Clear Sky Science · fr
Un panorama des grands modèles de langage en biologie et chimie
Apprendre aux ordinateurs le langage des molécules
La biologie et la chimie modernes génèrent aujourd’hui plus de données qu’un humain ne pourrait lire. Cet article explique comment les grands modèles de langage — le même type d’IA derrière les chatbots — sont réutilisés pour lire et écrire les « langages » de l’ADN, des protéines et des petites molécules. Pour un lecteur non spécialiste, l’intérêt est évident : ces outils promettent d’accélérer la découverte de médicaments, d’améliorer la compréhension des maladies et même d’offrir des ordinateurs capables d’aider à planifier et exécuter des expériences en laboratoire.
Des mots et phrases aux gènes et molécules
Les modèles de langage ont été conçus à l’origine pour prédire le mot suivant dans une phrase. Les chercheurs ont réalisé que de nombreux enregistrements biologiques et chimiques, comme les séquences de protéines ou les encodages linéaires de molécules, ressemblent aussi à des chaînes de caractères. Si une IA peut apprendre des motifs dans le langage naturel, elle peut aussi apprendre des motifs qui relient une séquence génique à son rôle dans une cellule, ou une formule chimique à ses propriétés. La revue montre comment les chercheurs convertissent avec soin des molécules tridimensionnelles complexes et des cellules en chaînes unidimensionnelles, en graphes ou en nuages de points que l’IA peut traiter. Cette étape de conception est cruciale, car la façon dont l’information est représentée limite ce que le modèle peut apprendre et quels types de découvertes il peut réaliser. 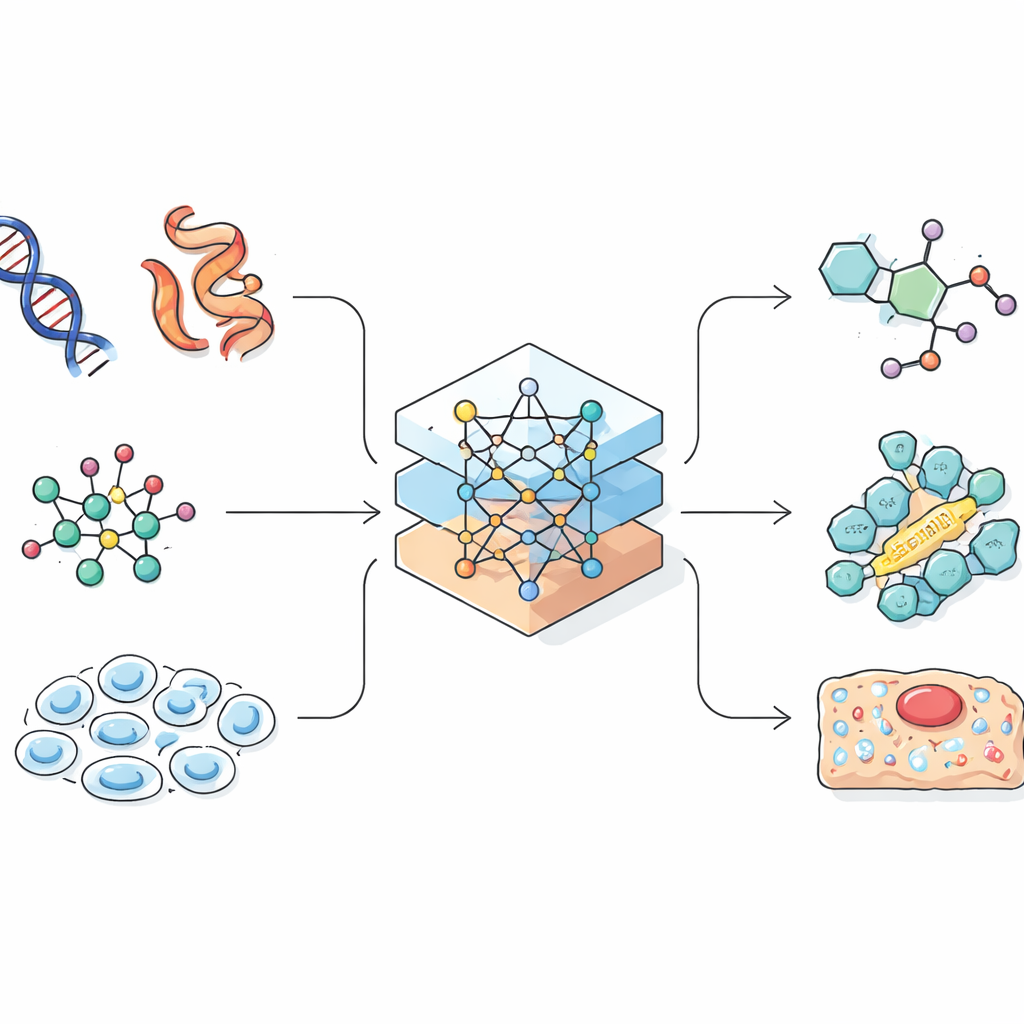
Lire les protéines, l’ADN et la vie des cellules individuelles
Un axe majeur porte sur les « modèles de langage biologiques » qui travaillent avec des systèmes vivants. Pour les protéines, des modèles entraînés sur des millions de séquences peuvent aujourd’hui prédire comment une chaîne linéaire d’acides aminés se repliera en une structure tridimensionnelle, rivalisant avec des techniques de laboratoire laborieuses. Certains modèles vont plus loin, proposant de nouvelles conceptions de protéines qui n’ont jamais existé dans la nature mais pourraient agir comme médicaments ou enzymes industrielles. Pour l’ADN et l’ARN, les chercheurs adaptent la modélisation linguistique pour gérer de longues chaînes composées de seulement quatre lettres, permettant à l’IA de repérer des régions de contrôle dans le génome ou de prédire les effets des mutations. Au niveau cellulaire, de nouvelles approches traitent le profil d’activité génique de chaque cellule comme un document dont les « mots » sont des gènes, permettant aux modèles de regrouper les types cellulaires, de prévoir les réponses des cellules aux traitements et de relier les données expérimentales aux connaissances biologiques antérieures.
Donner à la chimie sa propre grammaire numérique
Les modèles linguistiques chimiques s’attaquent au monde des petites molécules, comme les candidats-médicaments. Ici, les chimistes utilisent des codes compacts ressemblant à du texte pour décrire les structures, qui peuvent être fournis aux modèles de langage comme des phrases. Les modèles de type encodeur se concentrent sur la compréhension : ils apprennent une empreinte interne riche pour chaque molécule qui aide à prédire des propriétés comme la solubilité ou la toxicité. Les modèles de type décodeur se concentrent sur la création : ils génèrent de nouvelles molécules, étape par étape, tout en étant orientés vers des caractéristiques souhaitées. Des modèles appariés qui traduisent une séquence en une autre sont utilisés pour prédire le résultat de réactions ou suggérer des voies de synthèse pour une cible. Des systèmes plus avancés mêlent texte, dessins bidimensionnels, formes tridimensionnelles et graphes afin que l’IA puisse raisonner à travers plusieurs manières de décrire une même chimie.
Comment ces modèles apprennent et s’améliorent
Sous le capot, les modèles bio‑chimiques de langage reposent sur des astuces d’entraînement intelligentes. Ils commencent souvent par un apprentissage auto-supervisé, dans lequel l’IA apprend à deviner des parties manquantes de l’entrée, l’obligeant à saisir la structure sous-jacente sans étiquettes humaines. L’entraînement multitâche permet à un seul modèle de s’exercer sur de nombreux problèmes connexes à la fois, renforçant ses compétences générales. D’autres architectures autorisent le modèle à consulter des bases de données externes pendant qu’il répond, ancrant ses résultats dans la chimie et la biologie réelles et réduisant les assertions inventées. Ensuite, de courtes phases d’apprentissage supervisé affinent le modèle sur des tâches spécifiques, comme prédire la sécurité d’un médicament ou planifier une réaction. La revue passe aussi en revue les grands jeux de données publics et les bancs d’essai qui rendent possible l’évaluation rigoureuse d’un nouveau modèle, pour déterminer s’il est réellement meilleur et pas seulement plus volumineux. 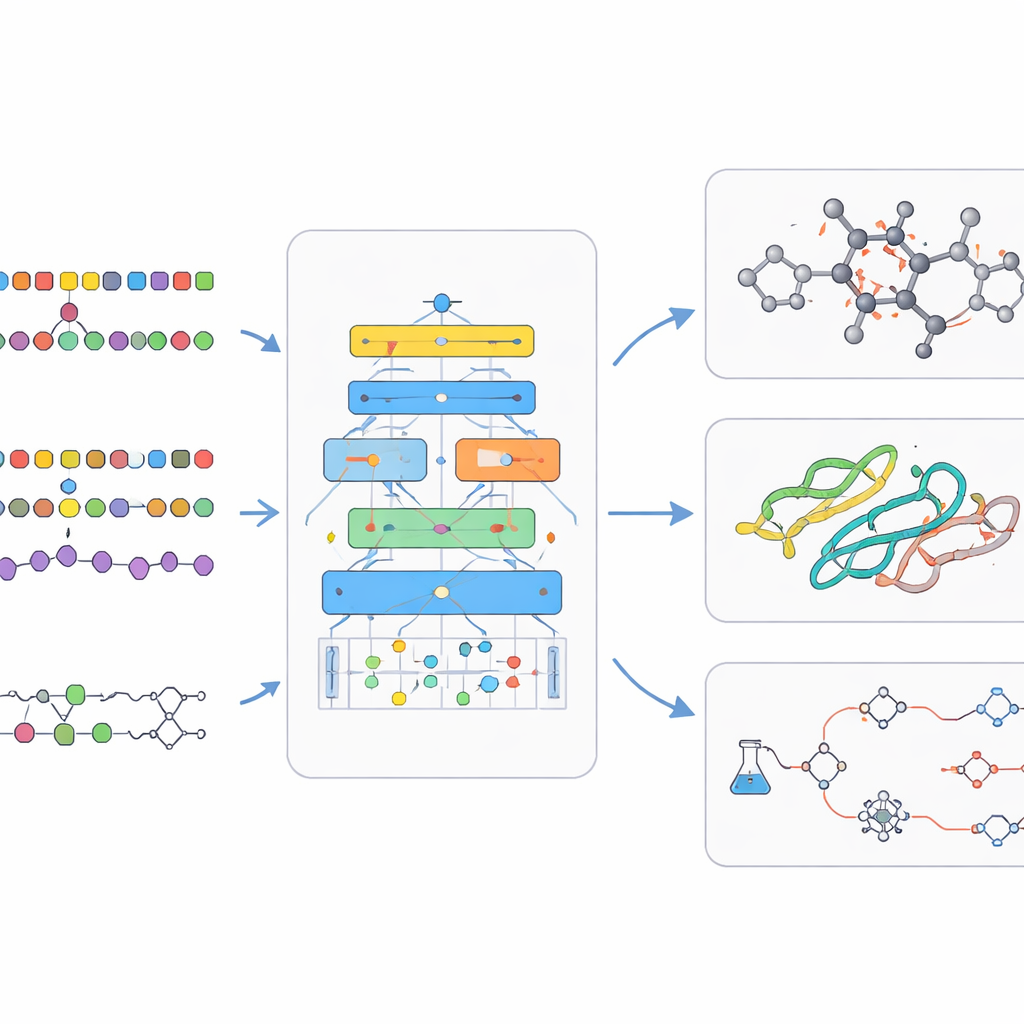
Vers des assistants de laboratoire IA et un usage responsable
Au-delà des modèles autonomes, les auteurs soulignent une évolution vers des systèmes interactifs « agentiques ». Dans ces configurations, un modèle de langage peut appeler des outils spécialisés — par exemple, un programme qui vérifie des réactions, recherche la littérature ou contrôle des robots de laboratoire — et chaÎner leurs sorties. Des démonstrations initiales montrent que de tels agents proposent des voies de synthèse, conçoivent des expériences et pilotent même des laboratoires automatisés. La revue conclut que, s’ils sont associés à des garde-fous solides, une évaluation transparente et une attention rigoureuse à l’éthique et à la réglementation, ces modèles bio‑chimiques pourraient devenir une infrastructure centrale pour la science. Pour les non-experts, le message clé est que l’IA apprend à lire et à écrire le code de la vie et de la matière, avec le potentiel de raccourcir le chemin de l’idée vers le médicament, le matériau ou l’intuition biologique.
Citation: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Mots-clés: grands modèles de langage, découverte de médicaments, structure des protéines, modèles linguistiques chimiques, génomique