Clear Sky Science · pl
OBIMD: Zbiór multimodalny do kontekstualnej interpretacji inskrypcji na kościach wróżebnych
Odkrywanie wiadomości z pradawnych kości
Ponad trzy tysiąclecia temu królewscy wróżbici w Chinach wyrywali pytania do duchów na kościach zwierzęcych i skorupach żółwi, a następnie podgrzewali je, aż pękały. Te kości wróżebne zachowały jedne z najwcześniejszych pełnych zapisów pisma na świecie, jednak dziś przetrwały jako kruche fragmenty rozrzucone po muzeach i publikacjach. W niniejszym badaniu przedstawiono OBIMD, nową kolekcję cyfrową, która łączy obrazy i ekspertyzy odczytów tych inskrypcji, dając historykom i komputerom potężne narzędzie do badania, jak działało to starożytne pismo i co ujawnia o wczesnym społeczeństwie chińskim.
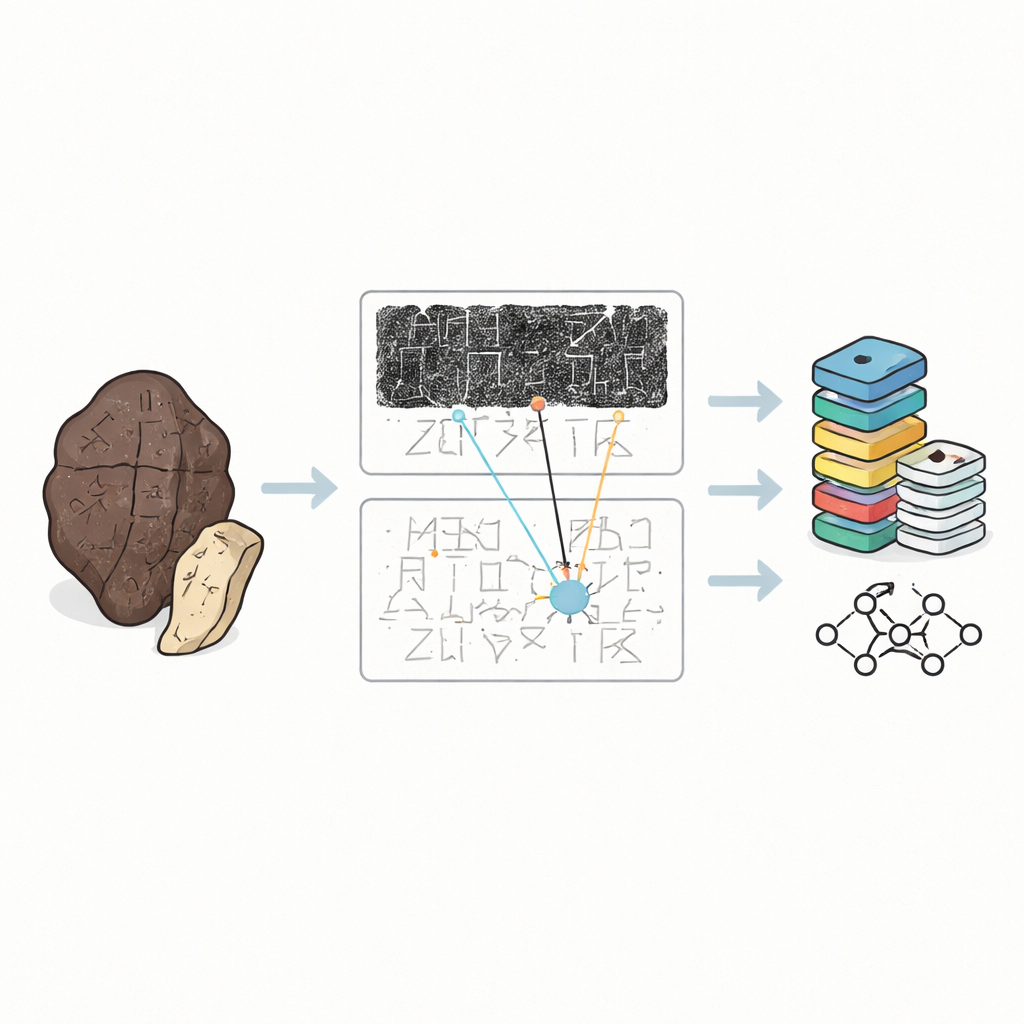
Dlaczego stare kości trudno odczytać
Kości wróżebne nie są porządnymi stronami tekstu. Są odpryśnięte, przypalone i często rozbite na kawałki, a pismo owija się po zakrzywionej powierzchni w zagadkowych kierunkach. Uczeni rzadko dotykają oryginałów. Zamiast tego polegają na trzech rodzajach zastępników: ciemnych odciskach tuszem pobieranych z powierzchni kości, ręcznie rysowanych facsimile, które wyjaśniają pociągnięcia, oraz drukowanych transkrypcjach pokazujących, jak eksperci uważają, że tekst powinien być czytany. Do tej pory większość zbiorów cyfrowych traktowała pojedyncze znaki wycięte z odcisków jako odizolowane obrazy. To przydatne przy trenowaniu komputerów do rozpoznawania kształtów, ale pomija szerszy kontekst, którego ludzie używają, aby rozszyfrować niejasne lub uszkodzone znaki.
Bogata cyfrowa mapa każdej opisanej kości
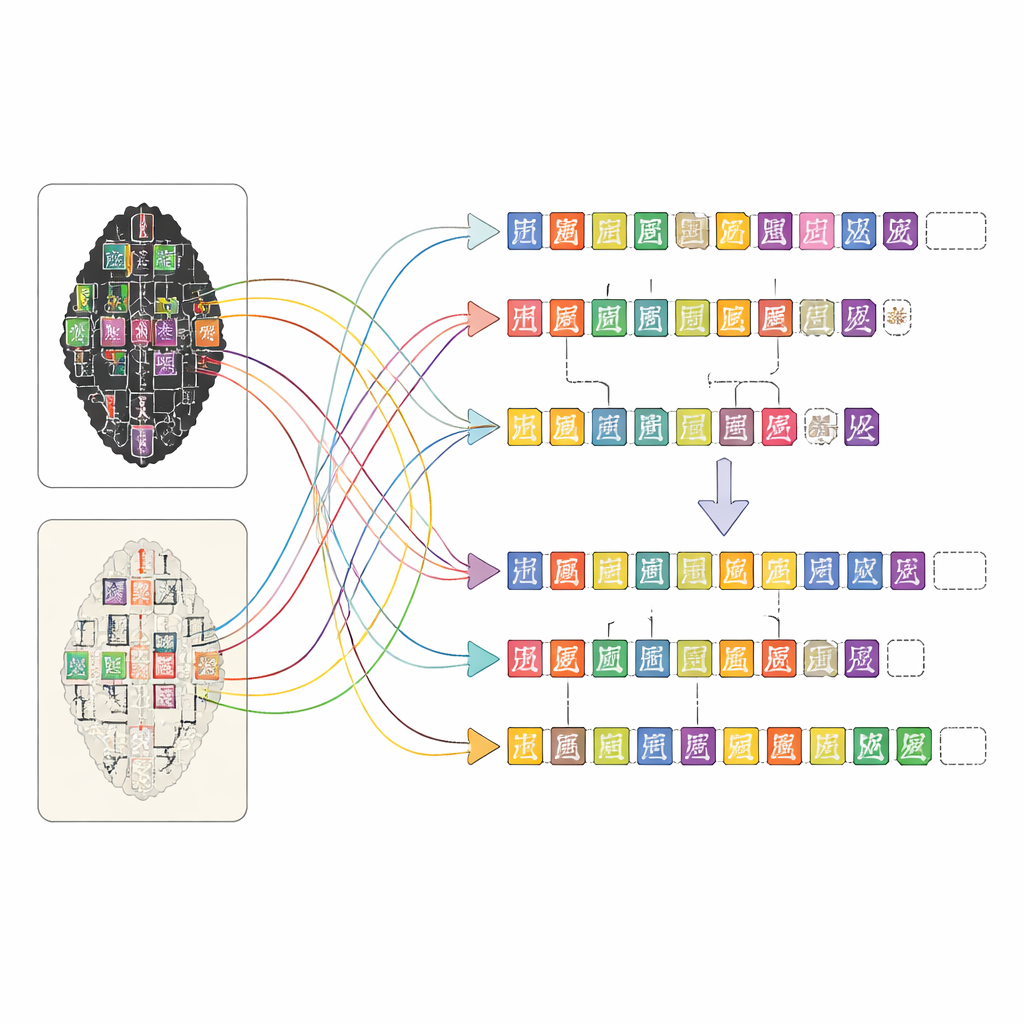
OBIMD zmienia ten obraz, traktując każdą kość jako mały, uporządkowany świat sam w sobie. Dla ponad dziesięciu tysięcy inskrypcji autorzy dostarczają dopasowany odcisk tuszu i obraz facsimile, a następnie oznaczają lokalizację każdego czytelnego znaku ramką ograniczającą. Rejestrują też miejsca, w których znak wyraźnie zaginął z powodu odłamania kości, umieszczając specjalne puste pola jako zastępcze. Znaki i luki grupowane są w zdania lub inne jednostki funkcjonalne, a porządek czytania — często pętlowy i nieliniowy — jest jawnie zapisany w danych. W efekcie zbiór danych nie tylko informuje, jakie kształty pojawiają się na kości, lecz także jak tworzą linie tekstu, w jakiej kolejności występują i gdzie tekst został utracony.
Łączenie wiedzy ludzkiej i pomocy maszyn
Stworzenie tak szczegółowej mapy dla tysięcy złożonych inskrypcji byłoby niemożliwe wyłącznie ręcznie. Zespół zaprojektował platformę internetową, która pozwala osobom o różnym poziomie przygotowania współpracować efektywnie. Najpierw narzędzia wizji komputerowej skanują obrazy odcisków i facsimile, proponując, gdzie mogą znajdować się znaki i którym pozycjom w specjalistycznej bibliotece znaków przypominają. Następnie annotatorzy nietechniczni dopracowują te sugestie, porównując obrazy i konsultując zeskanowane strony z eksperckimi transkrypcjami. Studenci podyplomowi szkoleni w badaniach nad kośćmi wróżebnymi weryfikują ich pracę, a doświadczeni eksperci rozstrzygają trudne przypadki, takie jak mocno uszkodzone znaki czy sporne odczyty. Ten warstwowy sposób pracy utrzymuje wysoką jakość przy jednoczesnym uczynieniu monumentalnego zadania anotacji wykonalnym.
Nauczanie komputerów czytania starożytnego pisma
Aby pokazać, co umożliwia OBIMD, autorzy użyli go do trenowania i testowania współczesnych modeli uczenia maszynowego w kilku zadaniach inspirowanych sposobem, w jaki eksperci czytają kości. Jeden model nauczył się lokalizować i identyfikować znaki bezpośrednio na pełnych obrazach, a nie tylko na wcześniej wyciętych fragmentach, osiągając najlepsze wyniki na czystszych rysunkach facsimile i mając największe trudności z subtelnymi wariantami w zaszumionych odciskach tuszem. Inny model nauczył się grupować znaki w zdania na podstawie ich pozycji i kształtów, w większości przypadków odnosząc sukces, choć nadal mylił granice, gdy linie tekstu nachodziły na siebie. Trzeci model został wytrenowany do odtwarzania pierwotnego porządku czytania pomieszanych znaków w zdaniu, poprawnie odgadując dokładną kolejność w większości przypadków i zbliżając się do niej w wielu innych. Razem te testy pokazują, że OBIMD może napędzać postęp i jednocześnie uwidaczniać pozostające wyzwania w automatycznym czytaniu starych pism.
Co to oznacza dla naszego obrazu przeszłości
Dla osób niebędących specjalistami kluczowe przesłanie jest takie, że OBIMD zamienia rozproszone, kruche ślady wczesnego pisma chińskiego w spójne, czytelne dla komputerów źródło. Poprzez wyrównanie obrazów, rysunków eksperckich i odczytów na poziomie zdań oraz przez staranne oznaczanie tego, co zaginęło, jak i tego, co przetrwało, zbiór danych odzwierciedla sposób, w jaki badacze ludzie faktycznie składają znaczenie z uszkodzonych artefaktów. Otwiera to drogę do badań na dużą skalę nad zmianami języka, praktykami pisarskimi i życiem królewskim w dynastii Shang, a także oferuje wymagający poligon dla systemów sztucznej inteligencji dążących do czytania przeszłości. Krótko mówiąc, OBIMD nie jest tłumaczeniem kości wróżebnych, lecz szczegółową mapą, której przyszli historycy i algorytmy będą używać, by je badać.
Cytowanie: Li, B., Yang, J., Liang, Y. et al. OBIMD: A Multi-modal Dataset for Contextual Interpretation of Oracle Bone Inscriptions. Sci Data 13, 681 (2026). https://doi.org/10.1038/s41597-026-06967-0
Słowa kluczowe: inskrypcje na kościach wróżebnych, pisarstwo starożytne, humanistyka cyfrowa, zbiór multimodalny, rozpoznawanie tekstu przez AI