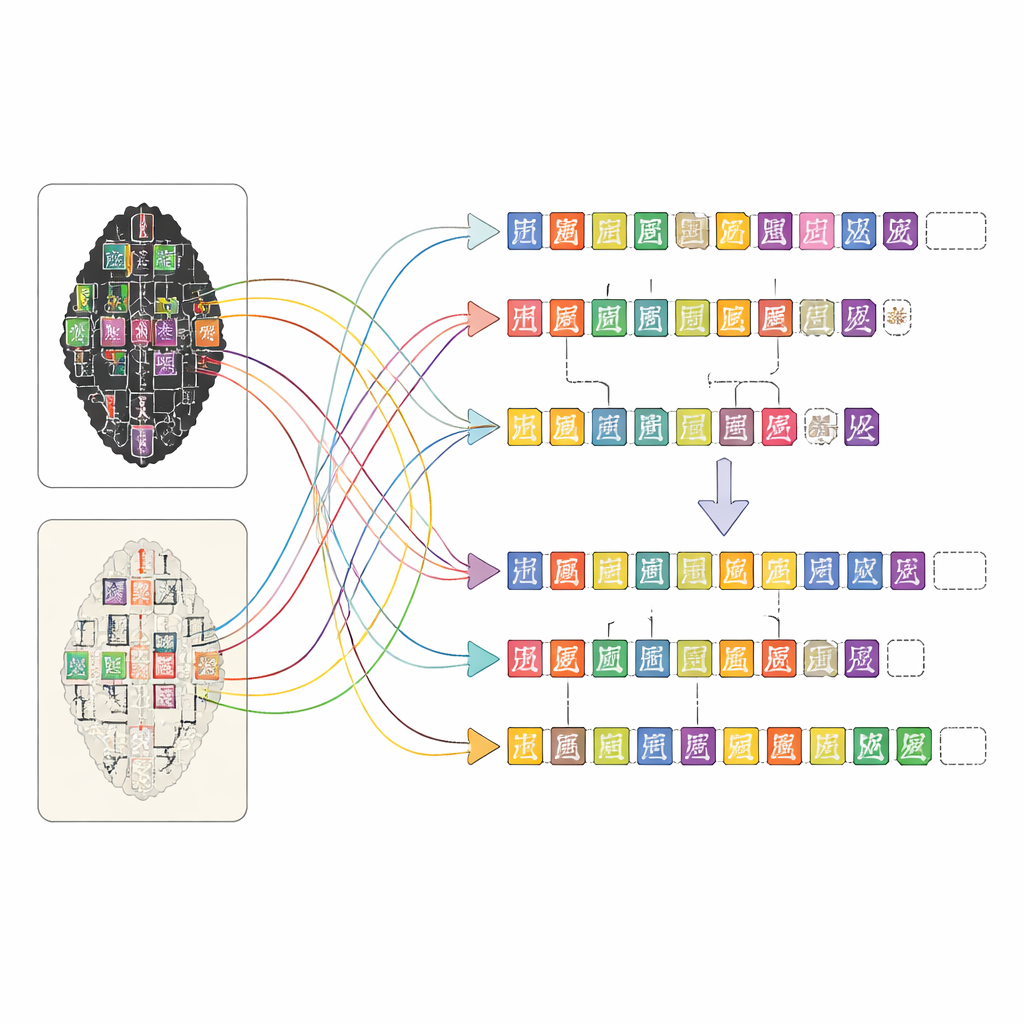
Сочетание человеческой экспертизы и машинной помощи
Построение такой детализированной карты для тысяч сложных надписей было бы невозможно вручную в одиночку. Команда разработала веб‑платформу, которая позволяет людям с разным уровнем подготовки эффективно работать вместе. Сначала инструменты компьютерного зрения сканируют изображения оттисков и фасимиле, предлагая, где могут находиться знаки и каким записям из специализированной библиотеки символов они похожи. Затем неспециалисты‑аннотаторы уточняют эти предположения, сравнивая изображения и консультируясь со сканированными страницами экспертных транскрипций. Аспиранты с подготовкой по изучению гадательных костей проверяют их работу, а опытные эксперты разрешают сложные случаи, такие как сильно повреждённые знаки или спорные чтения. Такой многоуровневый подход сохраняет высокое качество при обеспечении управляемости монументальной задачи аннотаций.
Обучение компьютеров чтению древнего письма
Чтобы продемонстрировать возможности OBIMD, авторы использовали его для обучения и тестирования современных моделей машинного обучения на нескольких задачах, вдохновлённых тем, как человеческие эксперты читают кости. Одна модель научилась локализовать и идентифицировать знаки прямо на полноразмерных изображениях, а не лишь на заранее вырезанных фрагментах, показывая лучшие результаты на чистых фасимиле и испытывая наибольшие трудности с тонкими вариантами в «шумных» оттисках. Другая модель научилась группировать знаки в предложения на основе их позиций и форм: в целом успешно, но она всё ещё путала границы, когда строки текста перекрывались. Третья модель обучалась восстанавливать исходный порядок чтения перепутанных знаков внутри предложения, правильно угадывая точный порядок в большинстве случаев и близко подходя во многих других. В совокупности эти тесты показывают, что OBIMD может как стимулировать прогресс, так и выявлять оставшиеся трудности в автоматическом чтении древних письмен.
Что это значит для нашей картины прошлого
Для неспециалистов ключевое послание таково: OBIMD превращает рассеянные, хрупкие следы раннего китайского письма в связный, машинно‑читаемый ресурс. Совмещая изображения, экспертные рисунки и чтения на уровне предложений и тщательно отмечая как утраченное, так и сохранившееся, набор данных отражает то, как учёные на самом деле собирают смысл из повреждённых артефактов. Он открывает двери для крупномасштабных исследований языковых изменений, канцелярской практики и придворной жизни династии Шан, а также предлагает требовательную испытательную базу для систем искусственного интеллекта, стремящихся «прочитать» прошлое. Коротко говоря, OBIMD — не перевод гадательных костей, но это детализированная карта, которой будущие историки и алгоритмы будут пользоваться, чтобы их исследовать.
Цитирование: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Ключевые слова: надписи на гадательных костях, древнее письмо, цифровые гуманитарные науки, мультимодальный набор данных, распознавание текста с помощью ИИ