Clear Sky Science · zh
关于生物学与化学中大型语言模型的综述
教计算机分子语言
现代生物学与化学产生的数据量已超过任何人类所能阅读的范围。本文解释了如何将大型语言模型——与聊天机器人相同类型的人工智能——改造用于阅读和书写 DNA、蛋白质与小分子的“语言”。对于非专业读者而言,其吸引力显而易见:这些工具有望加速药物发现、增进对疾病的理解,甚至帮助计划并执行实验室内的实验。
从单词与句子到基因与分子
语言模型最初是为预测句子中的下一个词而构建的。科学家们意识到,许多生物与化学记录,例如蛋白质序列或分子的线性编码,也呈现为字符串形式。如果人工智能能够学习自然语言中的模式,它也可能学会将基因序列与其在细胞中作用相连,或将化学式与其性质联系起来。综述展示了研究者如何将复杂的三维分子与细胞谨慎地转换为 AI 能处理的一维字符串、图或点云。这个设计步骤至关重要,因为信息的表示方式限制了模型能够学习的内容以及其可能的发现类型。 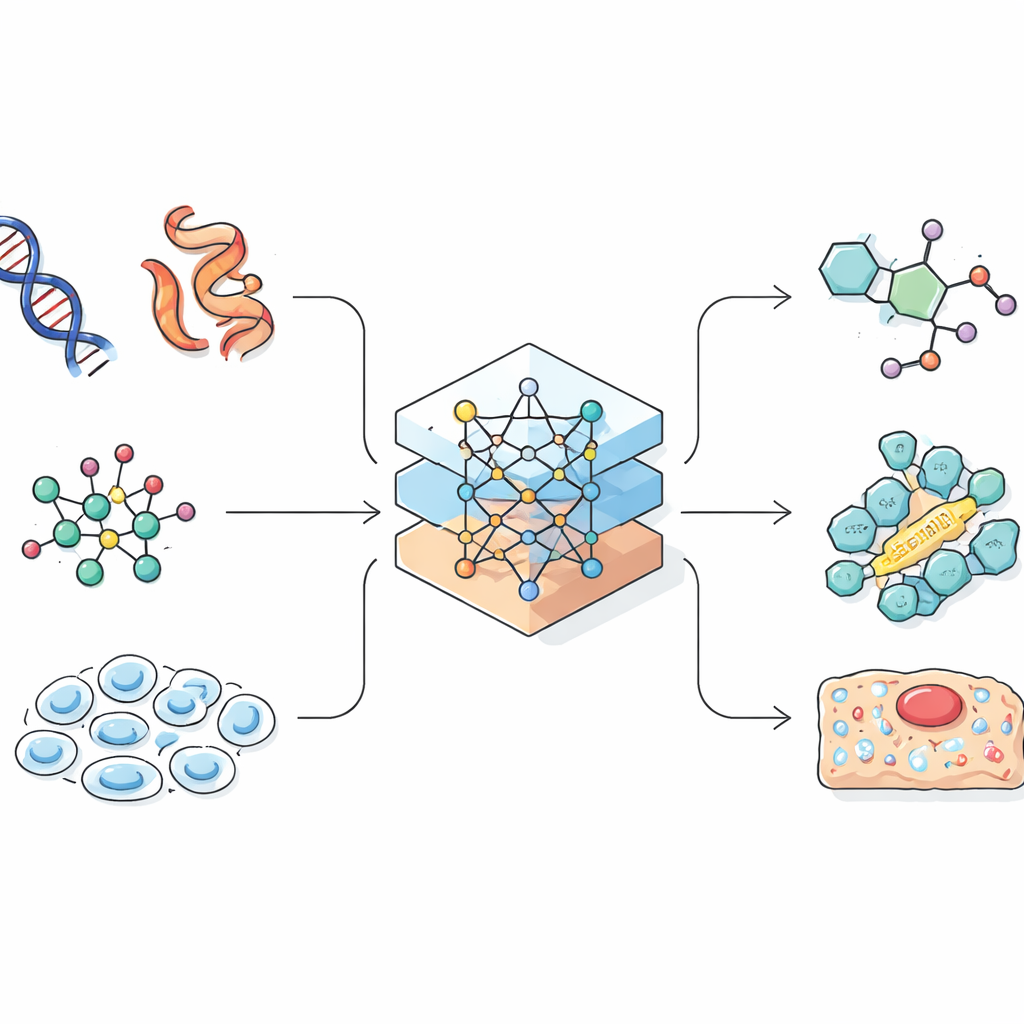
解读蛋白质、DNA 与单细胞生命
一个重要方向是处理活体系统的“生物语言模型”。对于蛋白质,基于数百万序列训练的模型现在能预测氨基酸线性链如何折叠成三维结构,其表现可与费时费力的实验技术媲美。有些模型更进一步,提出自然界从未存在但可能作为药物或工业酶的新蛋白设计。对 DNA 与 RNA,研究者将语言建模方法改造以处理由四个字母组成的长字符串,使人工智能能够识别基因组中的调控区或预测突变效应。在细胞层面,新方法将每个细胞的基因活性谱视作一篇“文档”,其中“词语”是基因,使模型能够对细胞类型进行聚类,预测细胞对处理的反应,并将实验数据与已有生物学知识相连接。
为化学赋予自己的数字语法
化学语言模型处理小分子世界,例如候选药物。在这里,化学家使用紧凑的类文本编码来描述结构,这些编码可以像句子一样输入语言模型。编码器型模型侧重于理解:它们为每种分子学习丰富的内部指纹,有助于预测溶解度或毒性等性质。解码器型模型侧重于创造:它们逐步生成全新分子,同时被引导朝向期望的特征。用于将一种序列翻译为另一种序列的成对模型被用于预测反应结果或建议合成目标化合物的方法。更先进的系统则混合文本、二维结构图、三维形状和图结构,使人工智能能够跨多种描述方式进行推理。
这些模型如何学习与改进
在底层,生物化学语言模型依赖巧妙的训练技巧。它们常以自监督学习为起点——在该方式下,人工智能学习猜测输入中缺失的部分,从而在没有人工标签的情况下把握潜在结构。多任务训练让单一模型同时练习多种相关问题,增强其通用能力。其他设计允许模型在回答问题时查阅外部数据库,将其输出基于真实的化学与生物学,从而减少虚构的断言。随后,少量有监督训练针对特定任务进行微调,例如预测药物安全性或规划反应。综述还调研了那些使判断新模型是否真正优于以往(而不仅是更大)成为可能的大型公开数据集与基准测试。 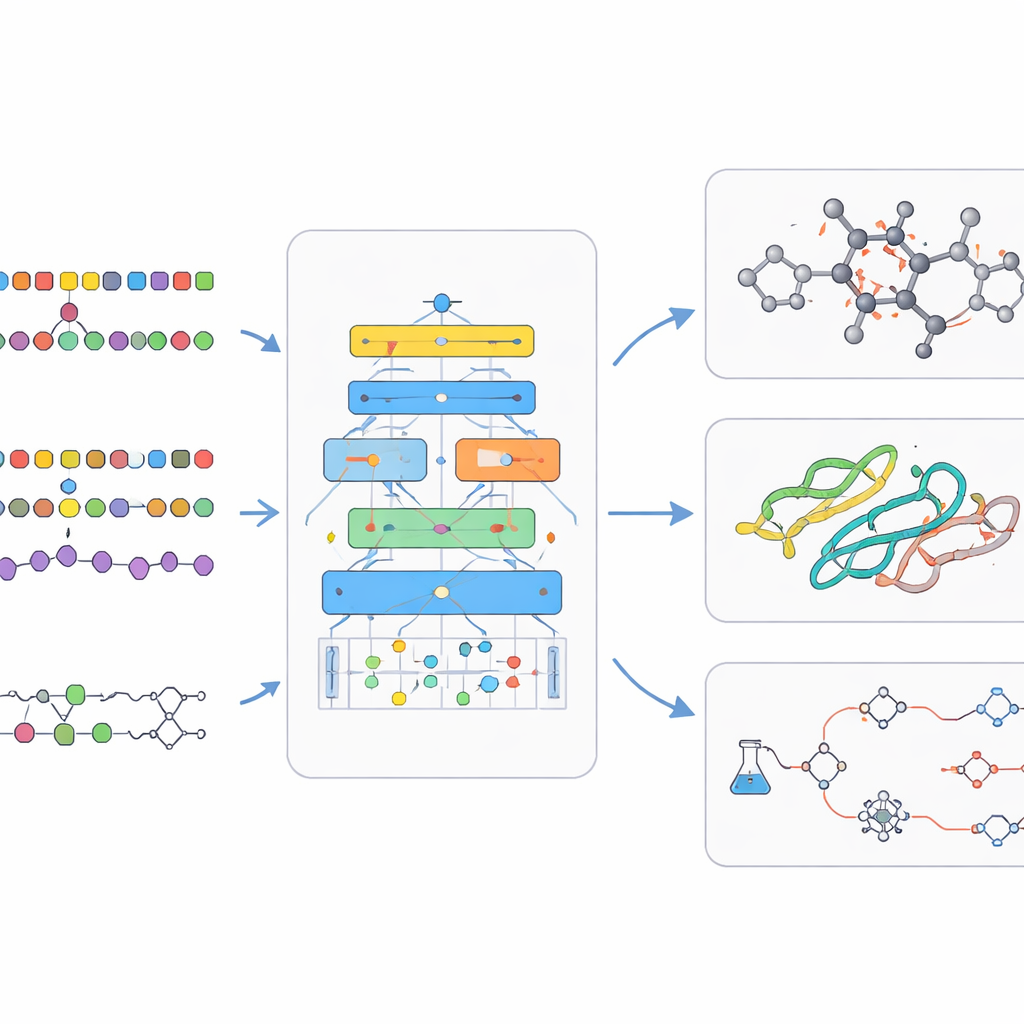
走向人工智能实验室助理与负责任的使用
超越独立模型,作者强调了一种向互动“能动”系统的转变。在这些设置中,语言模型可以调用专门工具——例如检查反应的程序、检索文献或控制实验室机器人——并将它们的输出串联起来。早期演示表明此类代理可以提出合成路线、设计实验,甚至指导自动化实验室。综述的结论是:若配以坚实的保障措施、透明的评估以及对伦理与监管的审慎关注,这些生物化学语言模型有望成为科学研究的核心基础设施。对非专业人士来说,关键信息是:人工智能正在学会阅读与书写生命与物质的代码,有潜力缩短从想法到药物、材料或生物学洞见的路径。
引用: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
关键词: 大型语言模型, 药物发现, 蛋白质结构, 化学语言模型, 基因组学