Clear Sky Science · pt
Pré-treinamento de transferência de conhecimento modal multi-para-uni para aprendizado de representação molecular
Por que computadores mais inteligentes para fármacos importam
O desenho de novos medicamentos depende cada vez mais de computadores capazes de “entender” moléculas. Esses programas transformam uma molécula farmacêutica em números que um modelo pode usar para prever segurança, potência ou interações nocivas. O artigo apresenta o M2UMol, uma nova forma de treinar esses modelos para que funcionem bem mesmo quando apenas o tipo de dado molecular mais comum está disponível, prometendo ajuda mais rápida e confiável para químicos e médicos.
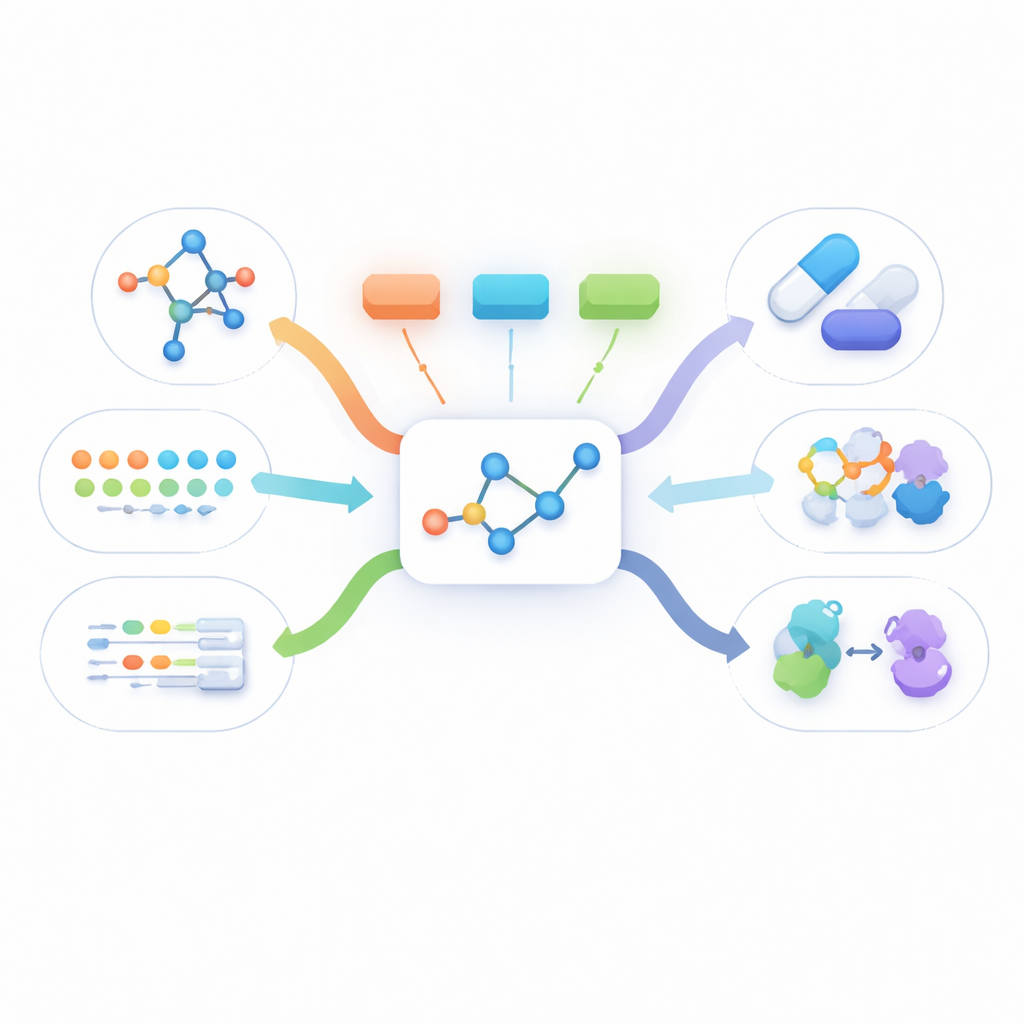
Ver uma molécula de muitos ângulos
Informações reais sobre medicamentos aparecem de várias formas: um desenho plano de como os átomos se conectam, uma forma tridimensional, descrições escritas de como o fármaco atua e longas listas de fatos biológicos, como as proteínas às quais se liga. A maioria dos métodos existentes ou usa apenas uma dessas visões ou exige que todas elas estejam presentes para cada molécula durante o treinamento. Na prática, contudo, o único dado quase sempre disponível é a estrutura bidimensional simples. Outras visões costumam estar ausentes, o que impede que os métodos multimodais atuais aprendam a partir de grandes quantidades de moléculas do mundo real.
Ensinar uma visão a pensar como muitas
O M2UMol aborda isso tratando o grafo bidimensional da molécula como o núcleo e aprendendo como essa única visão se relaciona com as demais. Durante o pré-treinamento, o sistema processa grafos 2D, formas 3D, resumos em texto e listas de características biológicas de mais de onze mil moléculas com características farmacêuticas. Ele usa codificadores separados para cada tipo de dado e então treina “adaptadores” que tomam apenas o grafo 2D e geram como deveriam ser os padrões 3D, textuais ou biológicos. Uma etapa de aprendizado contrastivo empurra os padrões gerados para coincidir de perto com os reais sempre que estão disponíveis, mesmo que algumas visões faltem para certas moléculas. Uma segunda tarefa de treinamento pede ao sistema que adivinhe a qual modalidade um padrão gerado pertence, ajudando a manter os diferentes tipos de informação distintos.
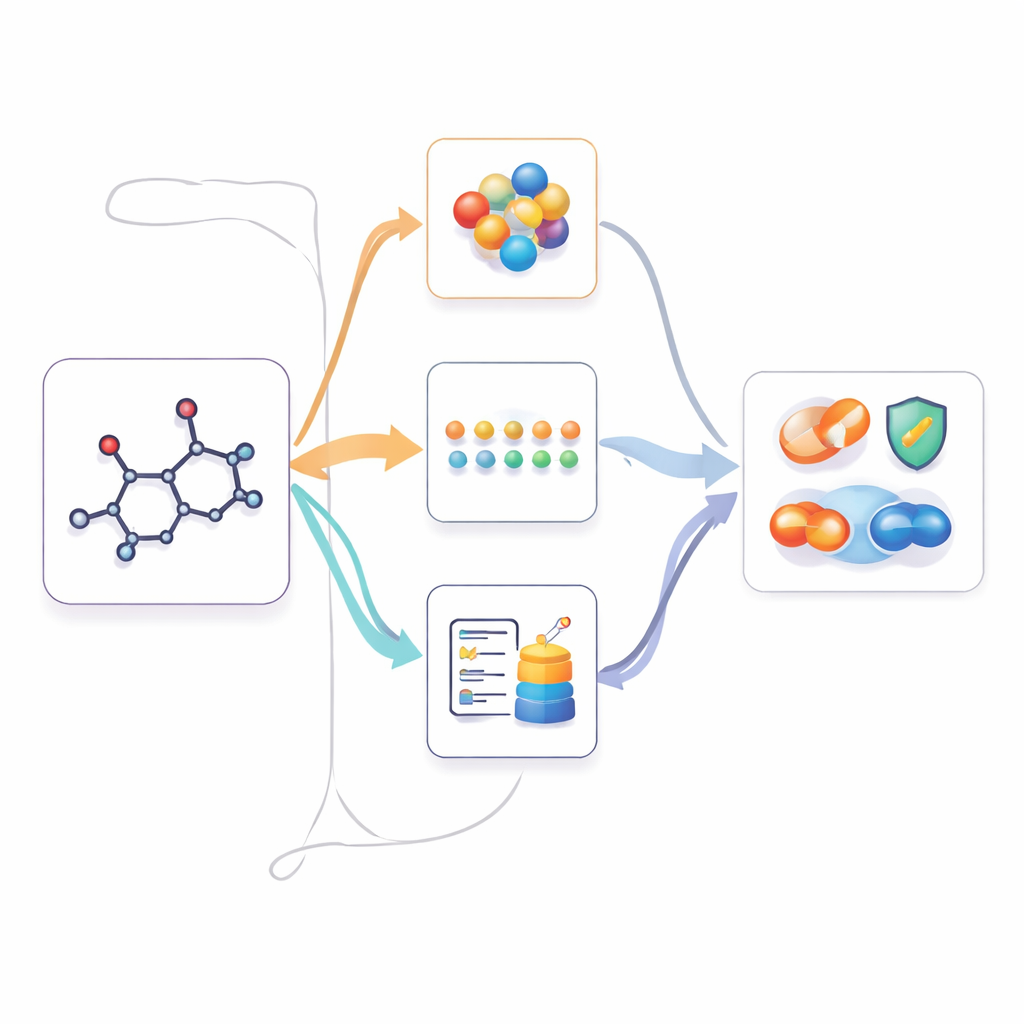
Usando conhecimento multimodal quando apenas o 2D está disponível
Uma vez que o M2UMol aprendeu essas relações, ele pode ser aplicado a tarefas práticas onde apenas estruturas 2D são fornecidas, como prever toxicidade, propriedades relacionadas a doenças ou interações medicamentosas. Para cada nova molécula, o codificador 2D pré-treinado produz uma representação central, e os adaptadores geram três versões “imaginadas”: uma que se assemelha à geometria 3D, outra que imita conhecimento baseado em texto e uma terceira que captura o contexto biológico. Um módulo de atenção simples então combina essas quatro visões em uma impressão digital final usada por preditores específicos de tarefa. Isso permite efetivamente que o modelo aja como se dispusesse de informação multimodal rica, enquanto os usuários precisam fornecer apenas uma estrutura 2D padrão.
Melhores previsões com menos dados e raciocínio mais claro
Em um amplo conjunto de benchmarks, o M2UMol supera tanto modelos de visão única quanto modelos multimodais anteriores na predição de propriedades moleculares e em tarefas mais complexas, como interações droga–droga e droga–alvo. Faz isso mesmo sendo pré-treinado em pouco mais de onze mil moléculas, usando recursos computacionais modestos, enquanto muitos métodos concorrentes usam milhões. Análises visuais mostram que as representações aprendidas estão bem separadas entre diferentes classes e distribuídas de forma equilibrada, sinal de alto conteúdo informacional. O modelo também pode destacar átomos e ligações específicos que orientam suas decisões, e esses frequentemente coincidem com grupos funcionais conhecidos responsáveis por toxicidade, atividade em um receptor ou interações problemáticas entre fármacos.
O que isso significa para futuros medicamentos
Para não especialistas, a ideia central é que o M2UMol aprende a pensar sobre um desenho simples de linha de uma molécula como se ele carregasse três camadas extras de contexto científico rico. Esse artifício permite fazer previsões mais robustas e explicáveis sobre como um fármaco se comportará, mesmo quando dados experimentais detalhados não estão disponíveis. Por ser eficiente, de código aberto e empacotado para uso fácil, essa abordagem pode ajudar pesquisadores a filtrar compostos com mais inteligência, entender por que alguns fármacos falham e, eventualmente, orientar o desenho de novos medicamentos com menos surpresas.
Citação: Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun 17, 3797 (2026). https://doi.org/10.1038/s41467-026-69302-6
Palavras-chave: descoberta de fármacos, aprendizado de representação molecular, IA multimodal, interações medicamentosas, química computacional