Clear Sky Science · it
Una rassegna sui grandi modelli linguistici in biologia e chimica
Insegnare ai computer il linguaggio delle molecole
La biologia e la chimica moderne generano oggi più dati di quanti un essere umano possa leggere. Questo articolo spiega come i grandi modelli linguistici—lo stesso tipo di intelligenza artificiale dietro i chatbot—vengano adattati per leggere e scrivere i “linguaggi” del DNA, delle proteine e delle piccole molecole. Per un lettore non specialista, l’attrattiva è chiara: questi strumenti promettono una scoperta di farmaci più rapida, una migliore comprensione delle malattie e persino computer che aiutano a progettare e condurre esperimenti in laboratorio.
Dalle parole e frasi ai geni e alle molecole
I modelli linguistici sono stati originariamente costruiti per prevedere la parola successiva in una frase. Gli scienziati si sono accorti che molti dati biologici e chimici, come le sequenze proteiche o le codifiche lineari delle molecole, somigliano anch’essi a stringhe. Se un’IA può apprendere schemi nel linguaggio naturale, potrebbe imparare anche i nessi che collegano una sequenza genica al suo ruolo in una cellula, o una formula chimica alle sue proprietà. La rassegna mostra come i ricercatori convertano con cura molecole tridimensionali complesse e cellule in stringhe monodimensionali, grafi o nuvole di punti che un’IA può gestire. Questo passaggio di progettazione è cruciale, perché il modo in cui l’informazione è rappresentata limita ciò che il modello può apprendere e che tipo di scoperte può fare. 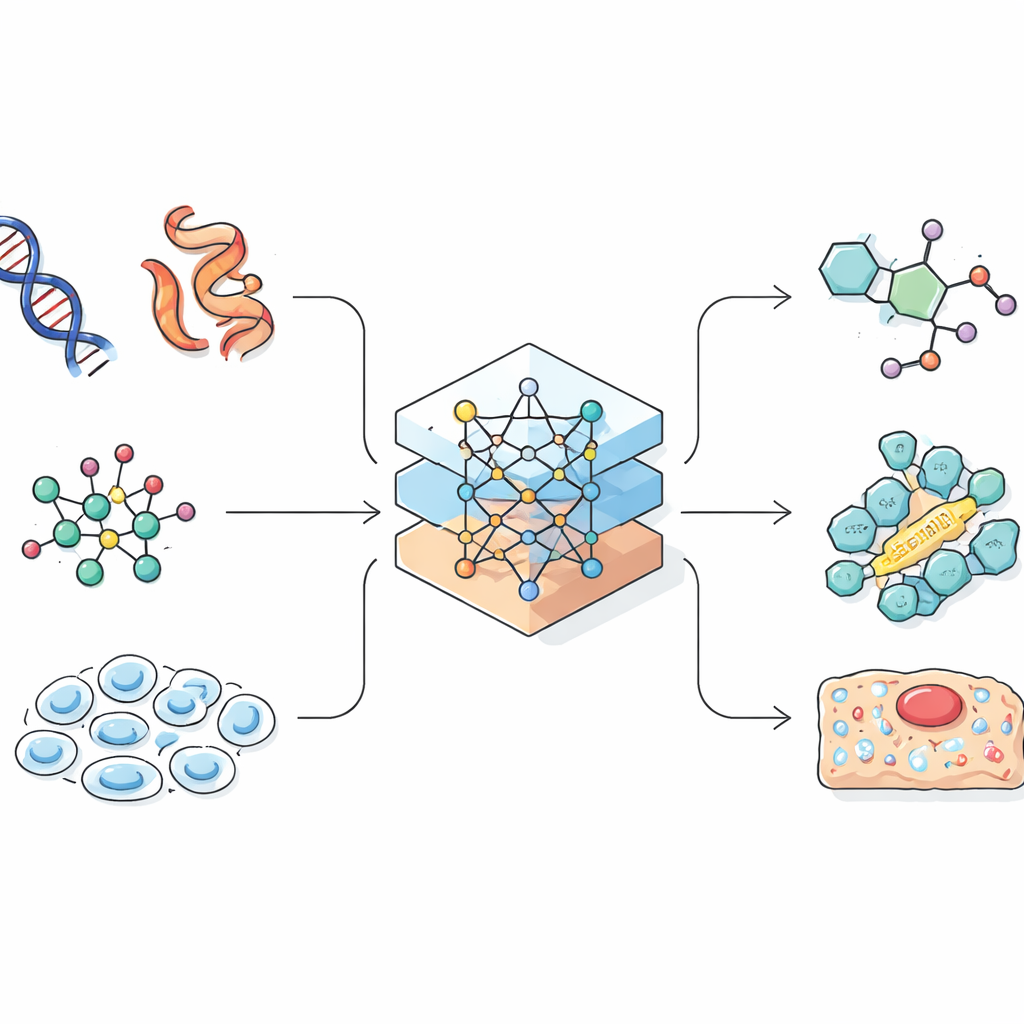
Leggere proteine, DNA e la vita delle singole cellule
Un importante filone riguarda i “modelli linguistici biologici” che lavorano con i sistemi viventi. Per le proteine, modelli addestrati su milioni di sequenze possono ora prevedere come una catena lineare di amminoacidi si ripieghi in una struttura tridimensionale, rivaleggiando con tecniche di laboratorio laboriose. Alcuni modelli vanno oltre, suggerendo nuovi design proteici che non sono mai esistiti in natura ma potrebbero agire come farmaci o enzimi industriali. Per DNA e RNA, i ricercatori adattano il model‑ling linguistico per trattare lunghe stringhe composte da sole quattro lettere, permettendo all’IA di individuare regioni di controllo nel genoma o di prevedere gli effetti delle mutazioni. A livello cellulare, nuovi approcci trattano il profilo di attività genica di ciascuna cellula come un documento le cui “parole” sono i geni, consentendo ai modelli di raggruppare tipi cellulari, prevedere come le cellule rispondono ai trattamenti e collegare i dati di laboratorio alla conoscenza biologica preesistente.
Attribuire alla chimica una propria grammatica digitale
I modelli linguistici chimici affrontano il mondo delle piccole molecole, come i candidati farmaci. Qui i chimici utilizzano codici compatti simili a testo per descrivere le strutture, che possono essere forniti ai modelli linguistici analogamente a frasi. I modelli di tipo encoder si concentrano sulla comprensione: apprendono un’impronta interna ricca per ciascuna molecola che aiuta a predire proprietà come solubilità o tossicità. I modelli di tipo decoder puntano alla creazione: generano nuove molecole, passo dopo passo, venendo orientati verso caratteristiche desiderate. Modelli accoppiati che traducono una sequenza in un’altra vengono usati per prevedere l’esito di reazioni o suggerire percorsi di sintesi per un composto target. Sistemi più avanzati mescolano testo, disegni bidimensionali, forme tridimensionali e grafi in modo che l’IA possa ragionare attraverso molteplici modalità di descrivere la stessa chimica.
Come questi modelli apprendono e migliorano
Sotto il cofano, i modelli linguistici bio‑chimici si basano su astuti stratagemmi di addestramento. Di solito iniziano con l’apprendimento auto‑supervisionato, in cui l’IA impara a indovinare pezzi mancanti dell’input, costringendola a cogliere la struttura sottostante senza etichette umane. L’addestramento multitask permette a un singolo modello di esercitarsi su molti problemi correlati contemporaneamente, rafforzando le sue abilità generali. Altri progetti consentono al modello di consultare banche dati esterne mentre risponde, fondando le sue uscite su chimica e biologia reali e riducendo affermazioni inventate. Successivamente, brevi cicli di addestramento supervisionato sintonizzano il modello su compiti specifici come prevedere la sicurezza di un farmaco o pianificare una reazione. La rassegna esamina anche i grandi dataset pubblici e i benchmark che rendono possibile giudicare se un nuovo modello sia davvero migliore, e non solo più grande. 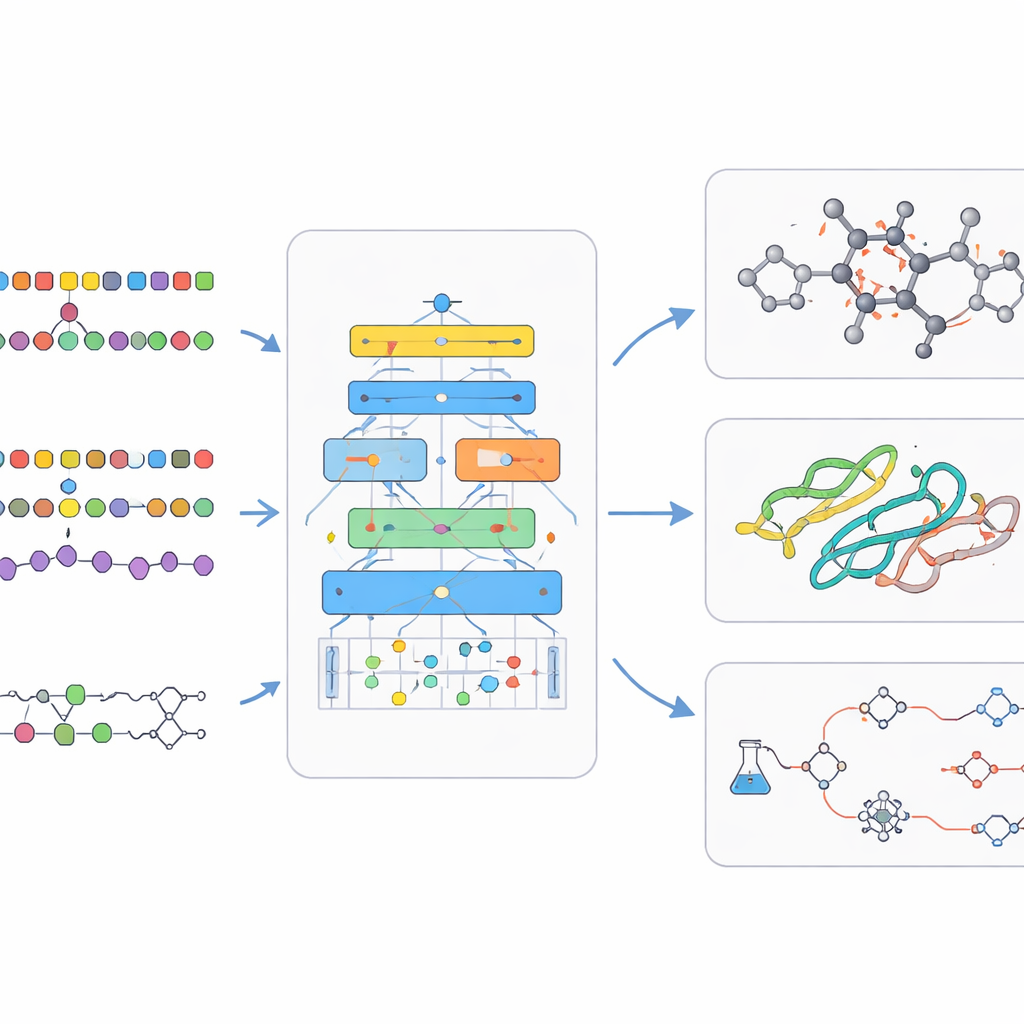
Verso assistenti di laboratorio AI e uso responsabile
Oltre ai modelli indipendenti, gli autori evidenziano uno spostamento verso sistemi interattivi “agentici”. In tali configurazioni, un modello linguistico può chiamare strumenti specializzati—per esempio, un programma che verifica reazioni, cerca nella letteratura o controlla robot da laboratorio—and concatenarne i risultati. Dimostrazioni iniziali mostrano agenti che propongono percorsi di sintesi, progettano esperimenti e persino guidano laboratori automatizzati. La rassegna conclude che, se affiancati da solide salvaguardie, valutazioni trasparenti e attenta considerazione di etica e regolamentazione, questi modelli linguistici bio‑chimici potrebbero diventare infrastrutture centrali per la scienza. Per i non esperti, il messaggio chiave è che l’IA sta imparando a leggere e scrivere il codice della vita e della materia, con il potenziale di accorciare il percorso dall’idea al medicinale, al materiale o all’intuizione biologica.
Citazione: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Parole chiave: grandi modelli linguistici, scoperta di farmaci, struttura delle proteine, modelli linguistici chimici, genomica