Clear Sky Science · ru
Обзор больших языковых моделей в биологии и химии
Обучение компьютеров языку молекул
Современные биология и химия теперь генерируют больше данных, чем способен прочесть любой человек. В статье объясняется, как большие языковые модели — тот же класс ИИ, что стоит за чат-ботами — переосмыслены для чтения и «написания» «языков» ДНК, белков и малых молекул. Для неспециалиста привлекательность очевидна: эти инструменты обещают ускорить открытие лекарств, лучше понять болезни и даже помочь компьютерам планировать и проводить эксперименты в лаборатории.
От слов и предложений к генам и молекулам
Языковые модели изначально создавались, чтобы предсказывать следующее слово в предложении. Учёные заметили, что многие биологические и химические записи, например последовательности белков или линейные кодировки молекул, тоже выглядят как строки. Если ИИ может выучить закономерности в естественном языке, он может также улавливать связи между последовательностью гена и его ролью в клетке или между химической формулой и её свойствами. Обзор показывает, как исследователи тщательно преобразуют сложные трёхмерные молекулы и клетки в одномерные строки, графы или облака точек, с которыми может работать ИИ. Этот этап проектирования критичен, потому что способ представления информации ограничивает то, чему модель может научиться и какие открытия она способна сделать. 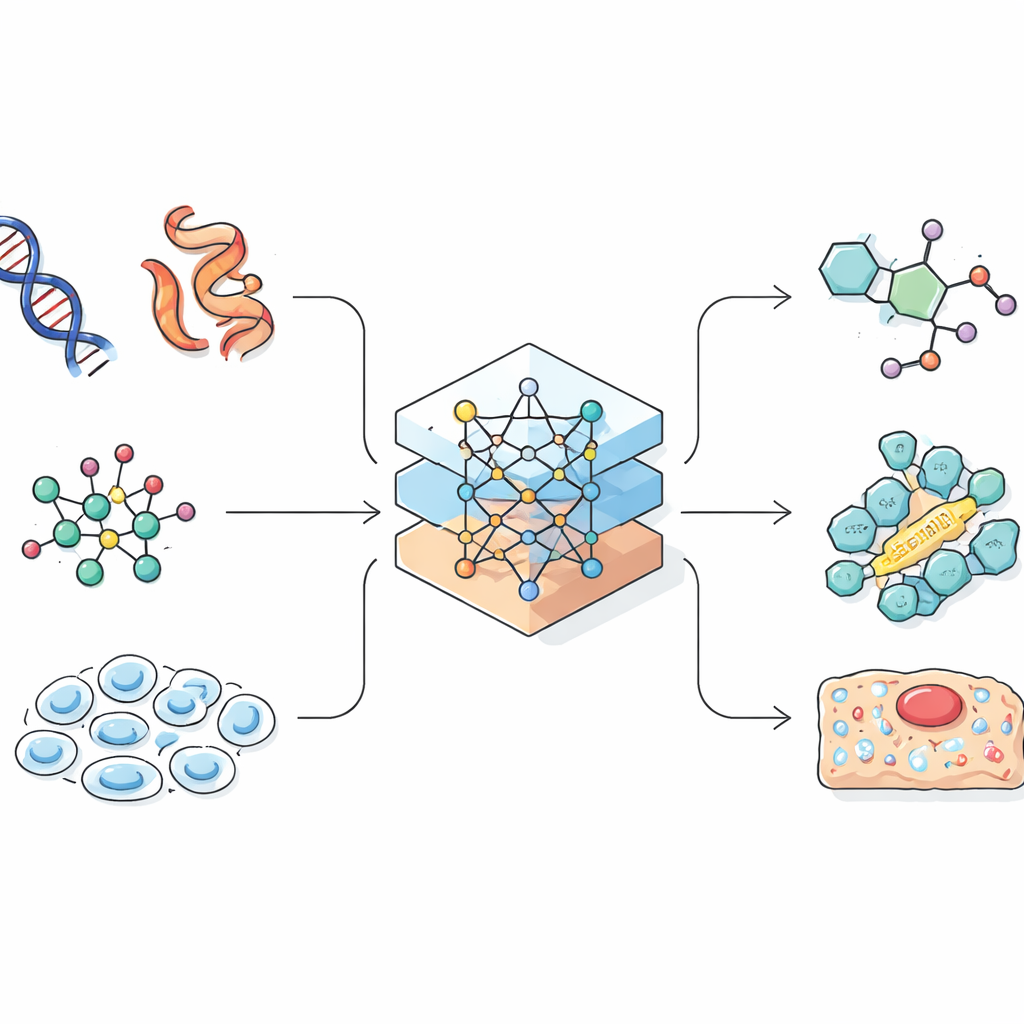
Чтение белков, ДНК и жизни отдельных клеток
Одно из ключевых направлений — «биологические языковые модели», работающие с живыми системами. Для белков модели, обученные на миллионах последовательностей, теперь могут предсказывать, как линейная цепочка аминокислот свернётся в трёхмерную структуру, соперничая с кропотливыми лабораторными методами. Некоторые модели идут дальше, предлагая новые белковые конструкции, которых не существует в природе, но которые могли бы выступать в роли лекарств или промышленных ферментов. Для ДНК и РНК исследователи адаптируют языковое моделирование к длинным строкам, составленным из всего четырёх букв, что позволяет ИИ обнаруживать регуляторные участки генома или предсказывать последствия мутаций. На уровне клеток новые подходы рассматривают профиль активности генов каждой клетки как документ, «словами» которого являются гены, позволяя моделям группировать типы клеток, прогнозировать их реакции на лечение и связывать лабораторные данные с накопленными биологическими знаниями.
Придание химии собственной цифровой грамматики
Химические языковые модели работают с миром малых молекул, например кандидатами в лекарства. Химики используют компактные текстоподобные коды для описания структур, которые можно подавать в языковые модели как предложения. Модели в стиле энкодера ориентированы на понимание: они выстраивают богатую внутреннюю «отпечатковую» матрицу для каждой молекулы, что помогает предсказывать такие свойства, как растворимость или токсичность. Модели в стиле декодера ориентированы на создание: они генерируют совершенно новые молекулы пошагово, направляясь к желаемым характеристикам. Парные модели, переводящие одну последовательность в другую, используют для предсказания результатов реакций или предложения способов синтеза целевого соединения. Более продвинутые системы комбинируют текст, двухмерные рисунки, трёхмерные формы и графы, чтобы ИИ мог рассуждать на основе разных способов описания одной и той же химии.
Как эти модели учатся и улучшаются
Под капотом биохимические языковые модели опираются на хитрые приёмы обучения. Они часто начинают с самообучения без учителя, когда ИИ учится угадывать пропущенные части входных данных, заставляя его улавливать скрытую структуру без человеческих меток. Многозадачное обучение позволяет одной модели одновременно тренироваться на многих связанных задачах, укрепляя её общие навыки. Другие архитектуры дают модели возможность обращаться к внешним базам данных при ответах, делая выводы более привязанными к реальной химии и биологии и сокращая число выдуманных утверждений. Затем небольшие раунды контролируемого обучения настраивают модель на конкретные задачи, такие как предсказание безопасности лекарств или планирование реакции. В обзоре также рассматриваются крупные публичные наборы данных и бенчмарки, которые позволяют оценить, действительно ли новая модель лучше, а не просто больше. 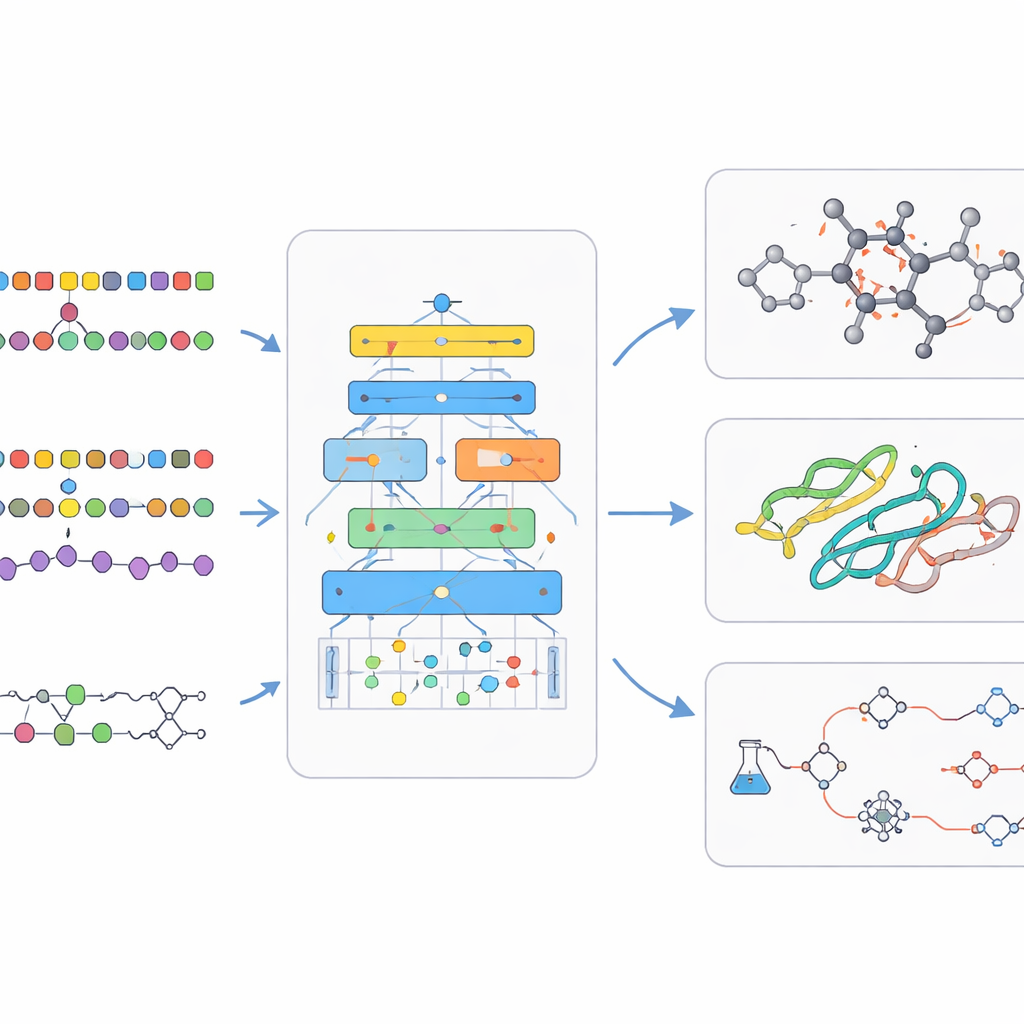
К ассистентам в лаборатории и ответственному использованию
Помимо отдельных моделей авторы подчёркивают сдвиг в сторону интерактивных «агентных» систем. В таких схемах языковая модель может вызывать специализированные инструменты — например, программу для проверки реакций, поиск литературы или управление лабораторными роботами — и последовательно объединять их результаты. Ранние демонстрации показывают, что такие агенты предлагают маршруты синтеза, проектируют эксперименты и даже управляют автоматизированными лабораториями. Авторы делают вывод, что при сочетании с надёжными мерами предосторожности, прозрачной оценкой и вниманием к этике и регулированию эти биохимические языковые модели могут стать ключевой инфраструктурой для науки. Для неспециалистов главный посыл таков: ИИ учится читать и писать код жизни и материи, сокращая путь от идеи до лекарства, материала или биологического открытия.
Цитирование: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Ключевые слова: большие языковые модели, поиск лекарств, структура белка, химические языковые модели, геномика