Clear Sky Science · sv
Flera-till-en modal kunskapsöverföringsför-träning för molekylär representationsinlärning
Varför smartare läkemedelsdatorer spelar roll
Att ta fram nya läkemedel bygger alltmer på datorer som kan ”förstå” molekyler. Dessa program omvandlar en läkemedelsmolekyl till siffror som en modell kan använda för att förutsäga säkerhet, effekt eller skadliga interaktioner. Artikeln presenterar M2UMol, ett nytt sätt att träna sådana modeller så att de fungerar bra även när endast den vanligaste typen av molekyldata finns tillgänglig, vilket lovar snabbare och mer pålitligt stöd för kemister och läkare.
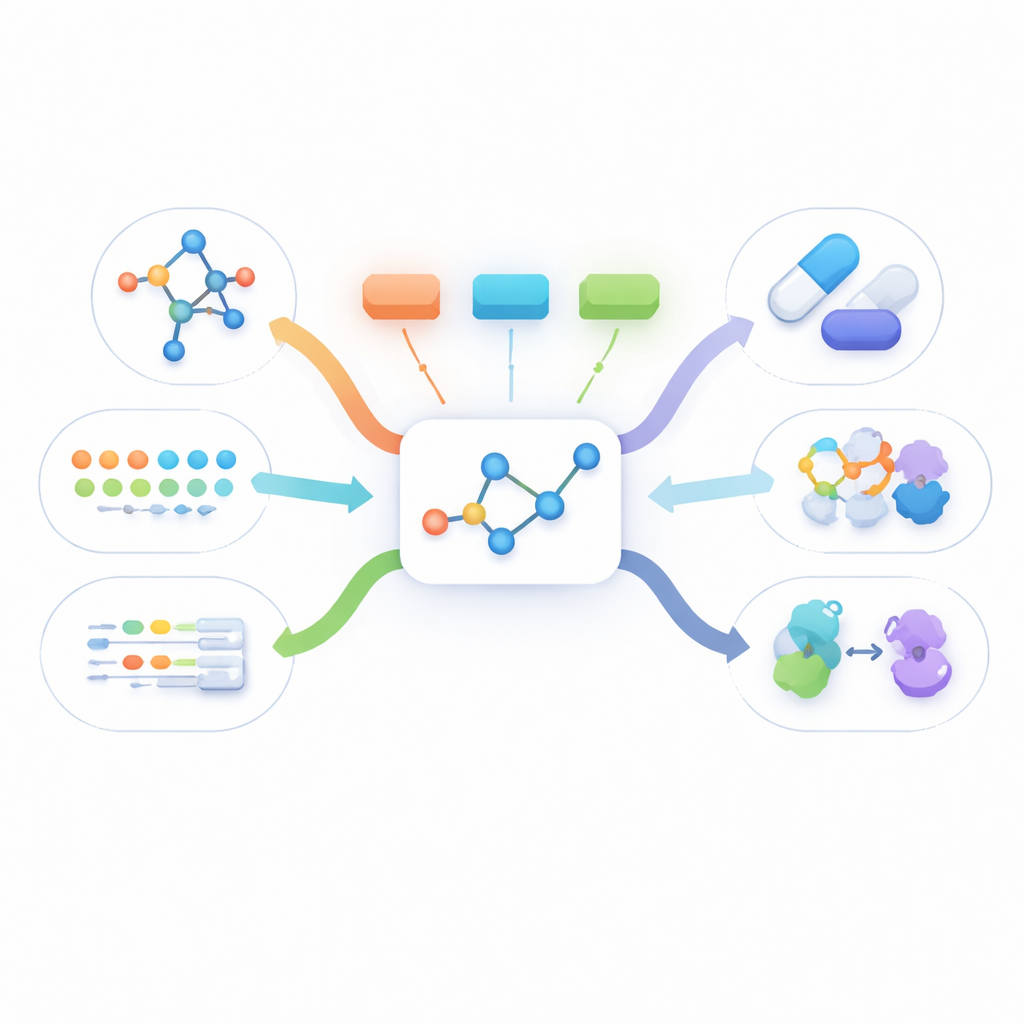
Se en molekyl ur många vinklar
Verklig läkemedelsinformation förekommer i många former: en platt ritning av hur atomerna är kopplade, en tredimensionell form, skriftliga beskrivningar av hur läkemedlet verkar och långa listor med biologiska fakta som vilka proteiner det binder till. De flesta befintliga metoder använder antingen bara en av dessa vyer eller kräver att alla är närvarande för varje molekyl under träningen. I praktiken är den enda data som nästan alltid finns tillgänglig den enkla tvådimensionella strukturen. Andra vyer saknas ofta, vilket hindrar nuvarande multimodala metoder från att lära av stora mängder verkliga molekyler.
Att lära en vy att tänka som flera
M2UMol tar itu med detta genom att behandla den tvådimensionella grafen av en molekyl som navet och lära sig hur den enskilda vyn förhåller sig till de andra. Under för-träningen läser systemet 2D-grafer, 3D-former, textsammanfattningar och biologiska funktionslistor för mer än elvatusen läkemedelslika molekyler. Det använder separata kodare för varje datatyp och tränar sedan ”adapterar” som tar endast 2D-grafen och genererar hur 3D-, text- eller biologiska mönster borde se ut. Ett kontrastivt inlärningssteg pressar de genererade mönstren att noggrant matcha de verkliga när de finns tillgängliga, även om vissa vyer saknas för vissa molekyler. En andra träningsuppgift ber systemet gissa vilken modalitet ett genererat mönster tillhör, vilket hjälper det att hålla de olika informationsslagen åtskilda.
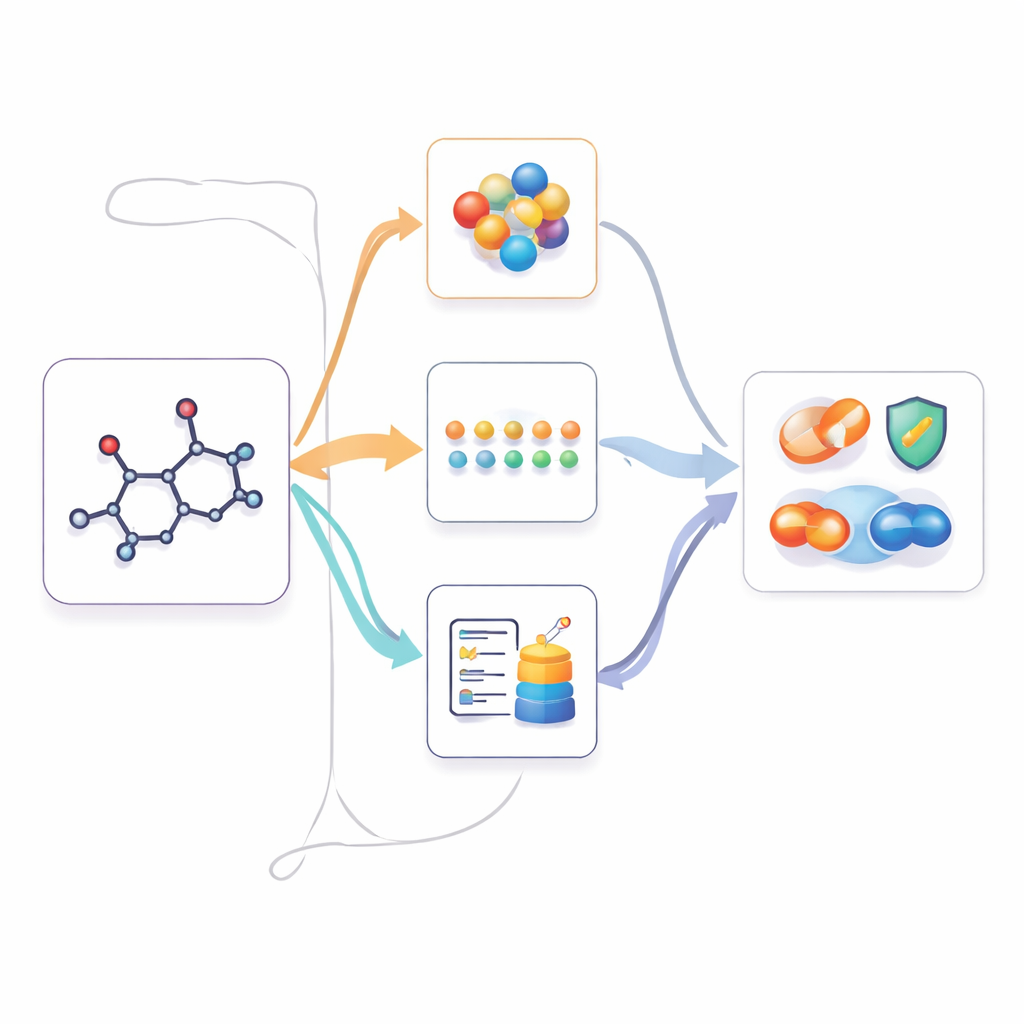
Använda multimodal kunskap när endast 2D finns
När M2UMol lärt sig dessa relationer kan det tillämpas på praktiska uppgifter där endast 2D-strukturer ges, såsom att förutsäga toxicitet, sjukdomsrelaterade egenskaper eller läkemedelsinteraktioner. För varje ny molekyl producerar den förtränade 2D-kodaren en kärnrepresentation, och adapterarna skapar tre ”föreställda” versioner: en som liknar 3D-geometri, en som efterliknar textbaserad kunskap och en som fångar biologisk kontext. En enkel attention-modul kombinerar sedan dessa fyra vyer till ett slutligt fingeravtryck som används av uppgiftsspecifika prediktorer. Detta låter modellen agera som om den hade rik multimodal information, medan användare endast behöver tillhandahålla en standard 2D-struktur.
Bättre förutsägelser med mindre data och tydligare förklaringar
Över en bred panel av benchmarks överträffar M2UMol både enkelvys- och tidigare multimodala modeller i att förutsäga molekylära egenskaper och i mer komplexa uppgifter som läkemedels–läkemedels- och läkemedels–målinteraktioner. Den gör detta trots att den förtränats på strax över elvatusen molekyler, med måttliga datorkrav, medan många konkurrerande metoder använder miljontals. Visuella analyser visar att de lärda representationerna både är väl åtskilda mellan olika klasser och jämnt utspridda, ett tecken på hög informationsinnehåll. Modellen kan också lyfta fram specifika atomer och bindningar som driver dess beslut, och dessa matchar ofta kända funktionella grupper som ligger bakom toxicitet, aktivitet vid en receptor eller problematiska interaktioner mellan läkemedel.
Vad detta betyder för framtidens läkemedel
För icke-specialister är huvudidén att M2UMol lär sig att betrakta en enkel linjeteckning av en molekyl som om den bar tre extra lager av rik vetenskaplig kontext. Denna finess gör att den kan göra starkare, mer förklarliga förutsägelser om hur ett läkemedel kommer att bete sig, även när detaljerade experimentdata saknas. Eftersom den är effektiv, öppen källkod och paketerad för enkel användning, kan denna metod hjälpa forskare att sålla förenklat bland föreningar, förstå varför vissa läkemedel misslyckas och så småningom vägleda designen av nya läkemedel med färre överraskningar.
Citering: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Nyckelord: Läkemedelsupptäckt, Molekylär representationsinlärning, Multimodal AI, Läkemedelsinteraktioner, Beräkningskemi