Clear Sky Science · zh
用于分子表征学习的多模态到单模态知识迁移预训练
为什么更智能的药物计算机很重要
设计新药越来越依赖能“理解”分子的计算机。这些程序将药物分子转换为模型可用的数值,以预测安全性、效力或有害相互作用。论文提出了 M2UMol,一种新的训练方法,使此类模型即便在仅有最常见的分子数据类型时也能表现良好,承诺为化学家和医生提供更快速、更可靠的辅助。
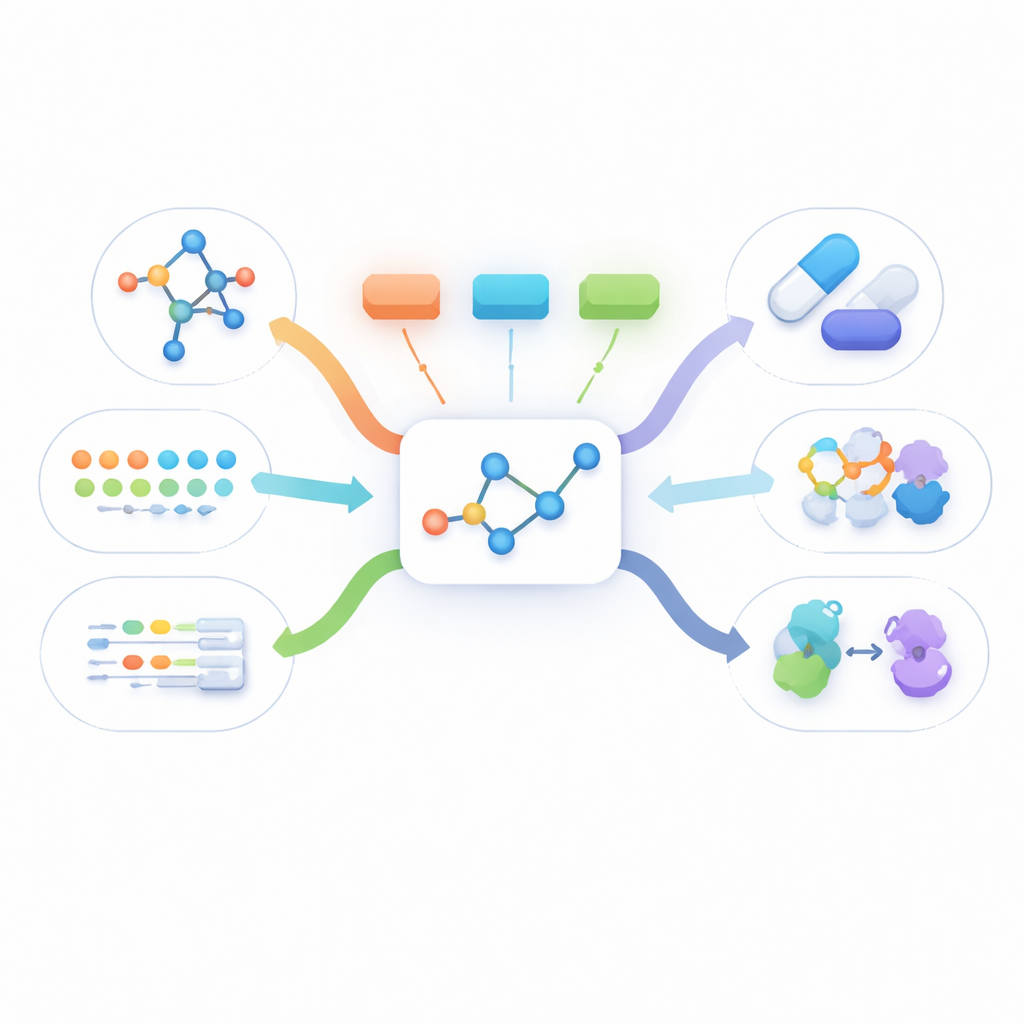
从多角度看分子
真实的药物信息有多种形式:平面原子连接图、三维构型、关于药物作用的文字描述,以及诸如其结合哪些蛋白之类的长篇生物学事实清单。大多数现有方法要么只使用其中一种视图,要么要求在训练时每个分子都有所有视图。然而在实际中,几乎总是可用的只有简单的二维结构。其他视图往往缺失,这阻碍了当前多模态方法从大量真实分子中学习。
教单一视图学会像多视图思考
M2UMol 通过将分子的二维图视为枢纽,并学习该单一视图如何与其他视图关联来应对这一问题。在预训练阶段,系统读取超过一万一千种类药物分子的二维图、三维形状、文本摘要和生物特征列表。它为每种数据类型使用独立编码器,然后训练“适配器”,这些适配器仅取二维图并生成应当对应的三维、文本或生物模式。对比学习步骤推动生成的模式在有真实数据时尽可能地贴近真实模式,即便某些分子的某些视图缺失。第二个训练任务要求系统判断某个生成模式属于哪种模态,帮助它保持不同信息类型的区分。
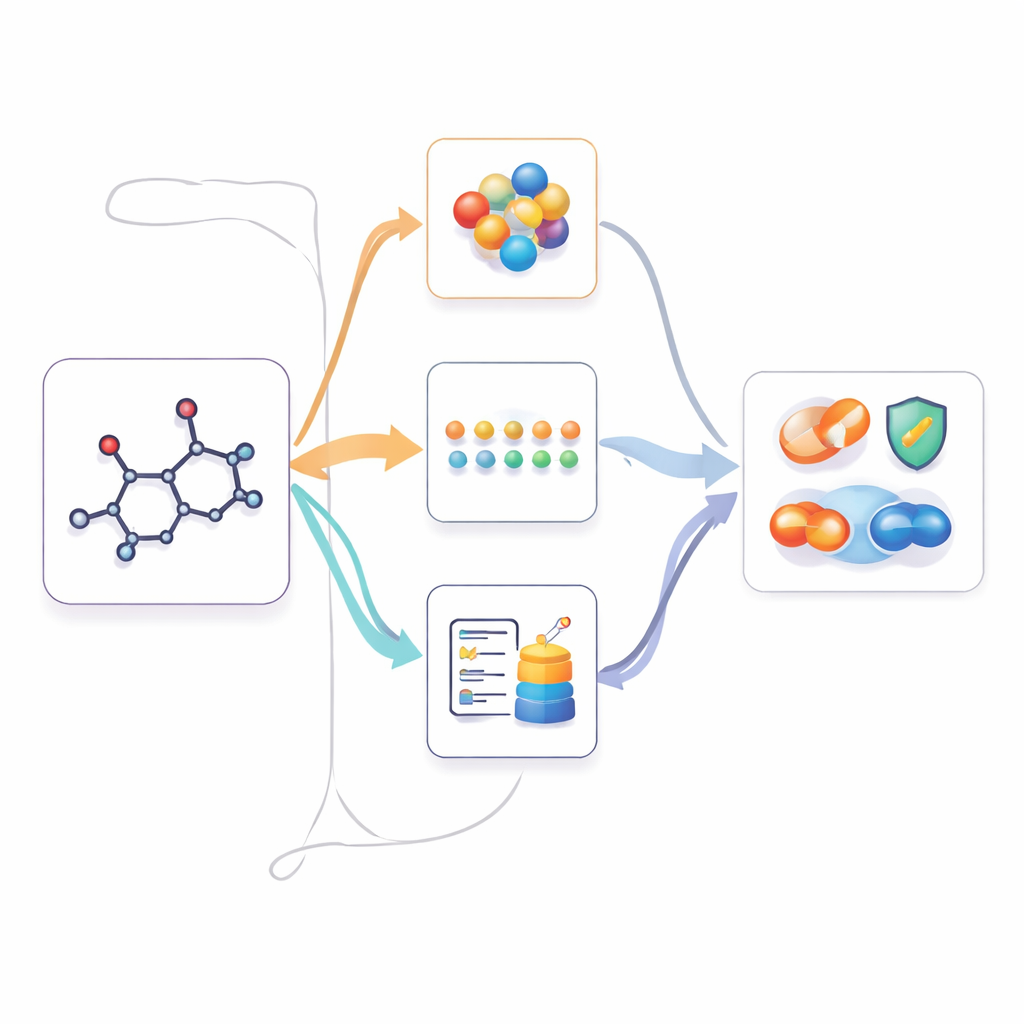
只有二维时也能利用多模态知识
一旦 M2UMol 学会了这些关系,就可以应用到仅提供二维结构的实际任务中,例如预测毒性、疾病相关性质或药物相互作用。对于每个新分子,预训练的二维编码器生成核心表征,适配器生成三种“想象”的版本:一种类似三维几何,一种模仿基于文本的知识,另一种捕捉生物学背景。一个简单的注意力模块将这四种视图组合成最终的指纹,供任务专用预测器使用。这实际上使模型表现得像拥有丰富的多模态信息,而用户只需提供标准的二维结构。
用更少数据与更清晰的推理获得更好预测
在一系列基准测试中,M2UMol 在预测分子属性以及更复杂的任务(如药物—药物和药物—靶点相互作用)上都优于单一视图和先前的多模态模型。尽管其仅在一万一千多种分子上进行预训练、使用的计算资源适中,而许多竞争方法则使用数百万条数据,M2UMol 仍能取得更好表现。可视化分析显示,学习到的表征在不同类别之间分离良好且分布均匀,表明信息含量高。模型还可以突出显示驱动其决策的特定原子和键,这些往往与已知的功能基团相符,这些基团负责毒性、受体活性或药物之间的问题性相互作用。
这对未来药物意味着什么
对非专业读者来说,关键思想是 M2UMol 学会将一幅简单的分子线图视为携带三层额外丰富科学背景的信息。这一技巧使它即便在缺乏详细实验数据时,也能给出更强、更可解释的药物行为预测。由于其高效、开源且易于使用,该方法可能帮助研究人员更明智地筛选化合物、理解为何某些药物失败,并最终在更少意外的情况下指导新药设计。
引用: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
关键词: 药物发现, 分子表征学习, 多模态人工智能, 药物相互作用, 计算化学