Clear Sky Science · de
Multi-to-uni modal Knowledge-Transfer-Pretraining für molekulare Repräsentationslernverfahren
Warum intelligentere Arzneimittel‑Computer wichtig sind
Die Entwicklung neuer Medikamente hängt zunehmend von Computern ab, die Moleküle „verstehen“ können. Diese Programme wandeln ein Wirkstoffmolekül in Zahlen um, die ein Modell nutzen kann, um Sicherheit, Wirksamkeit oder schädliche Wechselwirkungen vorherzusagen. Die Arbeit stellt M2UMol vor, eine neue Methode zum Vortrainieren solcher Modelle, damit sie auch dann gut funktionieren, wenn nur die am häufigsten verfügbare Art von Molekülinformation vorliegt. Das verspricht schnellere und verlässlichere Unterstützung für Chemiker und Mediziner.
Ein Molekül aus vielen Blickwinkeln sehen
Echte Wirkstoffinformationen liegen in vielen Formen vor: eine zweidimensionale Zeichnung, die zeigt, wie Atome verbunden sind, eine dreidimensionale Gestalt, textliche Beschreibungen der Wirkungsweise und lange Listen biologischer Fakten wie gebundene Proteine. Die meisten bestehenden Methoden nutzen entweder nur eine dieser Sichten oder benötigen, dass alle Sichten für jedes Molekül während des Trainings vorhanden sind. In der Praxis ist jedoch meist nur die einfache zweidimensionale Struktur fast immer verfügbar. Andere Sichten fehlen oft, was aktuelle multimodale Ansätze daran hindert, aus großen Mengen realer Moleküle zu lernen.
Eine Ansicht so lehren, wie viele zu denken
M2UMol geht dieses Problem an, indem es den zweidimensionalen Graphen eines Moleküls als Zentrum betrachtet und lernt, wie diese einzelne Sicht zu den anderen in Beziehung steht. Während des Vortrainings liest das System 2D‑Graphen, 3D‑Strukturen, Textzusammenfassungen und biologische Merkmalslisten für mehr als elftausend wirkstoffähnliche Moleküle. Es verwendet separate Encoder für jede Datenart und trainiert dann „Adapter“, die nur den 2D‑Graphen nutzen, um zu erzeugen, wie 3D‑, Text‑ oder biologische Muster aussehen sollten. Ein kontrastiver Lernschritt drängt die erzeugten Muster, die echten möglichst nahe zu kommen, wann immer sie verfügbar sind, auch wenn einige Sichten für bestimmte Moleküle fehlen. Eine zweite Trainingsaufgabe fordert das System auf zu raten, zu welcher Modalität ein erzeugtes Muster gehört, was ihm hilft, die verschiedenen Informationsarten auseinanderzuhalten.
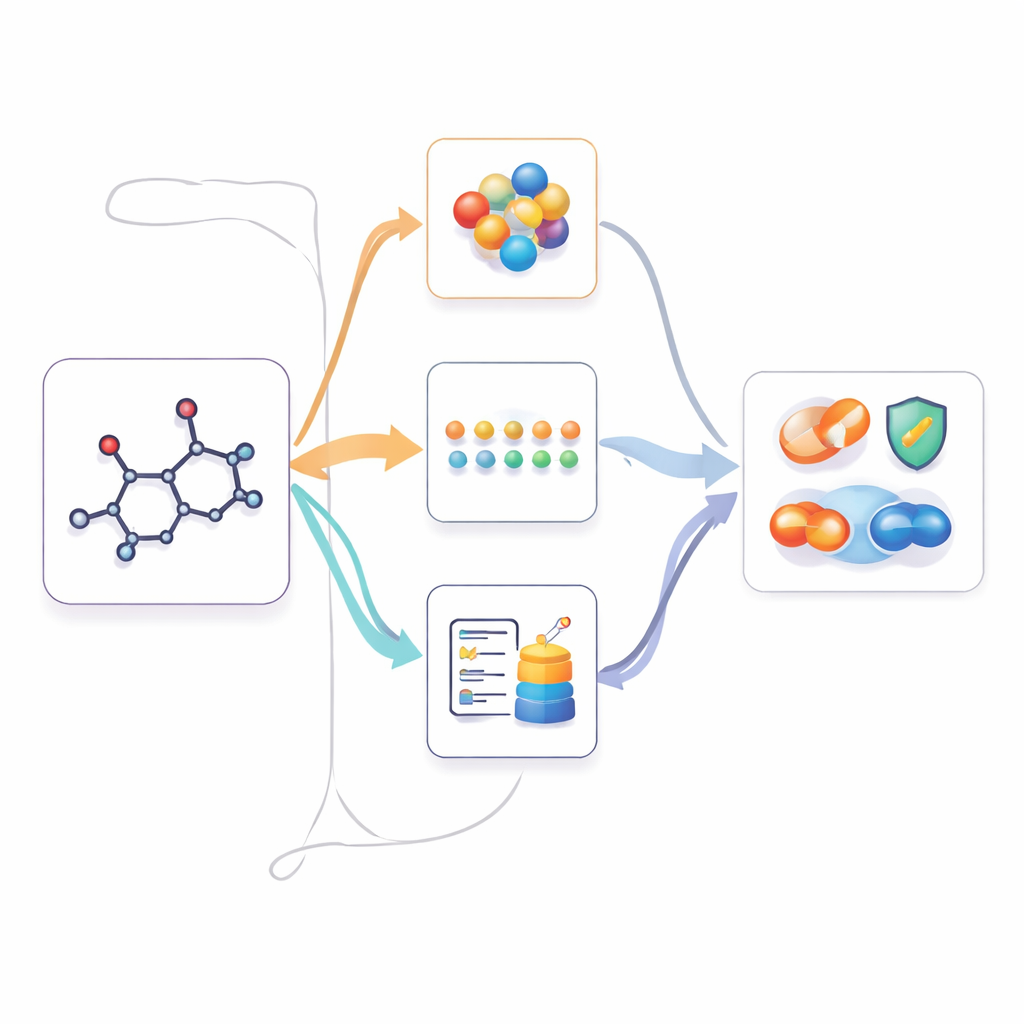
Multimodales Wissen nutzen, wenn nur 2D vorliegt
Sobald M2UMol diese Beziehungen erlernt hat, lässt es sich auf praktische Aufgaben anwenden, bei denen nur 2D‑Strukturen vorliegen, wie etwa Vorhersagen zu Toxizität, krankheitsrelevanten Eigenschaften oder Arzneimittelwechselwirkungen. Für jedes neue Molekül erzeugt der vortrainierte 2D‑Encoder eine Kernrepräsentation, und die Adapter produzieren drei „vorgestellte“ Versionen: eine, die der 3D‑Geometrie ähnelt, eine, die textbasiertes Wissen nachahmt, und eine, die biologischen Kontext einfängt. Ein einfacher Attention‑Mechanismus kombiniert diese vier Sichten zu einem finalen Fingerabdruck, der von aufgabenspezifischen Prädiktoren verwendet wird. Damit kann das Modell faktisch so agieren, als stünde ihm reichhaltige multimodale Information zur Verfügung, während Nutzerinnen und Nutzer nur eine standardisierte 2D‑Struktur bereitstellen müssen.
Bessere Vorhersagen mit weniger Daten und klarerer Begründung
In einem breiten Benchmark‑Set übertrifft M2UMol sowohl Ein-Sichten‑Modelle als auch frühere multimodale Ansätze bei der Vorhersage molekularer Eigenschaften und bei komplexeren Aufgaben wie Arzneimittel–Arzneimittel‑ und Arzneimittel–Ziel‑Interaktionen. Das gelingt, obwohl es nur auf etwas mehr als elftausend Molekülen vortrainiert wurde und moderate Rechenressourcen nutzt, während viele konkurrierende Methoden Millionen verwenden. Visuelle Analysen zeigen, dass die gelernten Repräsentationen sowohl gut zwischen verschiedenen Klassen getrennt als auch gleichmäßig verteilt sind — ein Hinweis auf hohen Informationsgehalt. Das Modell kann zudem spezifische Atome und Bindungen hervorheben, die seine Entscheidungen antreiben, und diese stimmen häufig mit bekannten funktionellen Gruppen überein, die für Toxizität, Rezeptoraktivität oder problematische Wechselwirkungen verantwortlich sind.
Was das für zukünftige Medikamente bedeutet
Für Nicht‑Fachleute ist die Kernidee, dass M2UMol lernt, eine einfache Strichzeichnung eines Moleküls so zu behandeln, als trüge sie drei zusätzliche Schichten reichhaltigen wissenschaftlichen Kontexts. Dieser Trick ermöglicht stärkere, besser erklärbare Vorhersagen über das Verhalten eines Wirkstoffs, selbst wenn detaillierte experimentelle Daten fehlen. Da die Methode effizient, Open Source und benutzerfreundlich verpackt ist, könnte sie Forschende dabei unterstützen, Verbindungen zielgerichteter zu screenen, zu verstehen, warum einige Medikamente scheitern, und letztlich die Entwicklung neuer Medikamente mit weniger Überraschungen zu lenken.
Zitation: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Schlüsselwörter: Arzneimittelentdeckung, molekulare Repräsentationslernen, multimodale KI, Arzneimittelwechselwirkungen, computationale Chemie