Clear Sky Science · pl
Przedtrening transferu wiedzy z wielu modalności do jednej dla reprezentacji molekuł
Dlaczego inteligentniejsze komputery do projektowania leków mają znaczenie
Projektowanie nowych leków coraz częściej opiera się na komputerach, które potrafią „rozumieć” molekuły. Programy te przekształcają cząsteczkę leku w liczby, które model może wykorzystać do przewidywania bezpieczeństwa, siły działania czy szkodliwych interakcji. Artykuł przedstawia M2UMol — nowy sposób trenowania takich modeli, dzięki któremu działają one dobrze nawet wtedy, gdy dostępny jest tylko najpowszechniejszy rodzaj danych molekularnych, co obiecuje szybszą i bardziej niezawodną pomoc dla chemików i lekarzy.
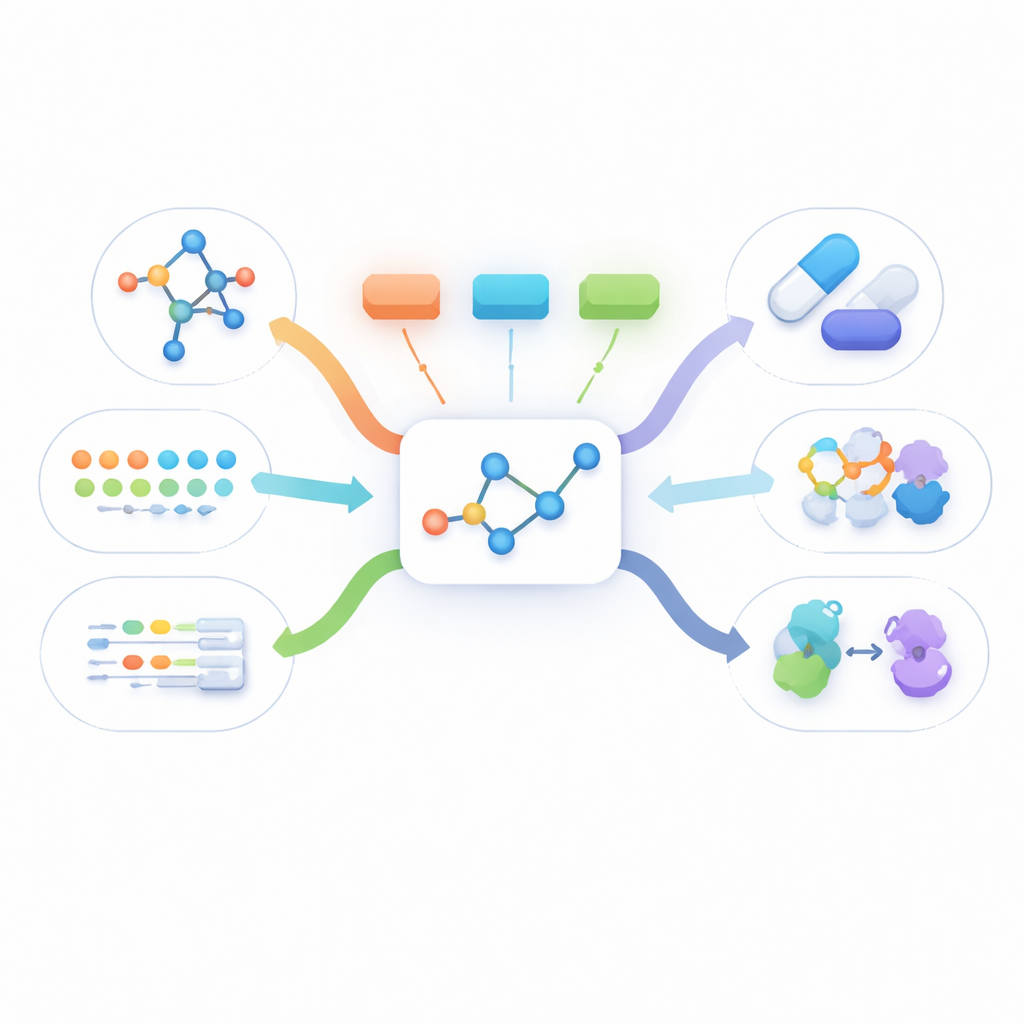
Postrzeganie molekuły z wielu perspektyw
Rzeczywiste informacje o lekach występują w wielu formach: płaskie rysunki pokazujące połączenia atomów, trójwymiarowe kształty, tekstowe opisy mechanizmu działania oraz długie listy faktów biologicznych, takich jak białka, do których się wiąże. Większość istniejących metod używa albo tylko jednego z tych widoków, albo wymaga, by wszystkie były dostępne dla każdej molekuły podczas treningu. W praktyce jednak jedynymi danymi, które niemal zawsze są dostępne, są proste struktury dwuwymiarowe. Inne widoki często brakuje, co uniemożliwia obecnym metodom multimodalnym uczenie się z dużych zbiorów rzeczywistych molekuł.
Nauczyć jeden widok myśleć jak wiele
M2UMol rozwiązuje ten problem, traktując graf 2D molekuły jako centralny punkt i ucząc się, jak ten pojedynczy widok odnosi się do pozostałych. Podczas przedtreningu system przetwarza grafy 2D, kształty 3D, streszczenia tekstowe i listy cech biologicznych dla ponad jedenaście tysięcy cząsteczek przypominających leki. Używa oddzielnych enkoderów dla każdego typu danych, a następnie trenuje „adaptery”, które biorą tylko graf 2D i generują, jak powinny wyglądać wzorce 3D, tekstowe lub biologiczne. Etap uczenia kontrastowego zachęca wygenerowane wzorce do ścisłego dopasowania do rzeczywistych, gdy tylko są dostępne, nawet jeśli niektóre widoki brakują dla niektórych molekuł. Drugie zadanie treningowe prosi system o odgadnięcie, do której modalności należy wygenerowany wzorzec, co pomaga zachować odrębność różnych rodzajów informacji.
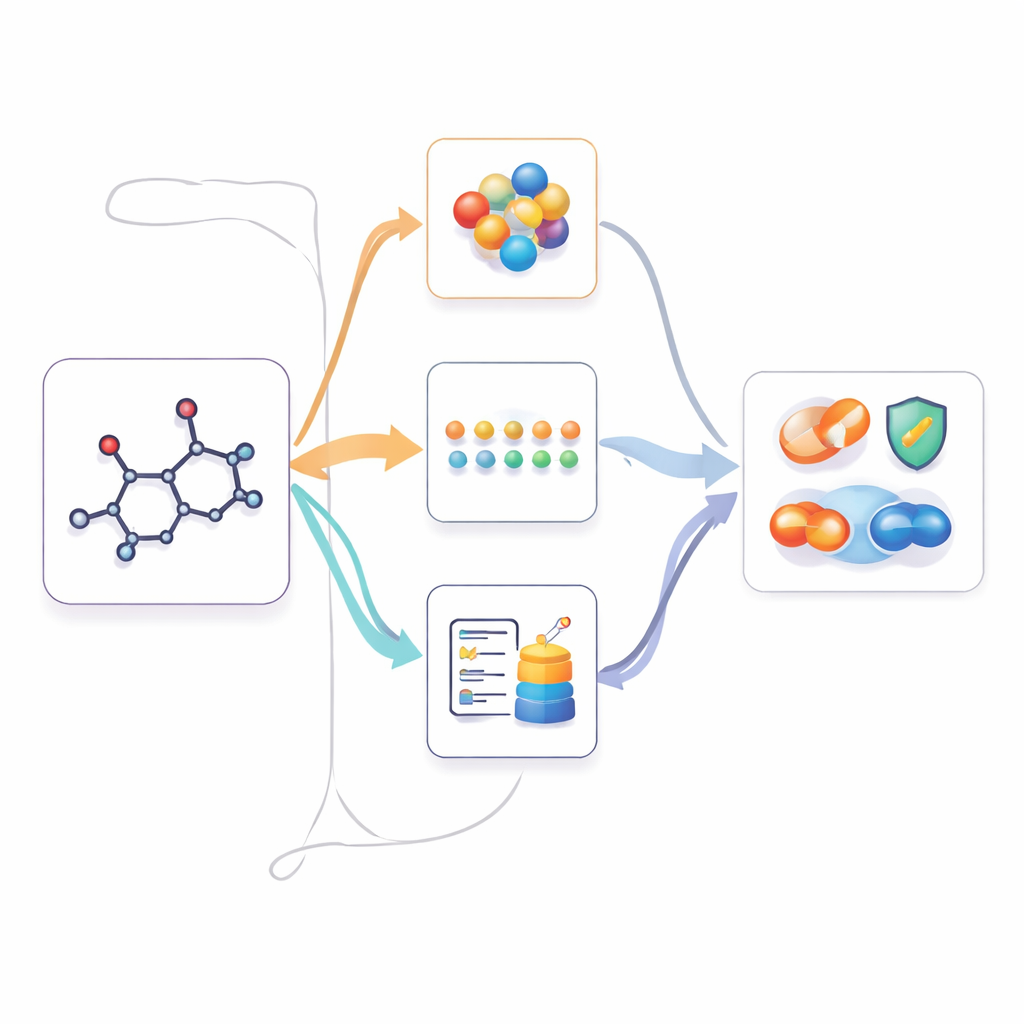
Wykorzystywanie wiedzy multimodalnej, gdy dostępne jest tylko 2D
Gdy M2UMol nauczy się tych zależności, można go zastosować w praktycznych zadaniach, w których podawane są jedynie struktury 2D, takich jak przewidywanie toksyczności, właściwości związanych z chorobami czy interakcji lek–lek. Dla każdej nowej molekuły przedtrenowany enkoder 2D wytwarza rdzeniową reprezentację, a adaptery generują trzy „wyobrażone” wersje: jedną przypominającą geometrię 3D, jedną naśladującą wiedzę tekstową i jedną oddającą kontekst biologiczny. Prosty moduł uwagi łączy następnie te cztery widoki w ostateczny odcisk palca wykorzystywany przez predyktory specyficzne dla zadania. To skutecznie pozwala modelowi zachowywać się, jakby dysponował bogatymi multimodalnymi informacjami, podczas gdy użytkownicy muszą dostarczyć jedynie standardową strukturę 2D.
Lepsze przewidywania przy mniejszych zasobach danych i jaśniejszym tłumaczeniu
W szerokim zestawie benchmarków M2UMol przewyższa zarówno modele jednowidokowe, jak i wcześniejsze modele multimodalne w przewidywaniu właściwości molekuł oraz w bardziej złożonych zadaniach, takich jak interakcje lek–lek i lek–cel. Robi to mimo że został przedtrenowany na nieco ponad jedenaście tysięcy molekuł, używając umiarkowanych zasobów obliczeniowych, podczas gdy wiele konkurencyjnych metod korzysta z milionów przykładów. Analizy wizualne pokazują, że wyuczone reprezentacje są dobrze rozdzielone między różne klasy i równomiernie rozproszone — znak wysokiej zawartości informacji. Model potrafi także wskazać konkretne atomy i wiązania, które wpływają na jego decyzje, a często odpowiadają one znanym grupom funkcyjnym odpowiedzialnym za toksyczność, aktywność względem receptora czy problematyczne interakcje między lekami.
Co to oznacza dla przyszłych leków
Dla osób niebędących specjalistami kluczowa idea jest taka, że M2UMol uczy się traktować prosty rysunek molekuły jakby niósł trzy dodatkowe warstwy bogatego kontekstu naukowego. Ten zabieg pozwala mu formułować silniejsze, bardziej wyjaśnialne przewidywania dotyczące zachowania leku, nawet gdy szczegółowe dane eksperymentalne nie są dostępne. Ponieważ jest efektywny, otwartoźródłowy i zapakowany do łatwego użycia, podejście to może pomóc badaczom mądrzej przesiewać związki, rozumieć, dlaczego niektóre leki zawodzą, i w końcu kierować projektowaniem nowych leków z mniejszą liczbą niespodzianek.
Cytowanie: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Słowa kluczowe: odkrywanie leków, uczenie reprezentacji molekularnych, AI multimodalne, interakcje leków, chemia obliczeniowa