Clear Sky Science · pl
Przegląd dużych modeli językowych w biologii i chemii
Nauczanie komputerów języka cząsteczek
Współczesna biologia i chemia generują teraz więcej danych, niż człowiek mógłby przeczytać. Artykuł wyjaśnia, jak duże modele językowe — ten sam rodzaj sztucznej inteligencji stojący za chatbotami — są przekształcane tak, by czytać i pisać „języki” DNA, białek i małych cząsteczek. Dla czytelnika nieznającego tematu atrakcyjność jest oczywista: narzędzia te obiecują szybsze odkrywanie leków, lepsze zrozumienie chorób, a nawet komputery pomagające planować i prowadzić eksperymenty w laboratorium.
Od słów i zdań do genów i cząsteczek
Modele językowe pierwotnie budowano, by przewidywać następne słowo w zdaniu. Naukowcy zauważyli, że wiele zapisów biologicznych i chemicznych, takich jak sekwencje białkowe czy liniowe kodowania cząsteczek, również przypomina ciągi znaków. Jeśli SI potrafi wychwycić wzory w języku naturalnym, może też nauczyć się zależności łączących sekwencję genu z jego rolą w komórce albo formułę chemiczną z jej właściwościami. Przegląd pokazuje, jak badacze starannie przekształcają skomplikowane trójwymiarowe cząsteczki i komórki w jednowymiarowe ciągi, grafy lub chmury punktów, które SI jest w stanie przetwarzać. Ten etap projektowania jest kluczowy, ponieważ sposób reprezentacji informacji ogranicza to, czego model może się nauczyć i jakie odkrycia może umożliwić. 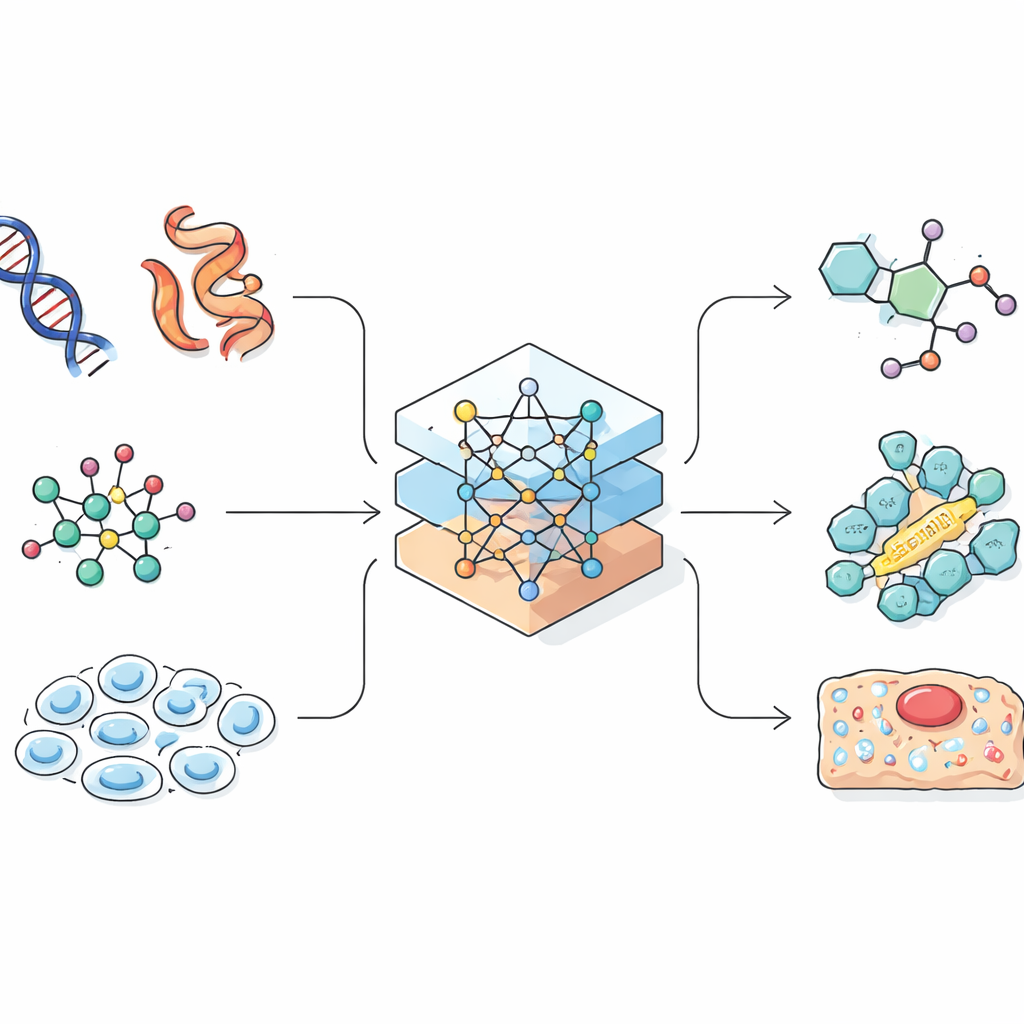
Czytanie białek, DNA i życia pojedynczych komórek
Jednym z głównych obszarów jest praca nad „biologicznymi modelami językowymi” operującymi na systemach żywych. W przypadku białek modele trenowane na milionach sekwencji potrafią już przewidywać, jak liniowy łańcuch aminokwasów złoży się w strukturę trójwymiarową, dorównując żmudnym technikom laboratoryjnym. Niektóre modele idą dalej, proponując nowe projekty białek, które nigdy nie istniały w przyrodzie, a mogłyby działać jako leki lub enzymy przemysłowe. Dla DNA i RNA badacze adaptują modelowanie językowe do pracy z długimi łańcuchami złożonymi z zaledwie czterech liter, co umożliwia SI wykrywanie regionów kontrolnych w genomie lub przewidywanie skutków mutacji. Na poziomie komórki nowe podejścia traktują profil aktywności genów każdej komórki jak dokument, którego „słowami” są geny, pozwalając modelom grupować typy komórek, prognozować ich reakcje na terapie i łączyć dane z laboratorium z istniejącą wiedzą biologiczną.
Nadanie chemii własnej cyfrowej gramatyki
Chemiczne modele językowe zajmują się światem małych cząsteczek, takich jak kandydaci na leki. Chemicy używają tu zwartych kodów przypominających tekst do opisu struktur, które można podawać modelom językowym podobnie jak zdania. Modele typu encoder koncentrują się na rozumieniu: uczą się bogatego wewnętrznego odcisku dla każdej cząsteczki, co pomaga przewidywać właściwości, takie jak rozpuszczalność czy toksyczność. Modele typu decoder skupiają się na tworzeniu: generują zupełnie nowe cząsteczki krok po kroku, przy czym są kierowane w stronę pożądanych cech. Modele sparowane, tłumaczące jedną sekwencję na inną, służą do przewidywania wyników reakcji lub sugerowania sposobów syntezy docelowego związku. Bardziej zaawansowane systemy łączą tekst, rysunki dwuwymiarowe, kształty trójwymiarowe i grafy, aby SI mogła rozumować w wielu reprezentacjach tej samej chemii.
Jak te modele uczą się i poprawiają
Pod maską bio‑chemiczne modele językowe opierają się na sprytnych metodach treningu. Często zaczynają od uczenia bez nadzoru, w którym SI uczy się zgadywać brakujące fragmenty wejścia, zmuszając ją do uchwycenia struktury bez etykiet od człowieka. Trening wielozadaniowy pozwala jednemu modelowi ćwiczyć wiele powiązanych problemów jednocześnie, wzmacniając jego ogólne umiejętności. Inne rozwiązania umożliwiają modelowi odwoływanie się do zewnętrznych baz danych podczas odpowiadania, zakotwiczając wyniki w rzeczywistej chemii i biologii oraz zmniejszając liczbę wymyślonych twierdzeń. Następnie mniejsze rundy nadzorowanego treningu dostrajają model do konkretnych zadań, takich jak przewidywanie bezpieczeństwa leku czy planowanie reakcji. Przegląd omawia również duże publiczne zbiory danych i benchmarki, które pozwalają ocenić, czy nowy model jest naprawdę lepszy, a nie tylko większy. 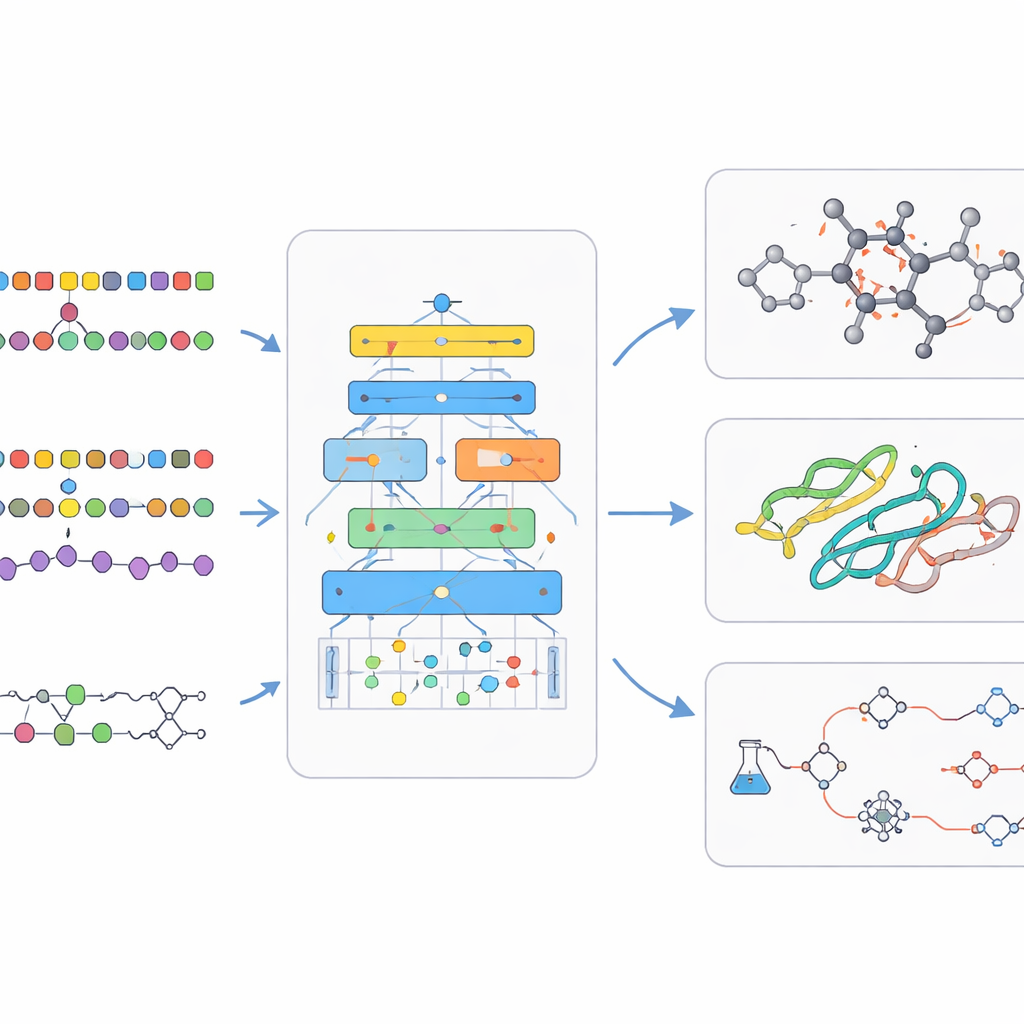
W kierunku asystentów laboratoryjnych i odpowiedzialnego użycia
Ponad samodzielnymi modelami autorzy zwracają uwagę na przesunięcie w stronę interaktywnych systemów „agentycznych”. W takich układach model językowy może wywoływać wyspecjalizowane narzędzia — na przykład program sprawdzający reakacje, przeszukujący literaturę lub sterujący robotami laboratoryjnymi — i łączyć ich wyniki. Wczesne demonstracje pokazują, że tacy agenci proponują ścieżki syntezy, projektują eksperymenty, a nawet kierują zautomatyzowanymi laboratoriami. Przegląd konkluduje, że przy silnych zabezpieczeniach, przejrzystej ocenie oraz ostrożnej uwadze na etykę i regulacje, te bio‑chemiczne modele językowe mogą stać się podstawową infrastrukturą nauki. Dla nie‑ekspertów kluczowy przekaz brzmi: SI uczy się czytać i pisać kod życia i materii, z potencjałem skrócenia drogi od pomysłu do leku, materiału czy odkrycia biologicznego.
Cytowanie: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Słowa kluczowe: duże modele językowe, odkrywanie leków, struktura białek, chemiczne modele językowe, genomika