Clear Sky Science · nl
Een gekoppeld sequentie-taalmodel voor modellering van eiwit-eiwitinteracties
Waarom het bestuderen van eiwitpartnerschappen belangrijk is
In elke cel werken eiwitten zelden alleen. Ze vormen paren of grotere groepen om signalen door te geven, structuren op te bouwen en infecties te bestrijden. Weten welke eiwitten met elkaar interageren, hoe sterk ze binden en precies waar ze elkaar aanraken kan onthullen hoe cellen functioneren en hoe ziekten ontstaan. Het meten van al deze eiwitpartnerschappen in het laboratorium is echter traag en duur. Deze studie introduceert een nieuw kunstmatig-intelligentie-model dat paarsgewijs eiwitsequenties leest en leert herkennen wie met wie bindt, hoe sterk en op welke contactpunten—gebruikt alleen hun aminozuursequenties als invoer.
Een nieuwe manier om twee eiwitten tegelijk te lezen
De meeste huidige eiwit-taalmodellen behandelen elke eiwitketen alsof deze alleen staat en negeren hoe ze met partners kan interageren. De auteurs bouwden in plaats daarvan een “Protein Pair Language Model” (PPLM) dat altijd twee sequenties naast elkaar bekijkt. Het gebruikt een transformer-architectuur, een type deep-learningmodel dat populair is in taaltechnologieën, maar aangepast zodat het afzonderlijk patronen binnen elk eiwit en tussen de twee eiwitten kan volgen. Voor training verzamelde het team meer dan 3,3 miljoen eiwitparen uit structurele databases en interactienetwerken, wat het model een brede kijk gaf op hoe natuurlijke eiwitten in de biologie geneigd zijn te koppelen.
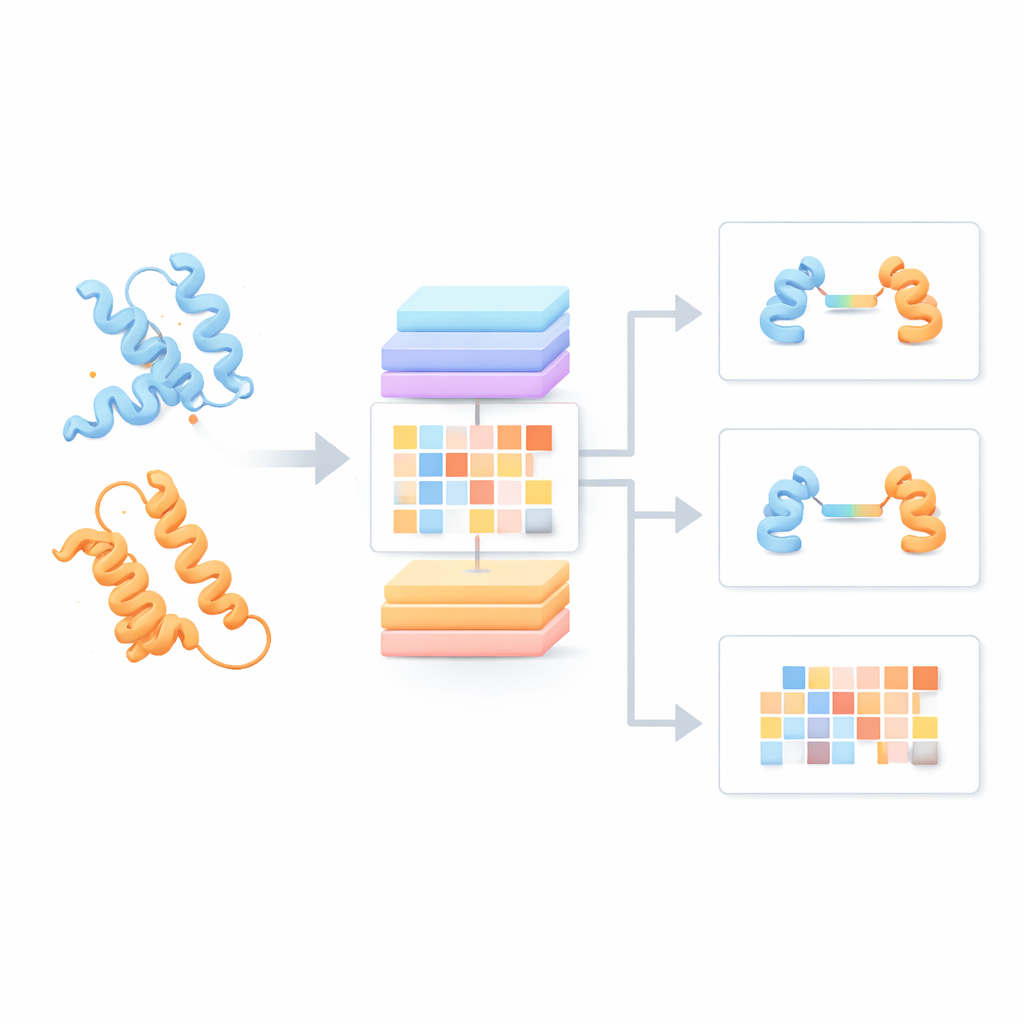
Interactie-signalen zien die in sequenties verborgen liggen
Om te testen of PPLM echt begrip heeft van eiwitpartnerschappen vroegen de auteurs het model om gemaskeerde aminozuren in sequentieparen te voorspellen en vergeleken ze dit met een toonaangevend enkel-sequentiemodel genaamd ESM2. Over duizenden eiwitparen uit verschillende bronnen was PPLM consequent zelfverzekerder en nauwkeuriger, vooral bij residuen die zich precies op de interface bevinden waar de eiwitten elkaar aanraken. Door de interne “attention”-patronen van het model te visualiseren, lieten de onderzoekers zien dat PPLM van nature focust op die contactregio’s, hoewel het nooit expliciet verteld werd waar de interface ligt. In een gedetailleerde casestudy van een bekend eiwitcomplex kwamen de residuparen met de sterkste aandacht overeen met het merendeel van de experimenteel waargenomen contacten in driedimensionale ruimte.
Van basisbegrip naar praktische voorspellingen
Voortbouwend op deze basis creëerde het team drie toegepaste hulpmiddelen. PPLM-PPI voorspelt of twee eiwitten waarschijnlijk met elkaar zullen interageren. Getest over vijf verschillende soorten presteerde het beter dan verschillende state-of-the-art methoden op sequentiebasis, met nauwkeurigere en stabielere interactie-beslissingen, zelfs wanneer testeiwitten sterk verschilden van die in de training. PPLM-Affinity schat hoe sterk de binding tussen twee eiwitten is. Op een grote benchmark van complexen met gemeten bindingssterkten versloeg het niet alleen een voor dezelfde taak gefinetuned ESM2, maar ook een gespecialiseerde methode die gedetailleerde 3D-structuren gebruikt. De verbeteringen waren vooral opvallend voor medisch belangrijke systemen zoals antilichamen die aan antigenen binden en T-celreceptoren die immuuntargets herkennen.
Het aanwijzen waar eiwitten elkaar raken
Het derde hulpmiddel, PPLM-Contact, zoomt in op welke residuparen tussen twee eiwitten daadwerkelijk contact maken. Het combineert PPLM’s cross-protein attention-patronen met evolutionaire informatie uit multiple sequence alignments en afstandskaarten van individuele eiwitstructuren. Over verschillende uitdagende testsets herstelde PPLM-Contact contactkaarten nauwkeurig en identificeerde het interfaceresiduen beter dan bestaande methoden, inclusief sommige die sterk afhankelijk zijn van structurele input. Een verbeterde versie, PPLM-Contact2, gaat een stap verder door voorspelde complexe structuren van moderne 3D-modelleringssystemen te integreren. Deze hybride aanpak verbetert contactvoorspelling zelfs voorbij die structuurpredictoren zelf, levert scherpere beelden van bindingsoppervlakken en betrouwbaardere lokalisatie van bindingsplaatsen.
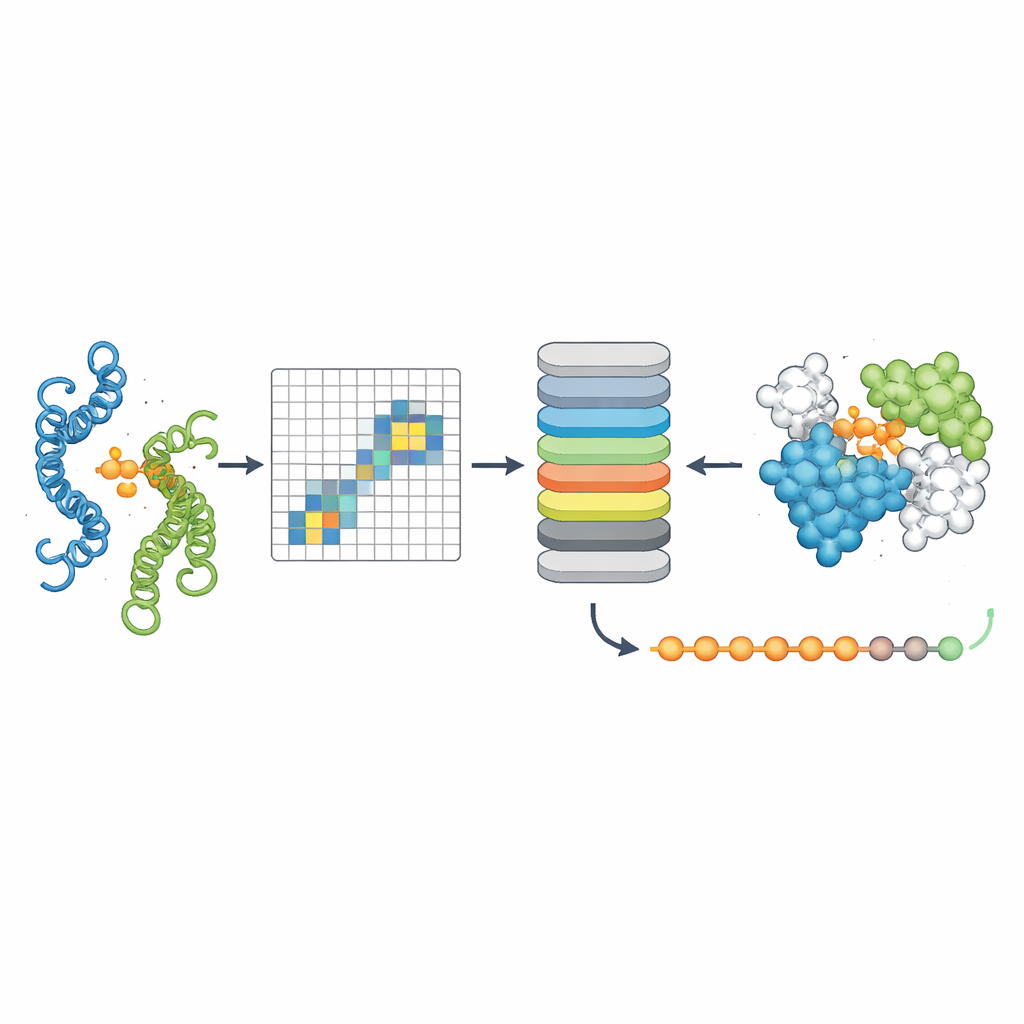
Wat dit betekent voor biologie en geneeskunde
Alles bij elkaar laat dit werk zien dat het lezen van eiwitsequenties in paren, in plaats van afzonderlijk, AI-modellen in staat stelt subtiele interactiepatronen te vangen die ten grondslag liggen aan cellulair leven. PPLM en zijn afgeleiden kunnen aangeven of twee eiwitten elkaar waarschijnlijk ontmoeten, hoe stevig ze elkaar vasthouden en welke aminozuren de handdruk vormen—en dat allemaal op basis van sequentie-informatie die goedkoop en overvloedig is. Hoewel de aanpak nog steeds moeite heeft met zeer kleine of zwakke interfaces en afhankelijk is van de diversiteit van beschikbare trainingsdata, biedt het een schaalbaar pad naar het in kaart brengen van interactienetwerken en het sturen van het ontwerp van antilichamen, T-celreceptoren en andere biologische geneesmiddelen. In wezen toont de studie aan dat co-gerepresenteerde taalmodellen ruwe sequentiegegevens kunnen omzetten in rijke, interactie-bewuste inzichten over hoe eiwitten samenwerken.
Bronvermelding: Liu, J., Chen, H. & Zhang, Y. A paired sequence language model for protein-protein interaction modeling. Nat Commun 17, 3733 (2026). https://doi.org/10.1038/s41467-026-70457-5
Trefwoorden: eiwit–eiwitinteracties, eiwit-taalmodellen, bindingsaffiniteit, voorspelling van interfacecontacten, computationele structurele biologie