Clear Sky Science · es
Preentrenamiento de transferencia de conocimiento multimodal a unívoco para el aprendizaje de representaciones moleculares
Por qué importan los ordenadores farmacéuticos más inteligentes
Diseñar nuevos medicamentos depende cada vez más de ordenadores que puedan "entender" las moléculas. Estos programas convierten una molécula en números que un modelo puede usar para predecir seguridad, potencia o interacciones perjudiciales. El artículo presenta M2UMol, una nueva manera de entrenar esos modelos para que funcionen bien incluso cuando solo está disponible el tipo de dato molecular más común, lo que promete ayudar a químicos y médicos de forma más rápida y fiable.
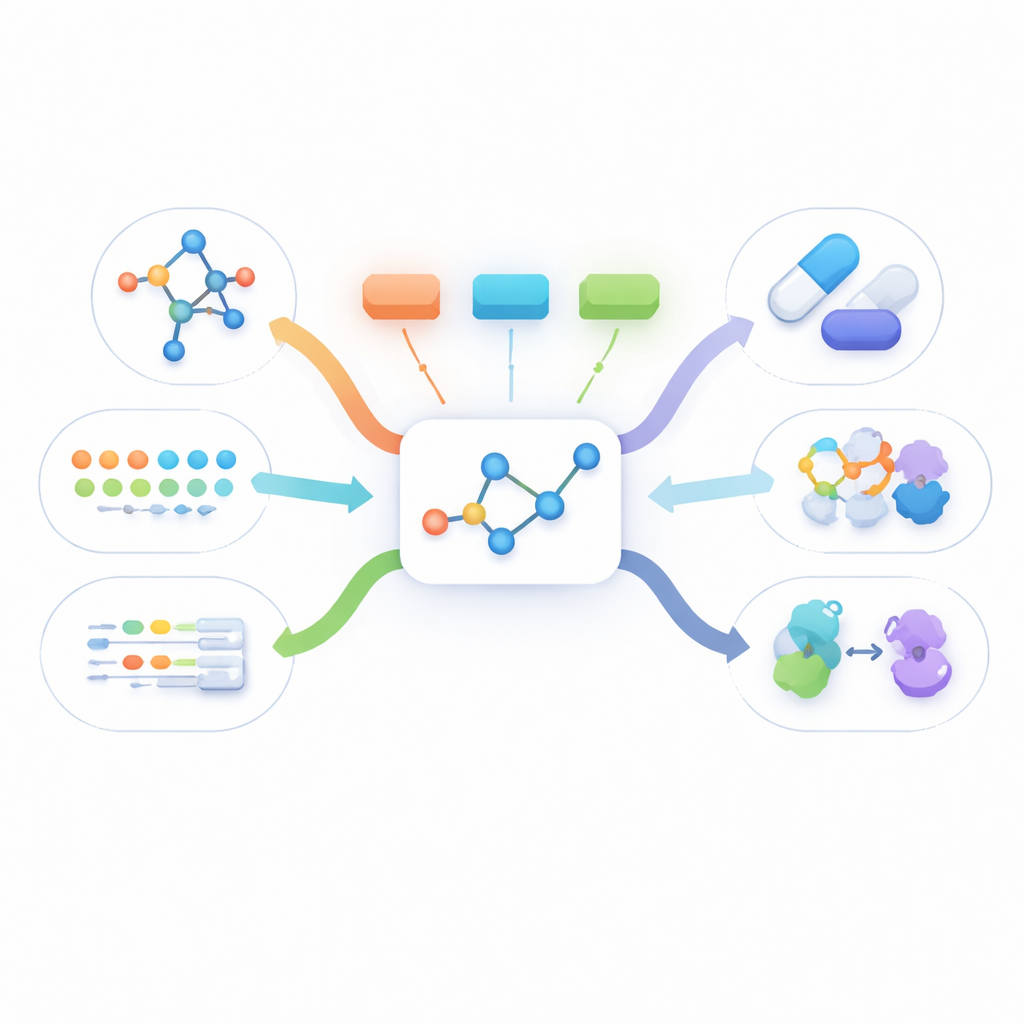
Ver una molécula desde muchos ángulos
La información real sobre fármacos viene en muchas formas: un dibujo plano de cómo se conectan los átomos, una forma tridimensional, descripciones escritas de cómo actúa el fármaco y largas listas de hechos biológicos como a qué proteínas se une. La mayoría de los métodos existentes o bien usan solo una de estas perspectivas o requieren que todas estén presentes para cada molécula durante el entrenamiento. En la práctica, sin embargo, el único dato que casi siempre está disponible es la estructura bidimensional simple. Otras vistas a menudo faltan, lo que impide que los métodos multimodales actuales aprendan a partir de grandes cantidades de moléculas del mundo real.
Enseñar a una vista a pensar como muchas
M2UMol aborda esto tratando el grafo 2D de una molécula como el eje y aprendiendo cómo esa vista única se relaciona con las demás. Durante el preentrenamiento, el sistema lee grafos 2D, formas 3D, resúmenes textuales y listas de características biológicas de más de once mil moléculas similares a fármacos. Usa codificadores separados para cada tipo de dato y luego entrena "adaptadores" que toman solo el grafo 2D y generan cómo deberían ser los patrones 3D, textuales o biológicos. Un paso de aprendizaje contrastivo empuja a que los patrones generados coincidan estrechamente con los reales siempre que estén disponibles, incluso si algunas vistas faltan para algunas moléculas. Una segunda tarea de entrenamiento pide al sistema adivinar a qué modalidad pertenece un patrón generado, lo que le ayuda a mantener distintas las distintas clases de información.
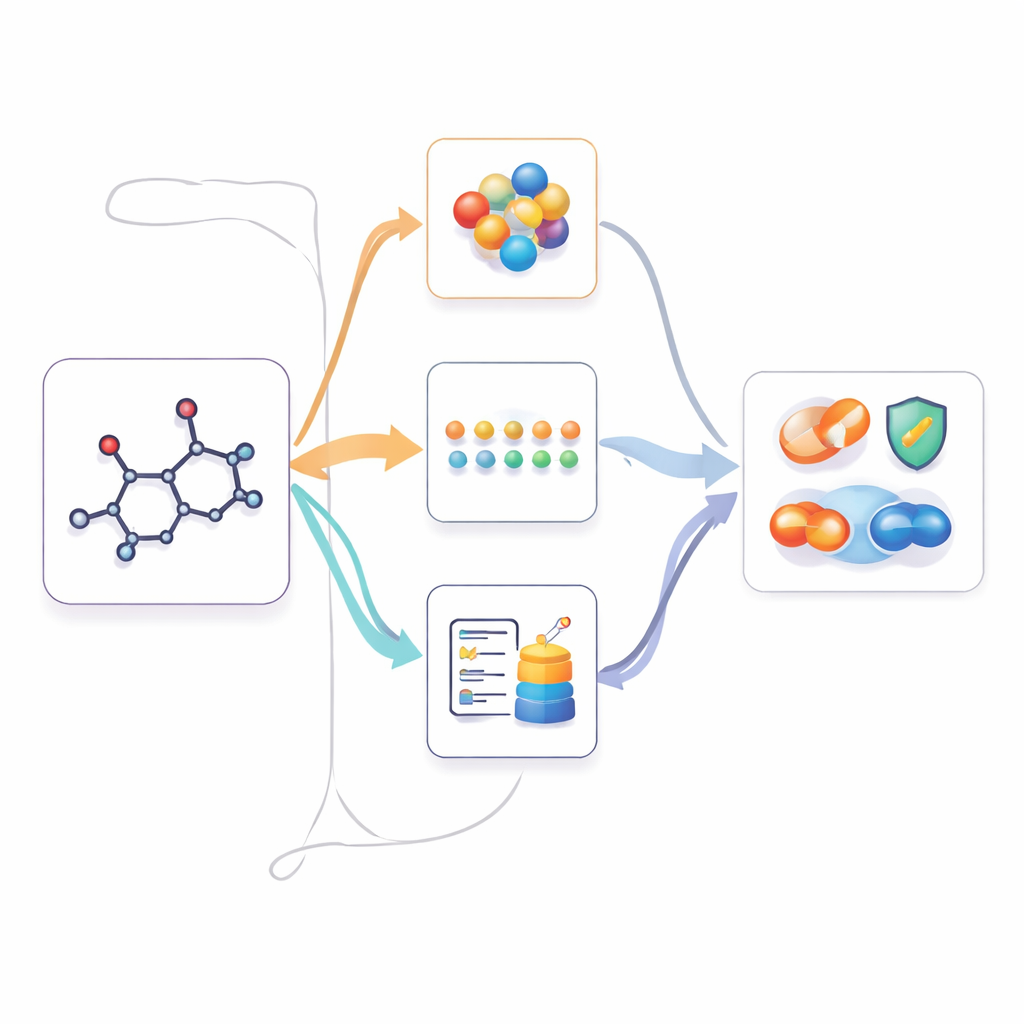
Usar conocimiento multimodal cuando solo hay 2D
Una vez que M2UMol ha aprendido estas relaciones, puede aplicarse a tareas prácticas donde solo se dan estructuras 2D, como predecir toxicidad, propiedades relacionadas con la enfermedad o interacciones entre fármacos. Para cada nueva molécula, el codificador 2D preentrenado produce una representación central, y los adaptadores generan tres versiones "imaginadas": una que se asemeja a la geometría 3D, otra que imita el conocimiento basado en texto y una que capta el contexto biológico. Un módulo de atención sencillo combina entonces estas cuatro vistas en una huella final que usan los predictores específicos de la tarea. Esto permite al modelo actuar como si contara con información multimodal rica, mientras los usuarios solo necesitan aportar una estructura 2D estándar.
Mejores predicciones con menos datos y razonamiento más claro
En un amplio conjunto de benchmarks, M2UMol supera tanto a modelos de vista única como a modelos multimodales previos en la predicción de propiedades moleculares y en tareas más complejas como interacciones fármaco–fármaco y fármaco–diana. Lo hace aunque esté preentrenado en poco más de once mil moléculas, usando recursos informáticos modestos, mientras que muchos métodos competidores emplean millones. Los análisis visuales muestran que las representaciones aprendidas están bien separadas entre diferentes clases y distribuidas de forma homogénea, señal de alto contenido informativo. El modelo también puede resaltar átomos y enlaces específicos que impulsan sus decisiones, y estos a menudo coinciden con grupos funcionales conocidos responsables de toxicidad, actividad en un receptor o interacciones problemáticas entre fármacos.
Qué significa esto para los medicamentos del futuro
Para no especialistas, la idea clave es que M2UMol aprende a pensar en un dibujo lineal simple de una molécula como si llevara tres capas extra de contexto científico rico. Ese truco le permite hacer predicciones más sólidas y explicables sobre cómo se comportará un fármaco, incluso cuando no hay datos experimentales detallados. Porque es eficiente, de código abierto y fácil de usar, este enfoque podría ayudar a los investigadores a cribar compuestos con más criterio, entender por qué fallan algunos fármacos y, eventualmente, guiar el diseño de nuevos medicamentos con menos sorpresas.
Cita: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Palabras clave: descubrimiento de fármacos, aprendizaje de representaciones moleculares, IA multimodal, interacciones de fármacos, química computacional