Clear Sky Science · ru
Предобучение переноса знаний от многомодального к одномодальному для обучения представлений молекул
Почему умные «лекарственные» компьютеры важны
Проектирование новых лекарств всё больше опирается на компьютеры, которые могут «понимать» молекулы. Эти программы превращают молекулу в числовое представление, которое модель использует для предсказания безопасности, эффективности или вредных взаимодействий. В статье предлагается M2UMol — новый способ предобучения таких моделей, который позволяет им хорошо работать даже при наличии только наиболее распространённого типа данных о молекулах, что обещает более быстрые и надёжные инструменты для химиков и врачей.
Видеть молекулу с разных сторон
Реальная информация о препарате представлена в разных формах: плоской диаграммой связей между атомами, трёхмерной формой, текстовыми описаниями механизма действия и длинными списками биологических свойств, например, с какими белками он связывается. Большинство существующих методов либо используют только один из этих видов, либо требуют, чтобы все они были доступны для каждой молекулы при обучении. На практике же почти всегда доступна лишь простая двумерная структура. Другие представления часто отсутствуют, что мешает текущим мультимодальным методам учиться на большом числе реальных молекул.
Обучить один вид мыслить как многие
M2UMol решает эту проблему, рассматривая двумерный граф молекулы как «ядро» и изучая, как эта единственная версия соотносится с остальными. Во время предобучения система обрабатывает 2D-графы, 3D-формы, текстовые резюме и биологические списки более одиннадцати тысяч молекул, похожих на лекарственные соединения. Для каждого типа данных используются отдельные энкодеры, после чего обучаются «адаптеры», которые по 2D-графу генерируют, как должны выглядеть 3D-, текстовые или биологические представления. Контрастивный этап обучения подтягивает сгенерированные представления к реальным, когда они доступны, даже если для некоторых молекул какие-то виды отсутствуют. Вторая задача заставляет систему угадывать, к какой модальности относится сгенерированное представление, что помогает сохранять различия между видами информации.
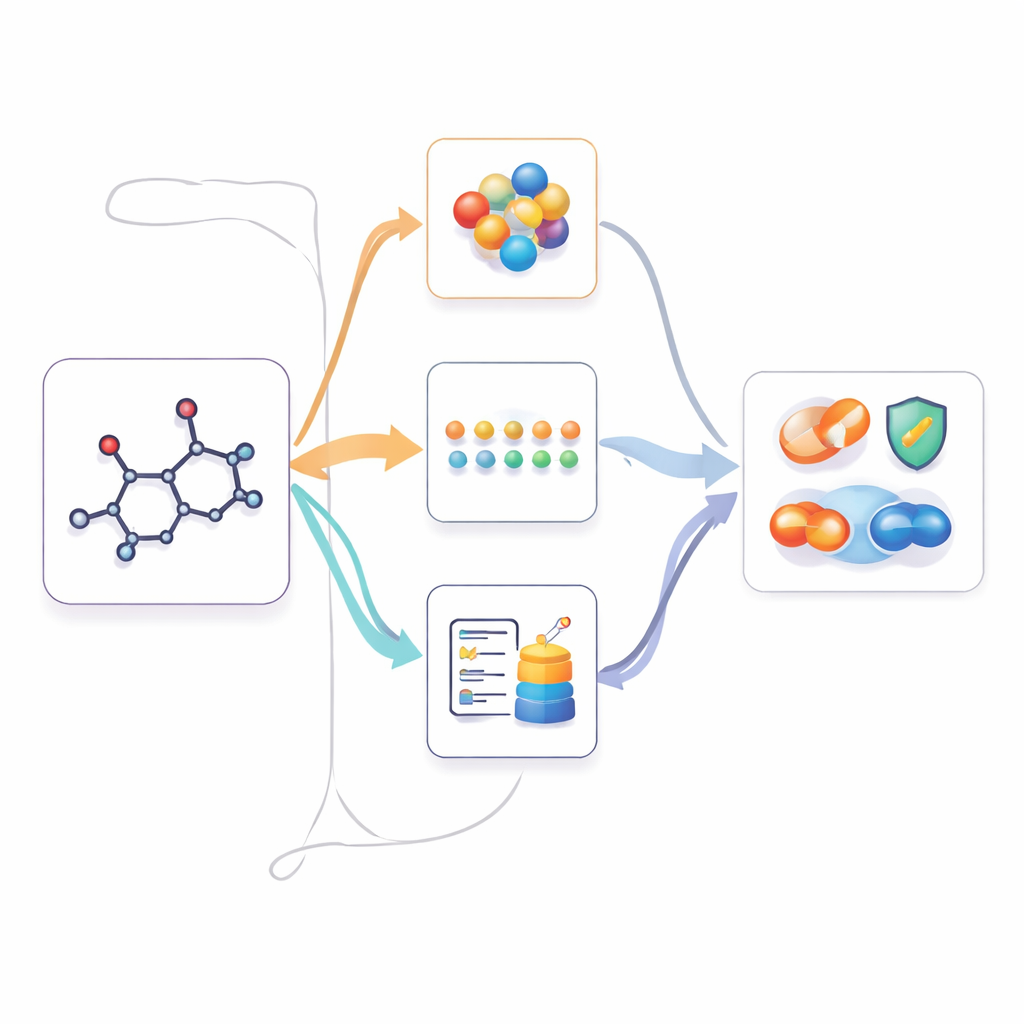
Использование мультимодальных знаний при наличии только 2D
Когда M2UMol изучил эти связи, его можно применять к практическим задачам, где доступны лишь 2D-структуры — например, предсказание токсичности, свойств, связанных с заболеваниями, или взаимодействий лекарств. Для каждой новой молекулы предобученный 2D-энкодер формирует основное представление, а адаптеры создают три «воображаемые» версии: одну, напоминающую 3D-геометрию, одну, имитирующую текстовые знания, и одну, передающую биологический контекст. Простой модуль внимания затем объединяет эти четыре вида в итоговый отпечаток, который используют предикторы для конкретных задач. Это фактически позволяет модели действовать так, как будто у неё есть богатая мультимодальная информация, в то время как пользователю требуется лишь стандартная 2D-структура.
Лучшие прогнозы при меньших объёмах данных и более понятное обоснование
По широкому набору бенчмарков M2UMol превосходит как однотипные, так и предыдущие мультимодальные модели в предсказании свойств молекул и в более сложных задачах, таких как взаимодействия лекарств между собой и с мишенями. Он достигает этого, хотя предобучен всего на чуть более чем одиннадцати тысячах молекул с умеренными вычислительными ресурсами, тогда как многие конкуренты используют миллионы. Визуальные анализы показывают, что полученные представления хорошо разделены по классам и равномерно распределены — признак высокой информативности. Модель также может выделять конкретные атомы и связи, которые влияют на её решения, и эти указания часто совпадают с известными функциональными группами, отвечающими за токсичность, активность на рецепторе или проблемные взаимодействия между препаратами.
Что это значит для будущих лекарств
Для неспециалистов ключевая идея такова: M2UMol учится рассматривать простую линейную схему молекулы так, будто она содержит три дополнительных слоя богатого научного контекста. Этот приём позволяет давать более сильные и объяснимые прогнозы о поведении препарата, даже когда подробные экспериментальные данные недоступны. Поскольку метод эффективен, имеет открытый исходный код и упакован для удобного использования, он может помочь исследователям более разумно отбирать соединения, понять, почему некоторые лекарства проваливаются, и в конечном счёте направлять создание новых препаратов с меньшим числом неожиданных проблем.
Цитирование: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Ключевые слова: поиск лекарств, обучение представлений молекул, мультимодальный ИИ, взаимодействия лекарств, вычислительная химия