Clear Sky Science · nl
Multi-to-uni modal kennisoverdracht voor pre-training van moleculaire representatieleren
Waarom slimmere computers voor geneesmiddelen ertoe doen
Het ontwerpen van nieuwe geneesmiddelen hangt steeds vaker af van computers die moleculen kunnen "begrijpen". Deze programma’s zetten een geneesmiddelmolecuul om in cijfers die een model kan gebruiken om veiligheid, werkzaamheid of schadelijke interacties te voorspellen. Het artikel introduceert M2UMol, een nieuwe manier om zulke modellen te trainen zodat ze goed functioneren zelfs wanneer alleen het meest voorkomende soort molecuulgegevens beschikbaar is, wat sneller en betrouwbaarder hulp voor chemici en artsen belooft.
Een molecuul vanuit veel invalshoeken bekijken
Werkelijke informatie over geneesmiddelen komt in vele vormen: een vlakke tekening van hoe atomen verbonden zijn, een driedimensionale vorm, geschreven beschrijvingen van hoe het middel werkt, en lange lijsten met biologische feiten zoals welke eiwitten het bindt. De meeste bestaande methoden gebruiken ofwel slechts één van deze gezichtspunten, of vereisen dat ze allemaal voor elk molecuul tijdens training aanwezig zijn. In de praktijk is echter de enige gegevensvorm die vrijwel altijd beschikbaar is de eenvoudige tweedimensionale structuur. Andere gezichtspunten ontbreken vaak, wat huidige multimodale methoden verhindert om van grote aantallen echte moleculen te leren.
De ene weergave leren denken als vele
M2UMol pakt dit aan door de tweedimensionale graaf van een molecuul als knooppunt te beschouwen en te leren hoe die ene weergave zich verhoudt tot de anderen. Tijdens pre-training leest het systeem 2D-grafen, 3D-vormen, tekstsamenvattingen en biologische featurenlijsten voor meer dan elfduizend geneesmiddelachtige moleculen. Het gebruikt aparte encoders voor elk type gegevens en traint vervolgens "adapters" die alleen de 2D-graaf nemen en genereren hoe de 3D-, tekst- of biologische patronen eruit zouden moeten zien. Een contrastive learning-stap duwt de gegenereerde patronen om nauw aan te sluiten bij de echte wanneer die beschikbaar zijn, zelfs als voor sommige moleculen sommige gezichtspunten ontbreken. Een tweede trainingsopdracht vraagt het systeem te raden tot welke modaliteit een gegenereerd patroon behoort, wat helpt de verschillende soorten informatie gescheiden te houden.
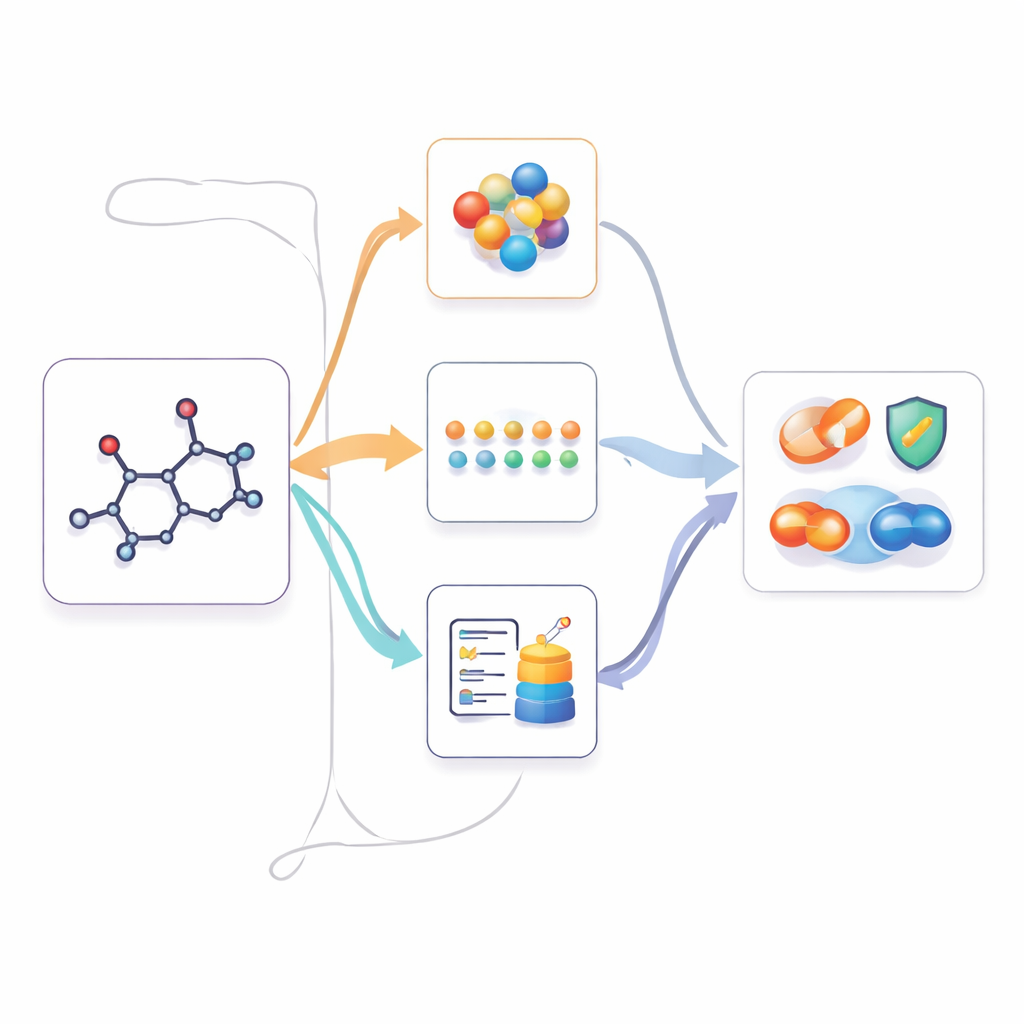
Multimodale kennis gebruiken wanneer alleen 2D beschikbaar is
Zodra M2UMol deze relaties heeft geleerd, kan het worden toegepast op praktische taken waar alleen 2D-structuren worden aangeleverd, zoals het voorspellen van toxiciteit, ziektegerelateerde eigenschappen of geneesmiddelinteracties. Voor elk nieuw molecuul produceert de voorgetrainde 2D-encoder een kernrepresentatie, en de adapters genereren drie "verbeelde" versies: één die lijkt op 3D-geometrie, één die tekstgebaseerde kennis nabootst en één die biologische context vastlegt. Een eenvoudige attentiemodule combineert deze vier gezichtspunten vervolgens tot een uiteindelijke vingerafdruk die door taak-specifieke voorspellers wordt gebruikt. Dit laat het model effectief handelen alsof het over rijke multimodale informatie beschikt, terwijl gebruikers alleen een standaard 2D-structuur hoeven te leveren.
Betere voorspellingen met minder data en duidelijkere verklaring
Over een breed scala aan benchmarks presteert M2UMol beter dan zowel enkelvoudige-weergave- als eerdere multimodale modellen bij het voorspellen van moleculaire eigenschappen en bij complexere taken zoals geneesmiddel–geneesmiddel- en geneesmiddel–doelwitinteracties. Het doet dit hoewel het slechts op iets meer dan elfduizend moleculen is voorgetraind, met bescheiden rekenmiddelen, terwijl veel concurrerende methoden miljoenen gebruiken. Visuele analyses tonen aan dat de geleerde representaties zowel goed gescheiden zijn tussen verschillende klassen als gelijkmatig verspreid — een teken van hoge informatie-inhoud. Het model kan ook specifieke atomen en bindingen benadrukken die zijn beslissingen sturen, en deze komen vaak overeen met bekende functionele groepen die verantwoordelijk zijn voor toxiciteit, activiteit bij een receptor of problematische interacties tussen geneesmiddelen.
Wat dit betekent voor toekomstige geneesmiddelen
Voor niet-specialisten is het kernidee dat M2UMol leert om over een eenvoudige lijntrekking van een molecuul te denken alsof die drie extra lagen rijke wetenschappelijke context draagt. Die truc maakt sterkere, beter verklaarbare voorspellingen mogelijk over hoe een geneesmiddel zich zal gedragen, zelfs wanneer gedetailleerde experimentele gegevens ontbreken. Omdat het efficiënt, open-source en gebruiksklaar verpakt is, kan deze benadering onderzoekers helpen verbindingen verstandiger te screenen, te begrijpen waarom sommige geneesmiddelen falen en uiteindelijk het ontwerp van nieuwe geneesmiddelen gidsen met minder onaangename verrassingen.
Bronvermelding: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Trefwoorden: medicijnontwikkeling, moleculair representatieleren, multimodale AI, geneesmiddelinteracties, computationale chemie