Clear Sky Science · zh
用于蛋白质-蛋白质相互作用建模的配对序列语言模型
为什么研究蛋白质配对很重要
在每个细胞内,蛋白质很少独自工作。它们成对或成较大复合体协同传递信号、构建结构并抵抗感染。知道哪些蛋白质发生相互作用、它们结合的强弱以及确切接触位置,能揭示细胞如何运作以及疾病如何产生。但在实验室中测量所有这些蛋白质配对既缓慢又昂贵。本研究提出了一种新的人工智能模型,它将两条蛋白质序列一起读取,学习识别谁与谁结合、结合强度以及接触点——仅以氨基酸序列作为输入。
一次读取两条蛋白质的新方法
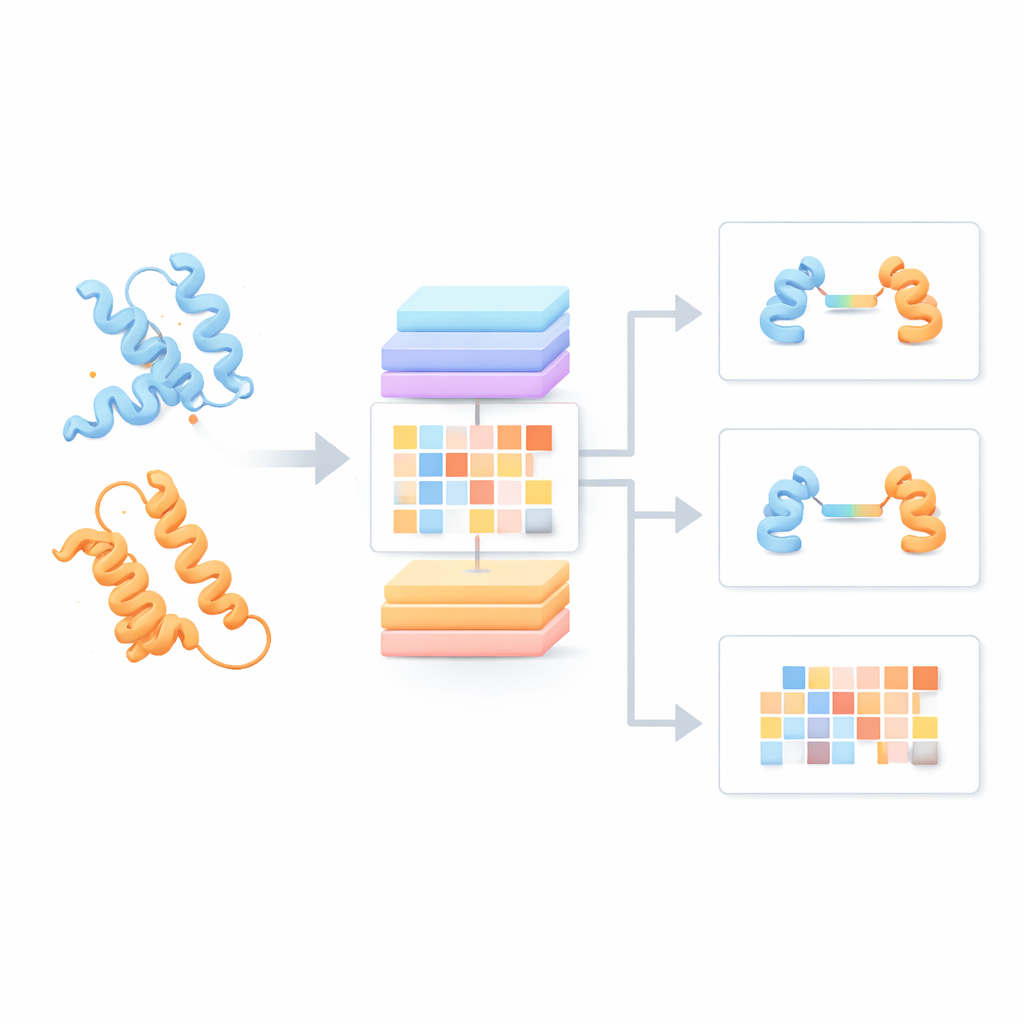
大多数现有的蛋白质语言模型将每条蛋白链视为孤立,忽略了其可能与伙伴发生的相互作用。作者构建了一个“蛋白质配对语言模型”(PPLM),始终并列查看两条序列。它使用了一种变换器架构——一种在语言技术中流行的深度学习模型——但经过定制,能够分别跟踪每条蛋白内的模式以及两条蛋白之间的模式。为训练该模型,团队从结构数据库和相互作用网络中汇集了超过330万对蛋白质,为模型提供了自然蛋白如何在真实生物学中配对的广泛视角。
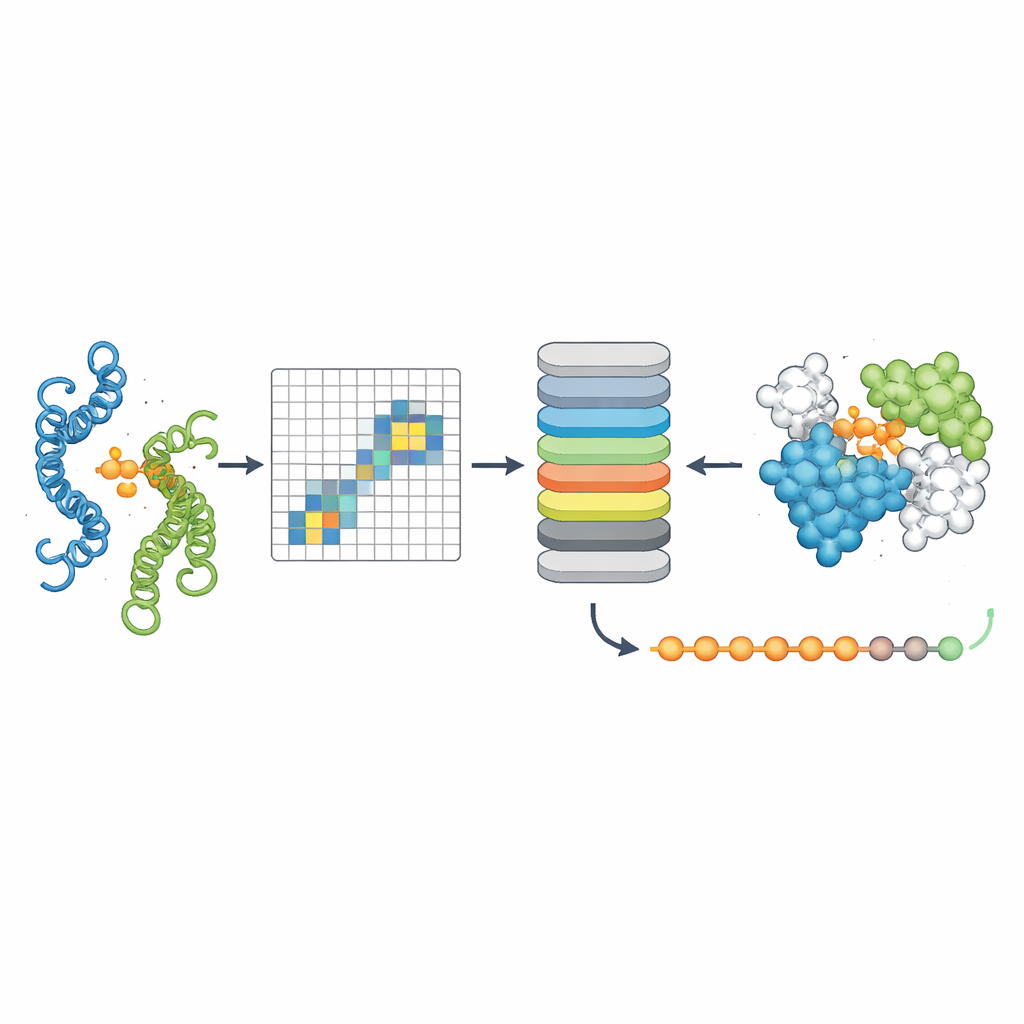
从序列中看到隐藏的相互作用信号
为测试PPLM是否真正理解蛋白质配对,作者让它在序列对中预测被遮蔽的氨基酸,并将其与一个领先的单序列模型ESM2进行了比较。在来自不同来源的数千对蛋白中,PPLM在信心和准确性上始终更胜一筹,尤其是在位于两蛋白接触界面的残基处。通过可视化模型内部的“注意力”模式,研究人员表明PPLM自然聚焦于这些接触区域,尽管模型从未被明确告知界面位置。在一个已知蛋白复合体的详细案例研究中,模型最强的注意力残基对与三维空间中大多数实验观测到的接触相吻合。
从基础理解到实际预测
在此基础上,团队开发了三种应用工具。PPLM-PPI预测两条蛋白是否可能发生相互作用。在五个不同物种的测试中,它优于若干最先进的基于序列的方法,即使测试蛋白与训练集中见到的蛋白差异较大,也能提供更准确、更稳定的相互作用判定。PPLM-Affinity估计两蛋白之间的结合强度。在一个有测量结合强度的大型基准测试中,它不仅击败了一个为相同任务微调的ESM2版本,还超越了一个使用详细三维结构的专门方法。对抗体与抗原结合、T细胞受体识别免疫靶点等医学重要体系的提升尤其显著。
精准定位蛋白接触位点
第三个工具PPLM-Contact聚焦于两条蛋白之间哪些残基对实际发生接触。它将PPLM的跨蛋白注意力模式与来自多序列比对的进化信息以及单个蛋白结构的距离图结合起来。在多个具有挑战性的测试集中,PPLM-Contact比现有方法更准确地恢复接触图并识别界面残基,其中一些现有方法在很大程度上依赖结构输入。一个增强版本PPLM-Contact2更进一步,结合了来自现代三维建模系统的预测复合体结构。这种混合方法在接触预测上甚至超越了那些结构预测器本身,提供了更清晰的结合表面视图和更可靠的结合位点定位。
这对生物学和医学意味着什么
综上所述,这项工作表明,将蛋白质序列成对读取而非单独读取,使得人工智能模型能够捕捉支撑细胞生命的微妙相互作用模式。PPLM及其衍生工具可以仅凭廉价且丰富的序列信息判断两蛋白是否可能相遇、它们结合的紧密程度以及哪些氨基酸构成“握手”。尽管该方法在非常小或弱的界面上仍存在挑战,并且依赖于可用训练数据的多样性,但它为绘制相互作用网络并指导抗体、T细胞受体及其他生物药物的设计提供了一条可扩展的路径。本质上,研究证明了共表示的语言模型可以将原始序列数据转化为关于蛋白质如何协同工作的丰富、具交互意识的见解。
引用: Liu, J., Chen, H. & Zhang, Y. A paired sequence language model for protein-protein interaction modeling. Nat Commun 17, 3733 (2026). https://doi.org/10.1038/s41467-026-70457-5
关键词: 蛋白质–蛋白质相互作用, 蛋白质语言模型, 结合亲和力, 界面接触预测, 计算结构生物学