Clear Sky Science · de
Eine Übersicht zu großen Sprachmodellen in Biologie und Chemie
Computern die Sprache der Moleküle beibringen
Moderne Biologie und Chemie produzieren heute mehr Daten, als ein Mensch lesen könnte. Dieser Artikel erklärt, wie große Sprachmodelle — dieselbe Art von KI, die Chatbots antreibt — umfunktioniert werden, um die „Sprachen“ von DNA, Proteinen und kleinen Molekülen zu lesen und zu schreiben. Für eine nicht fachkundige Leserschaft ist die Anziehungskraft eindeutig: Diese Werkzeuge versprechen schnellere Wirkstoffforschung, besseres Verständnis von Krankheiten und sogar Computer, die bei Planung und Durchführung von Experimenten im Labor helfen.
Von Wörtern und Sätzen zu Genen und Molekülen
Sprachmodelle wurden ursprünglich entwickelt, um das nächste Wort in einem Satz vorherzusagen. Wissenschaftler erkannten, dass viele biologische und chemische Aufzeichnungen, etwa Proteinsequenzen oder lineare Kodierungen von Molekülen, ebenfalls wie Zeichenketten aussehen. Wenn eine KI Muster in natürlicher Sprache lernen kann, könnte sie auch Muster lernen, die eine Gensequenz mit ihrer Funktion in der Zelle verbinden oder eine chemische Formel mit ihren Eigenschaften verknüpfen. Die Übersichtsarbeit zeigt, wie Forschende komplexe dreidimensionale Moleküle und Zellen sorgfältig in eindimensionale Zeichenketten, Graphen oder Punktwolken umwandeln, die eine KI verarbeiten kann. Dieser Designschritt ist entscheidend, denn die Art, wie Informationen dargestellt werden, begrenzt, was das Modell lernen und welche Entdeckungen es machen kann. 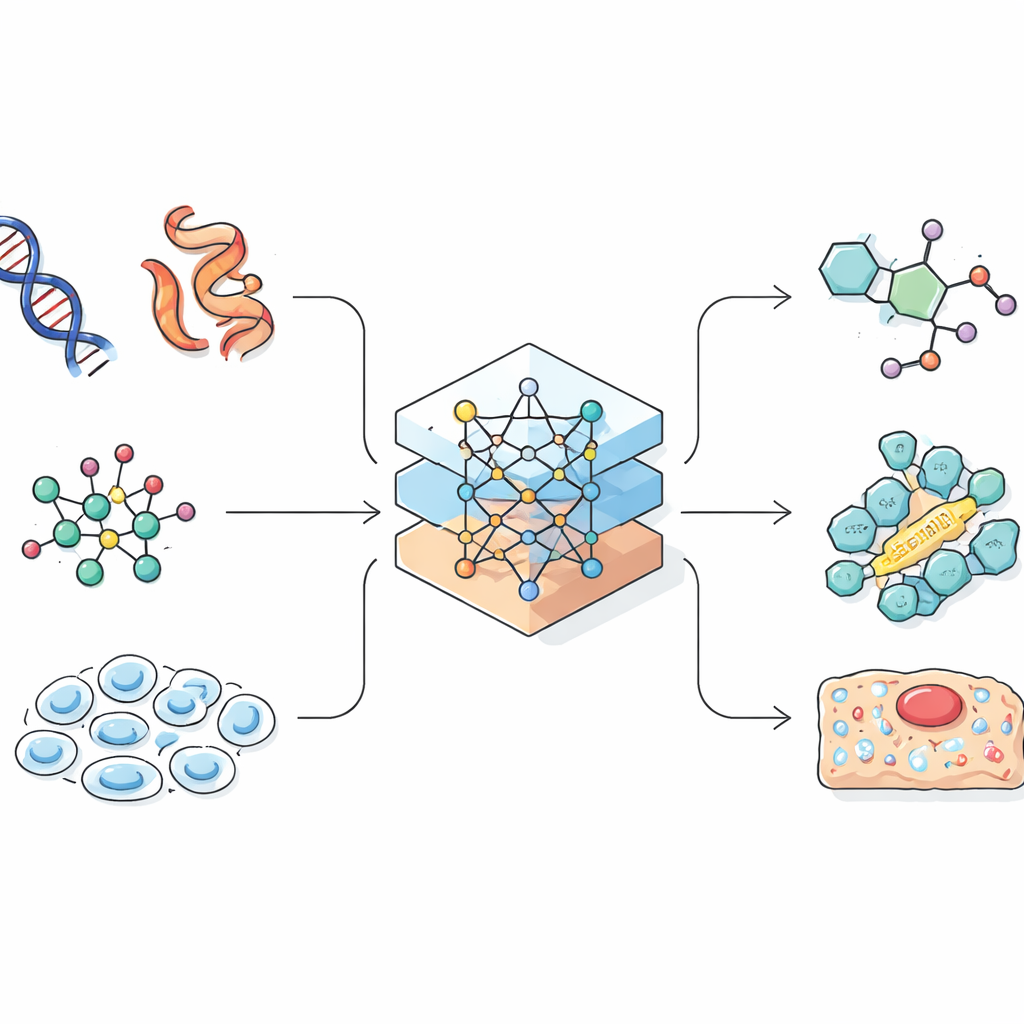
Proteine, DNA und das Leben einzelner Zellen lesen
Ein Schwerpunkt liegt auf „biologischen Sprachmodellen“, die mit lebenden Systemen arbeiten. Bei Proteinen können Modelle, die auf Millionen von Sequenzen trainiert wurden, inzwischen vorhersagen, wie eine lineare Kette von Aminosäuren in eine dreidimensionale Struktur faltet — und erreichen damit Leistungen, die aufwändige Laborverfahren konkurrenzieren. Einige Modelle gehen noch weiter und schlagen neue Proteindesigns vor, die in der Natur nie existierten, aber als Wirkstoffe oder industrielle Enzyme dienen könnten. Bei DNA und RNA passen Forschende das Sprachmodellieren an, um mit langen Sequenzen aus nur vier Buchstaben umzugehen; so kann die KI Kontrollregionen im Genom entdecken oder die Auswirkungen von Mutationen vorhersagen. Auf Zellebene behandeln neue Ansätze das Genaktivitätsprofil jeder Zelle wie ein Dokument, dessen „Wörter“ Gene sind, sodass Modelle Zelltypen gruppieren, vorhersagen können, wie Zellen auf Behandlungen reagieren, und Laborergebnisse mit vorhandenem biologischem Wissen verbinden.
Der Chemie eine eigene digitale Grammatik geben
Chemische Sprachmodelle befassen sich mit der Welt kleiner Moleküle, etwa Wirkstoffkandidaten. Chemiker verwenden hier kompakte, textähnliche Codes zur Beschreibung von Strukturen, die man Sprachmodellen ähnlich wie Sätzen zuführen kann. Encoder-Modelle konzentrieren sich auf das Verstehen: Sie lernen zu jedem Molekül einen reichen internen Fingerabdruck, der bei der Vorhersage von Eigenschaften wie Löslichkeit oder Toxizität hilft. Decoder-Modelle fokussieren auf die Erzeugung: Sie generieren Schritt für Schritt völlig neue Moleküle und werden dabei in Richtung gewünschter Eigenschaften gesteuert. Gepaarte Modelle, die eine Sequenz in eine andere übersetzen, werden eingesetzt, um Reaktionsprodukte vorherzusagen oder Wege zur Synthese eines Zielmoleküls vorzuschlagen. Fortgeschrittene Systeme kombinieren Text, zweidimensionale Zeichnungen, dreidimensionale Formen und Graphen, damit die KI über viele Arten hinaus denken kann, dieselbe Chemie zu beschreiben.
Wie diese Modelle lernen und sich verbessern
Im Inneren beruhen bio‑chemische Sprachmodelle auf ausgeklügelten Trainingsmethoden. Häufig beginnen sie mit selbstüberwachtem Lernen, bei dem die KI fehlende Teile der Eingabe erraten muss, wodurch sie ohne menschliche Labels zugrundeliegende Strukturen erfasst. Multitask-Training erlaubt es einem Modell, viele verwandte Probleme gleichzeitig zu üben und so seine allgemeinen Fähigkeiten zu stärken. Andere Entwürfe erlauben dem Modell, beim Beantworten von Fragen externe Datenbanken nachzuschlagen, wodurch Ausgaben in echter Chemie und Biologie verankert und erfundene Behauptungen reduziert werden. Danach verfeinern kleinere Runden überwachten Lernens das Modell für spezifische Aufgaben wie Vorhersage von Arzneimittelsicherheit oder Reaktionsplanung. Die Übersichtsarbeit behandelt außerdem die großen öffentlichen Datensätze und Benchmarks, die es ermöglichen zu beurteilen, ob ein neues Modell wirklich besser ist und nicht nur größer. 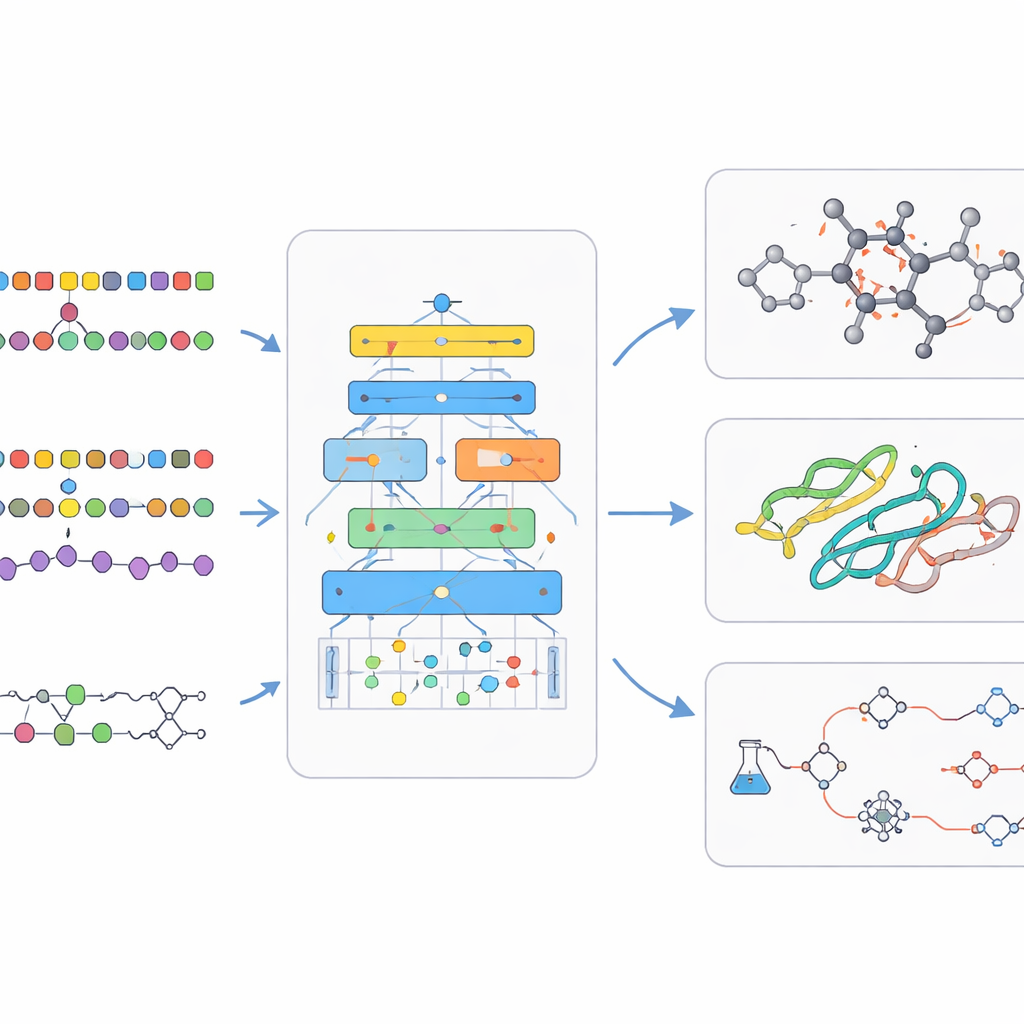
Auf dem Weg zu KI-Laborassistenten und verantwortungsvollem Einsatz
Über einzelne Modelle hinaus heben die Autorinnen und Autoren eine Verschiebung hin zu interaktiven „agentischen“ Systemen hervor. In solchen Setups kann ein Sprachmodell spezialisierte Werkzeuge aufrufen — etwa ein Programm, das Reaktionen prüft, die Literatur durchsucht oder Laborroboter steuert — und deren Ergebnisse zu einem Ablauf verketten. Erste Demonstrationen zeigen, dass solche Agenten Syntheserouten vorschlagen, Experimente entwerfen und sogar automatisierte Labors steuern. Die Übersicht schließt mit der Einschätzung, dass diese bio‑chemischen Sprachmodelle, gepaart mit starken Schutzmaßnahmen, transparenter Evaluation und sorgfältiger Beachtung von Ethik und Regulierung, zur zentralen Infrastruktur der Wissenschaft werden könnten. Für Nicht-Expertinnen und Nicht-Experten lautet die Kernbotschaft: KI lernt, den Code von Leben und Materie zu lesen und zu schreiben — mit dem Potenzial, den Weg von Idee zu Medikament, Material oder biologischer Einsicht zu verkürzen.
Zitation: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Schlüsselwörter: große Sprachmodelle, Arzneimittelentdeckung, Proteinstruktur, chemische Sprachmodelle, Genomik