Clear Sky Science · pt
Um modelo de linguagem de sequências pareadas para modelagem de interações proteína–proteína
Por que estudar parcerias de proteínas importa
Dentro de cada célula, proteínas raramente atuam sozinhas. Elas se associam em pares ou grupos maiores para transmitir sinais, construir estruturas e combater infecções. Saber quais proteínas interagem, com que intensidade se ligam e exatamente onde se tocam pode revelar como as células funcionam e como surgem doenças. Mas medir todas essas parcerias proteicas em laboratório é lento e caro. Este estudo apresenta um novo modelo de inteligência artificial que lê pares de sequências de proteínas em conjunto, aprendendo a reconhecer quem se liga a quem, com que força e em quais pontos de contato — usando apenas suas sequências de aminoácidos como entrada.
Uma nova maneira de ler duas proteínas ao mesmo tempo
A maioria dos modelos de linguagem para proteínas trata cada cadeia como se estivesse isolada, ignorando como ela pode interagir com parceiros. Os autores desenvolveram, em vez disso, um “Modelo de Linguagem para Pares de Proteínas” (PPLM) que sempre olha duas sequências lado a lado. Ele usa uma arquitetura transformer, um tipo de modelo de aprendizado profundo popularizado em tecnologias de linguagem, mas personalizado para acompanhar separadamente padrões dentro de cada proteína e entre as duas proteínas. Para treiná-lo, a equipe reuniu mais de 3,3 milhões de pares de proteínas a partir de bancos de dados estruturais e redes de interação, oferecendo ao modelo uma visão ampla de como proteínas naturais tendem a se parear na biologia real.
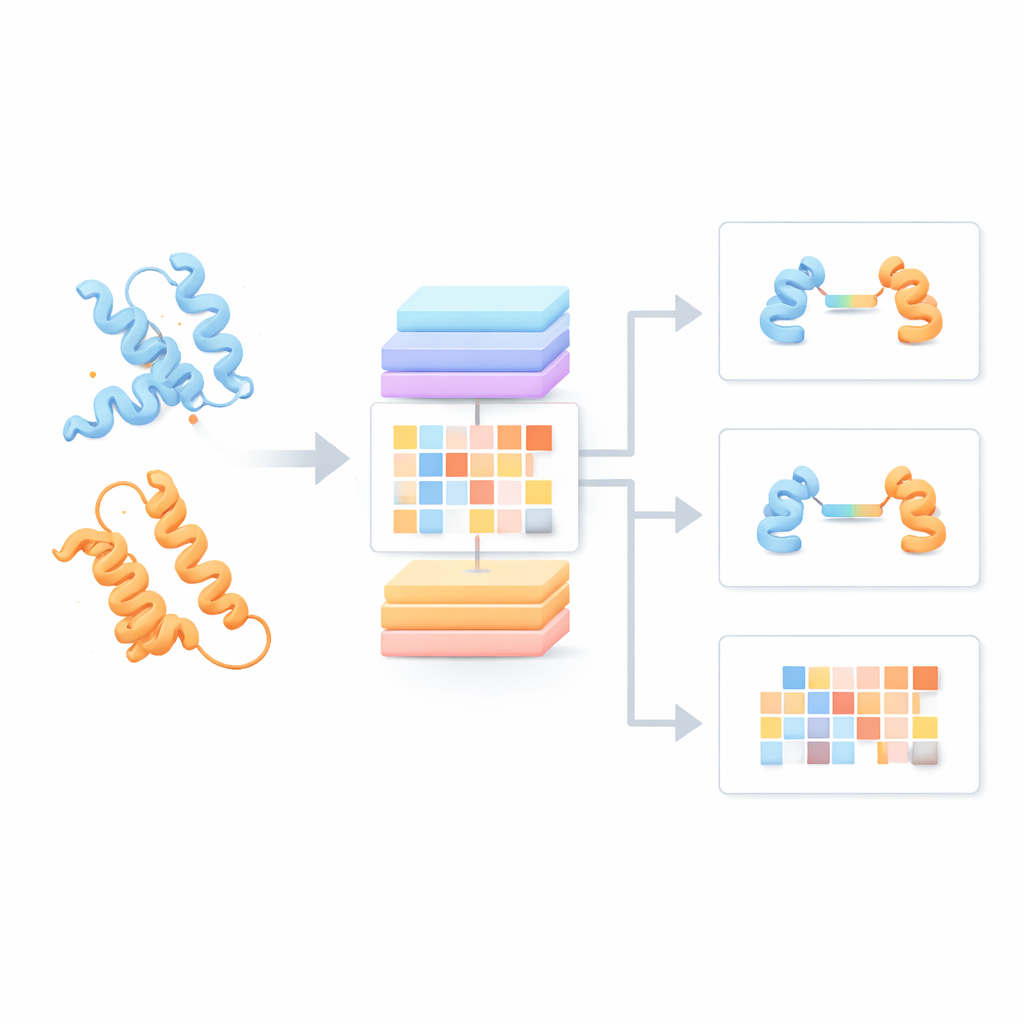
Vendo sinais de interação escondidos nas sequências
Para testar se o PPLM realmente entende parcerias proteicas, os autores pediram que ele previsse aminoácidos mascarados em pares de sequências e o compararam com um modelo líder de sequência única chamado ESM2. Ao longo de milhares de pares de proteínas de diferentes fontes, o PPLM foi consistentemente mais confiante e preciso, especialmente em resíduos localizados exatamente na interface onde as proteínas se tocam. Ao visualizar os padrões internos de “atenção” do modelo, os pesquisadores mostraram que o PPLM naturalmente foca nessas regiões de contato, mesmo sem ter sido explicitamente informado sobre a localização da interface. Em um estudo de caso detalhado de um complexo proteico conhecido, os pares de resíduos mais fortemente atendidos pelo modelo corresponderam à maior parte dos contatos observados experimentalmente no espaço tridimensional.
Da compreensão básica a previsões práticas
Com base nessa fundação, a equipe criou três ferramentas aplicadas. O PPLM-PPI prevê se duas proteínas provavelmente irão interagir. Testado em cinco espécies diferentes, superou vários métodos baseados em sequência de última geração, fornecendo chamadas de interação mais precisas e mais estáveis mesmo quando as proteínas de teste eram bastante diferentes das vistas no treinamento. O PPLM-Affinity estima quão forte é a ligação entre duas proteínas. Em um grande benchmark de complexos com forças de ligação medidas, não apenas venceu uma versão do ESM2 afinada para a mesma tarefa, mas também superou um método especializado que usa estruturas 3D detalhadas. Os ganhos foram especialmente notáveis em sistemas de importância médica, como anticorpos ligando a antígenos e receptores de células T reconhecendo alvos imunológicos.
Localizando com precisão onde as proteínas se tocam
A terceira ferramenta, PPLM-Contact, foca em quais pares de resíduos entre duas proteínas efetivamente fazem contato. Ela combina os padrões de atenção cruzada do PPLM com informação evolutiva de alinhamentos de múltiplas sequências e mapas de distância de estruturas de proteínas individuais. Em vários conjuntos de teste desafiadores, o PPLM-Contact recuperou com precisão mapas de contato e identificou resíduos de interface melhor do que métodos existentes, incluindo alguns que dependem fortemente de insumos estruturais. Uma versão aprimorada, PPLM-Contact2, vai além ao incorporar estruturas complexas previstas por sistemas modernos de modelagem 3D. Essa abordagem híbrida melhora a predição de contatos até mesmo em relação àqueles preditores de estruturas, oferecendo visões mais nítidas das superfícies de ligação e localização mais confiável dos sítios de interação.
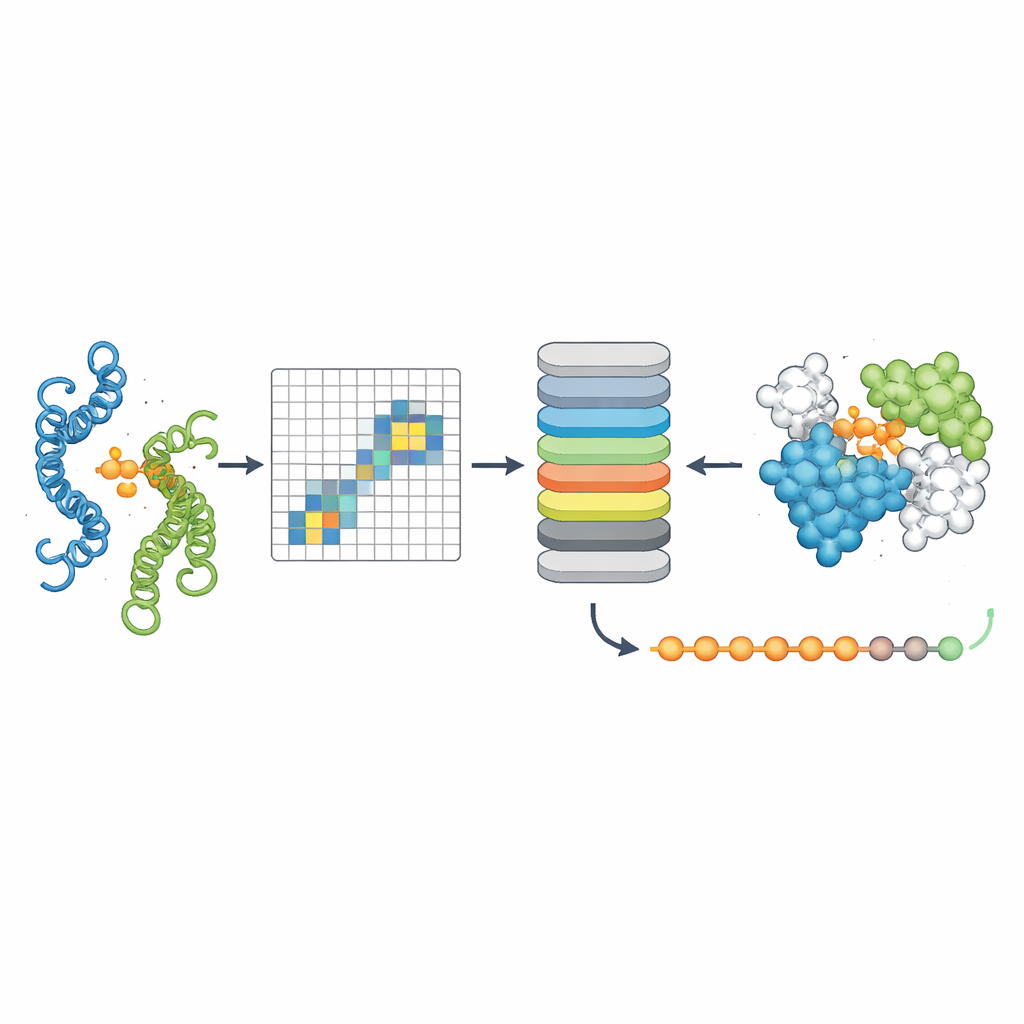
O que isso significa para a biologia e a medicina
Considerado em conjunto, este trabalho mostra que ler sequências de proteínas em pares, em vez de isoladamente, permite que modelos de IA capturem padrões sutis de interação que sustentam a vida celular. O PPLM e seus derivados podem dizer se duas proteínas provavelmente irão se encontrar, com que força se apertam e quais aminoácidos formam o aperto — tudo a partir de informação de sequência que é barata e abundante. Embora a abordagem ainda tenha dificuldades com interfaces muito pequenas ou fracas e dependa da diversidade dos dados de treinamento disponíveis, ela oferece um caminho escalável para mapear redes de interação e orientar o desenho de anticorpos, receptores de células T e outros fármacos biológicos. Em essência, o estudo demonstra que modelos de linguagem co-representados podem transformar dados brutos de sequência em uma compreensão rica e sensível a interações sobre como proteínas trabalham em conjunto.
Citação: Liu, J., Chen, H. & Zhang, Y. A paired sequence language model for protein-protein interaction modeling. Nat Commun 17, 3733 (2026). https://doi.org/10.1038/s41467-026-70457-5
Palavras-chave: interações proteína–proteína, modelos de linguagem para proteínas, afinidade de ligação, predição de contatos de interface, biologia estrutural computacional