Clear Sky Science · it
Pre-addestramento per trasferimento di conoscenza multi-a-uni per l'apprendimento della rappresentazione molecolare
Perché contano computer più intelligenti per i farmaci
La progettazione di nuovi medicinali dipende sempre più da computer in grado di "comprendere" le molecole. Questi programmi trasformano una molecola in numeri che un modello può usare per predire sicurezza, potenza o interazioni dannose. L'articolo presenta M2UMol, un nuovo modo di addestrare tali modelli in modo che funzionino bene anche quando è disponibile solo il tipo più comune di dati molecolari, promettendo un aiuto più rapido e affidabile per chimici e medici.
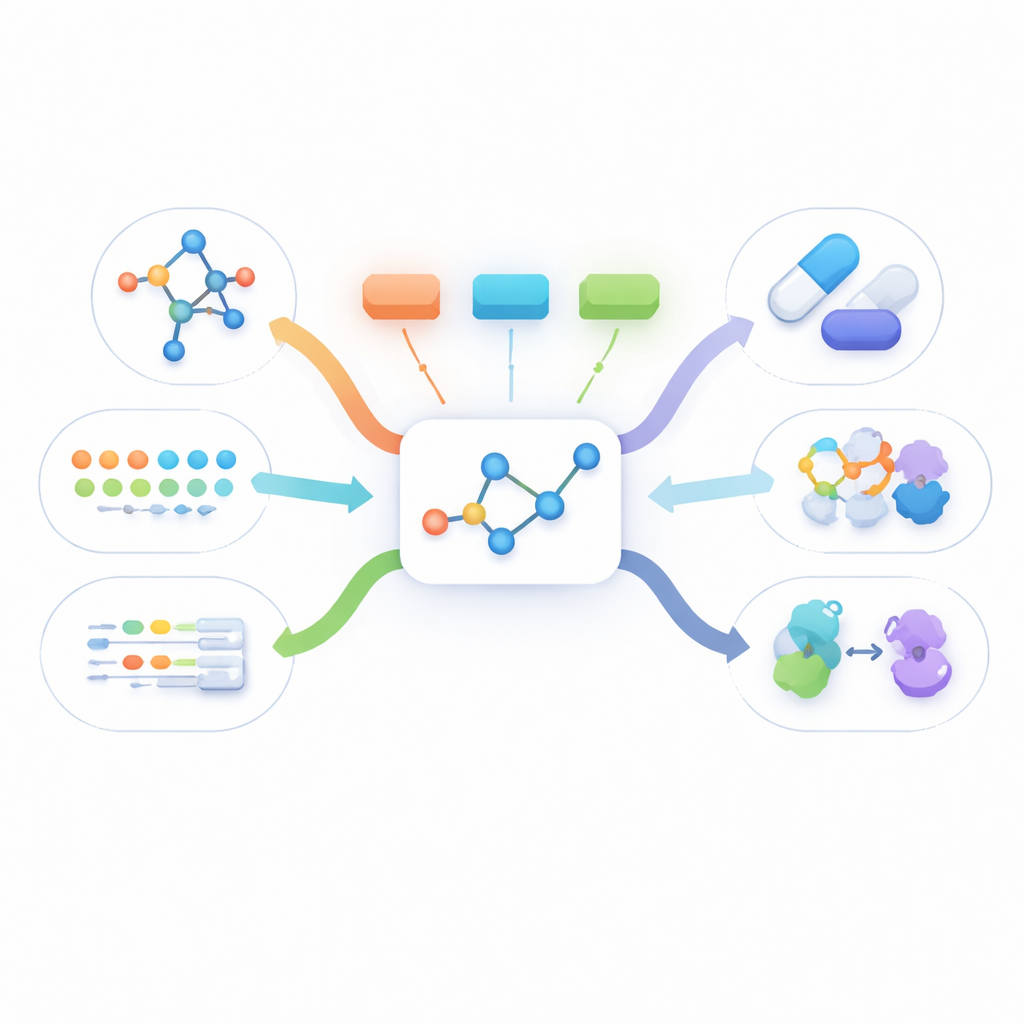
Vedere una molecola da molte angolazioni
Le informazioni reali sui farmaci arrivano in molte forme: un disegno bidimensionale delle connessioni atomiche, una forma tridimensionale, descrizioni testuali sul funzionamento del farmaco e lunghe liste di dati biologici come le proteine a cui si lega. La maggior parte dei metodi esistenti usa o una sola di queste viste o richiede che tutte siano presenti per ogni molecola durante l'addestramento. In pratica, tuttavia, l'unico dato che è quasi sempre disponibile è la semplice struttura bidimensionale. Le altre viste spesso mancano, il che impedisce ai metodi multimodali attuali di apprendere da un gran numero di molecole reali.
Insegnare a una vista a pensare come molte
M2UMol affronta questo problema trattando il grafo bidimensionale della molecola come fulcro e imparando come quella singola vista si relaziona alle altre. Durante il pre-addestramento, il sistema legge grafi 2D, forme 3D, sommari testuali e liste di caratteristiche biologiche per più di undicimila molecole simili a farmaci. Usa encoder separati per ogni tipo di dato e poi addestra "adattatori" che prendono solo il grafo 2D e generano come dovrebbero apparire i pattern 3D, testuali o biologici. Un passaggio di apprendimento contrastivo spinge i pattern generati ad avvicinarsi molto a quelli reali ogni volta che sono disponibili, anche se alcune viste mancano per alcune molecole. Un secondo compito di addestramento chiede al sistema di indovinare a quale modalità appartiene un pattern generato, aiutandolo a mantenere distinti i diversi tipi di informazione.
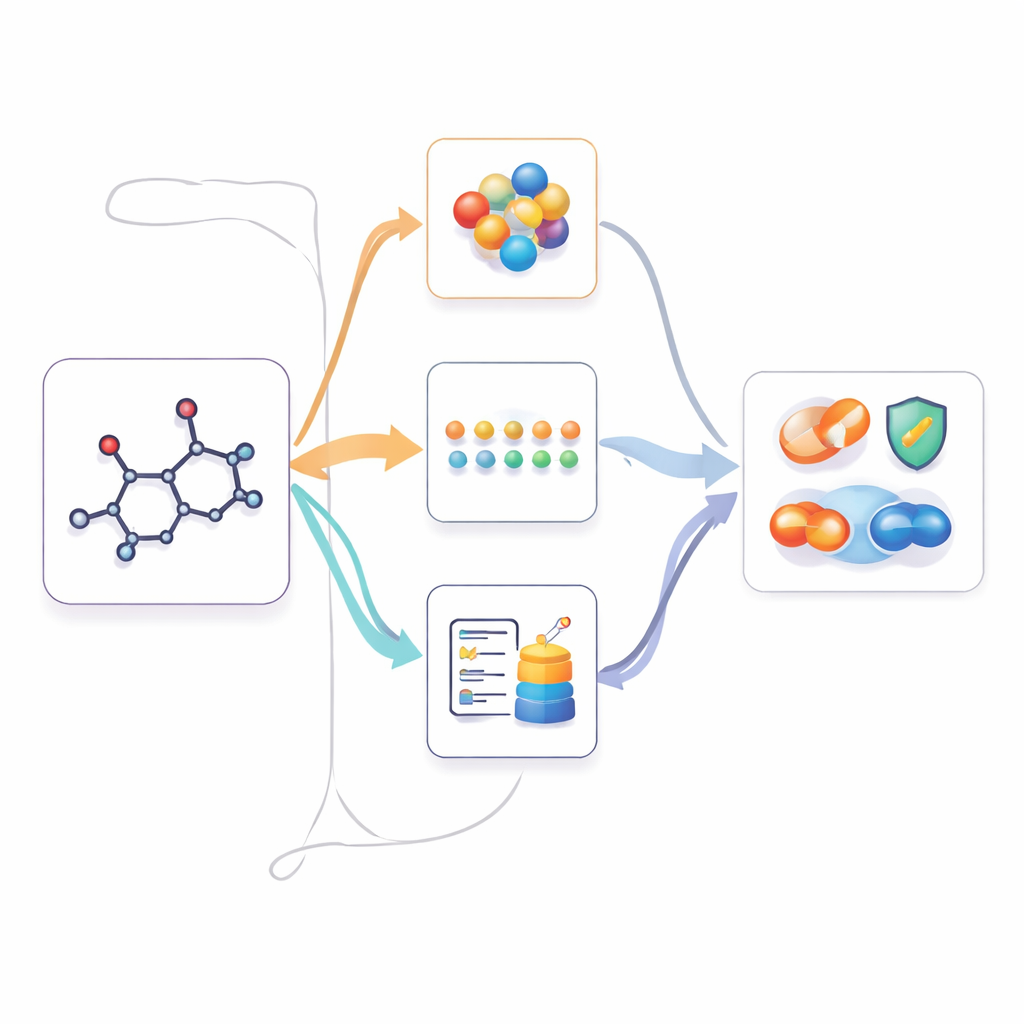
Usare la conoscenza multimodale quando è disponibile solo il 2D
Una volta che M2UMol ha appreso queste relazioni, può essere applicato a compiti pratici in cui sono fornite solo strutture 2D, come la previsione della tossicità, proprietà legate a malattie o interazioni tra farmaci. Per ogni nuova molecola, l'encoder 2D pre-addestrato produce una rappresentazione centrale e gli adattatori generano tre versioni "immaginate": una che assomiglia alla geometria 3D, una che imita la conoscenza basata su testo e una che cattura il contesto biologico. Un semplice modulo di attenzione combina poi queste quattro viste in un'impronta finale utilizzata dai predittori specifici per il compito. Questo permette al modello di comportarsi come se disponesse di ricche informazioni multimodali, mentre agli utenti è richiesto solo di fornire una struttura 2D standard.
Previsioni migliori con meno dati e ragionamenti più chiari
Su un ampio pannello di benchmark, M2UMol supera sia i modelli a vista singola sia i precedenti modelli multimodali nella previsione delle proprietà molecolari e in compiti più complessi come le interazioni farmaco–farmaco e farmaco–bersaglio. Lo fa nonostante sia pre-addestrato su poco più di undicimila molecole, utilizzando risorse di calcolo modeste, mentre molti metodi concorrenti ne utilizzano milioni. Analisi visive mostrano che le rappresentazioni apprese sono sia ben separate tra classi diverse sia distribuite in modo uniforme, segno di alto contenuto informativo. Il modello può anche evidenziare atomi e legami specifici che guidano le sue decisioni, e questi spesso corrispondono a gruppi funzionali noti responsabili di tossicità, attività su un recettore o interazioni problematiche tra farmaci.
Cosa significa per i farmaci del futuro
Per i non specialisti, l'idea chiave è che M2UMol impara a considerare un semplice disegno lineare di una molecola come se contenesse tre strati aggiuntivi di ricco contesto scientifico. Questo trucco gli consente di formulare previsioni più solide e spiegabili su come si comporterà un farmaco, anche quando dati sperimentali dettagliati non sono disponibili. Poiché è efficiente, open source e confezionato per un uso semplice, questo approccio potrebbe aiutare i ricercatori a selezionare i composti in modo più intelligente, capire perché alcuni farmaci falliscono e alla fine guidare la progettazione di nuovi medicinali con meno sorprese.
Citazione: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Parole chiave: scoperta di farmaci, apprendimento delle rappresentazioni molecolari, IA multimodale, interazioni farmacologiche, chimica computazionale