Clear Sky Science · fr
Pré-entraînement par transfert de connaissances multi-vers-uni pour l'apprentissage des représentations moléculaires
Pourquoi des ordinateurs plus intelligents pour les médicaments comptent
La conception de nouveaux médicaments repose de plus en plus sur des ordinateurs capables de « comprendre » les molécules. Ces programmes transforment une molécule médicamenteuse en nombres exploitables par un modèle pour prédire sécurité, puissance ou interactions nuisibles. L'article présente M2UMol, une nouvelle méthode d'entraînement de ces modèles afin qu'ils fonctionnent bien même lorsque seul le type de données moléculaires le plus courant est disponible, promettant une aide plus rapide et plus fiable pour les chimistes et les médecins.
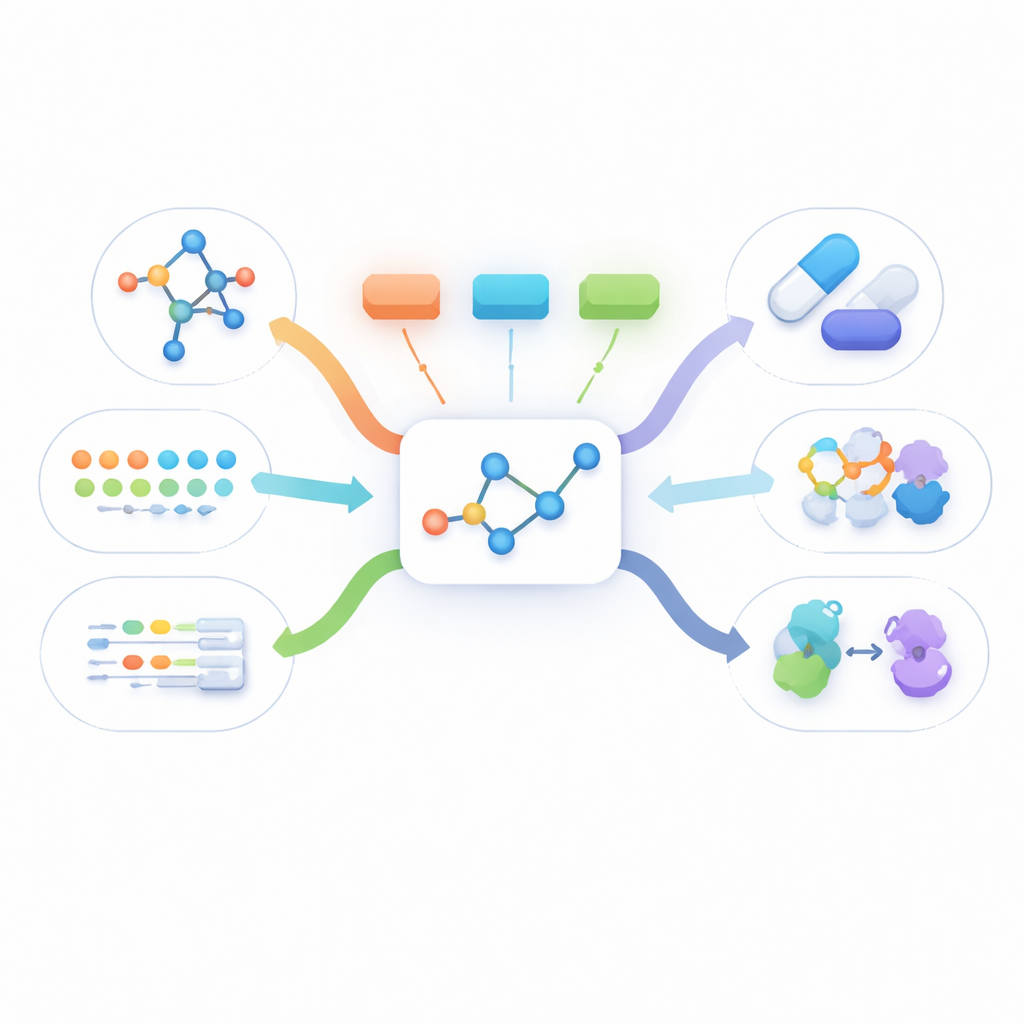
Voir une molécule sous plusieurs angles
Les informations réelles sur les médicaments existent sous de nombreuses formes : un dessin plat montrant les connexions atomiques, une forme tridimensionnelle, des descriptions écrites du mode d'action et de longues listes de faits biologiques tels que les protéines ciblées. La plupart des méthodes actuelles utilisent soit une seule de ces vues, soit exigent que toutes soient présentes pour chaque molécule lors de l'entraînement. En pratique, toutefois, la seule donnée presque toujours disponible est la structure bidimensionnelle simple. Les autres vues font souvent défaut, ce qui empêche les méthodes multimodales actuelles d'apprendre à partir d'un grand nombre de molécules issues du monde réel.
Apprendre à une vue à penser comme plusieurs
M2UMol aborde ce problème en traitant le graphe 2D d'une molécule comme le centre et en apprenant comment cette vue unique se rapporte aux autres. Lors du pré-entraînement, le système lit des graphes 2D, des formes 3D, des résumés textuels et des listes de caractéristiques biologiques pour plus de onze mille molécules de type médicament. Il utilise des encodeurs séparés pour chaque type de données puis entraîne des « adaptateurs » qui prennent uniquement le graphe 2D et génèrent ce à quoi devraient ressembler les motifs 3D, textuels ou biologiques. Une étape d'apprentissage contrastif pousse les motifs générés à correspondre étroitement aux motifs réels lorsqu'ils sont disponibles, même si certaines vues manquent pour certaines molécules. Une seconde tâche d'entraînement demande au système de deviner à quelle modalité appartient un motif généré, ce qui l'aide à maintenir la distinction entre les différents types d'information.
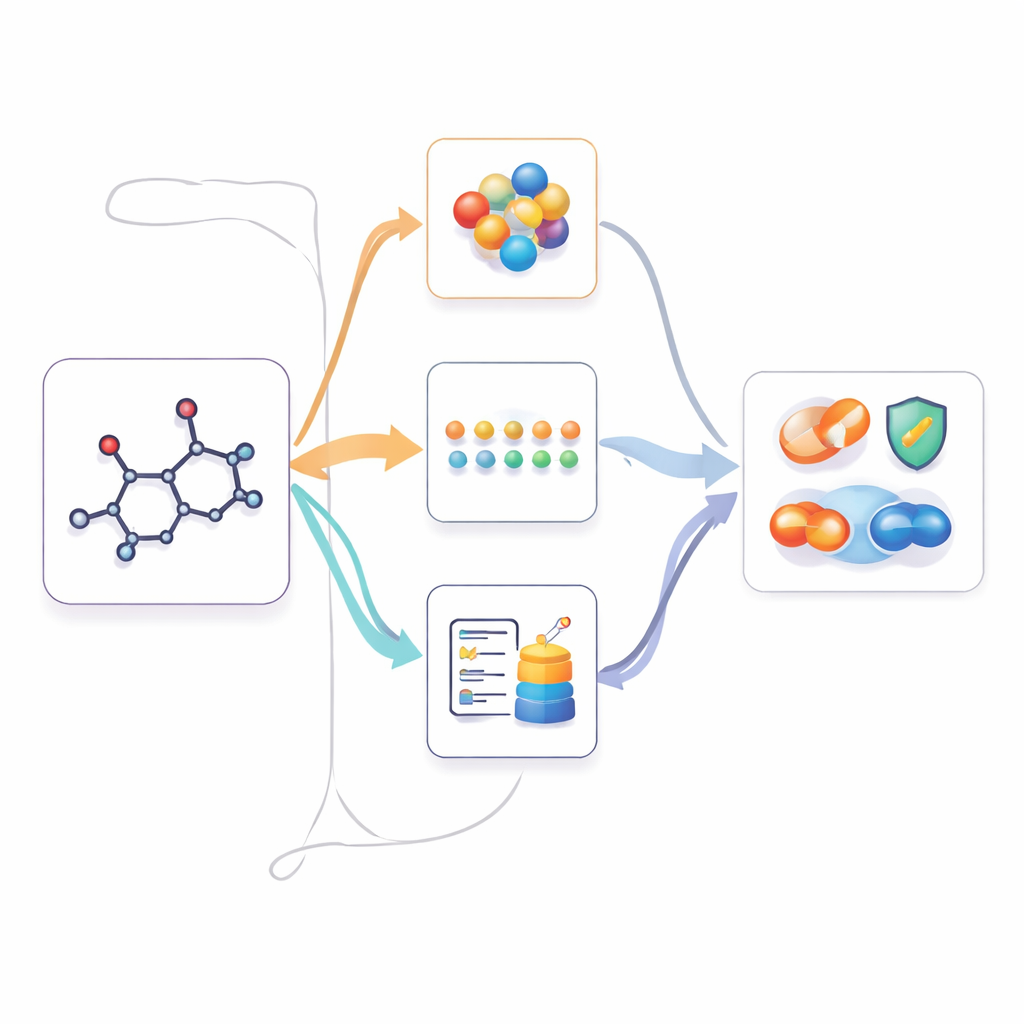
Utiliser les connaissances multimodales lorsque seul le 2D est disponible
Une fois que M2UMol a appris ces relations, il peut être appliqué à des tâches pratiques où seules des structures 2D sont fournies, comme la prédiction de la toxicité, de propriétés liées à une maladie ou des interactions médicamenteuses. Pour chaque nouvelle molécule, l'encodeur 2D pré-entraîné produit une représentation centrale, et les adaptateurs génèrent trois versions « imaginées » : une ressemblant à la géométrie 3D, une imitant les connaissances textuelles et une capturant le contexte biologique. Un simple module d'attention combine ensuite ces quatre vues en une empreinte finale utilisée par des prédicteurs dédiés à la tâche. Cela permet au modèle d'agir comme s'il disposait d'informations multimodales riches, alors que l'utilisateur n'a besoin de fournir qu'une structure 2D standard.
De meilleures prédictions avec moins de données et un raisonnement plus clair
Sur un large panel de benchmarks, M2UMol surpasse à la fois les modèles mono-vue et les modèles multimodaux précédents pour la prédiction de propriétés moléculaires et pour des tâches plus complexes comme les interactions médicament–médicament et médicament–cible. Il le fait alors même qu'il est pré-entraîné sur un peu plus de onze mille molécules, avec des ressources informatiques modestes, tandis que de nombreuses méthodes concurrentes utilisent des millions d'exemples. Des analyses visuelles montrent que les représentations apprises sont à la fois bien séparées entre les différentes classes et uniformément réparties, signe d'un contenu informationnel élevé. Le modèle peut aussi mettre en évidence des atomes et des liaisons spécifiques qui motivent ses décisions, et ceux-ci correspondent souvent à des groupes fonctionnels connus responsables de la toxicité, de l'activité sur un récepteur ou d'interactions problématiques entre médicaments.
Ce que cela signifie pour les médicaments de demain
Pour les non-spécialistes, l'idée principale est que M2UMol apprend à considérer un simple dessin linéaire d'une molécule comme s'il portait trois couches supplémentaires de contexte scientifique riche. Cette astuce lui permet de produire des prédictions plus robustes et plus interprétables sur le comportement d'un médicament, même lorsque des données expérimentales détaillées font défaut. Parce qu'il est efficace, open source et conçu pour une utilisation aisée, cette approche pourrait aider les chercheurs à mieux sélectionner les composés, à comprendre pourquoi certains médicaments échouent et, en fin de compte, à orienter la conception de nouveaux médicaments avec moins de surprises.
Citation: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Mots-clés: découverte de médicaments, apprentissage de représentations moléculaires, IA multimodale, interactions médicamenteuses, chimie computationnelle