Clear Sky Science · es
Una revisión sobre modelos de lenguaje grande en biología y química
Enseñar a las computadoras el lenguaje de las moléculas
La biología y la química modernas generan hoy más datos de los que cualquier persona podría leer. Este artículo explica cómo los modelos de lenguaje grande —el mismo tipo de IA detrás de los chatbots— se están reconvirtiendo para leer y escribir los “lenguajes” del ADN, las proteínas y las moléculas pequeñas. Para un lector general, el atractivo es evidente: estas herramientas prometen acelerar el descubrimiento de fármacos, mejorar la comprensión de las enfermedades e incluso ofrecer ordenadores que ayuden a planificar y ejecutar experimentos en el laboratorio.
De palabras y oraciones a genes y moléculas
Los modelos de lenguaje se construyeron originalmente para predecir la siguiente palabra en una frase. Los científicos se dieron cuenta de que muchos registros biológicos y químicos, como las secuencias de proteínas o las codificaciones lineales de moléculas, también se parecen a cadenas de caracteres. Si una IA puede aprender patrones en el lenguaje natural, podría también aprender patrones que vinculen una secuencia génica con su función en la célula, o una fórmula química con sus propiedades. La revisión muestra cómo los investigadores convierten con cuidado moléculas y células tridimensionales complejas en cadenas unidimensionales, grafos o nubes de puntos que una IA puede manejar. Este paso de diseño es crucial, porque la forma en que se representa la información limita lo que el modelo puede aprender y qué tipos de descubrimientos puede realizar. 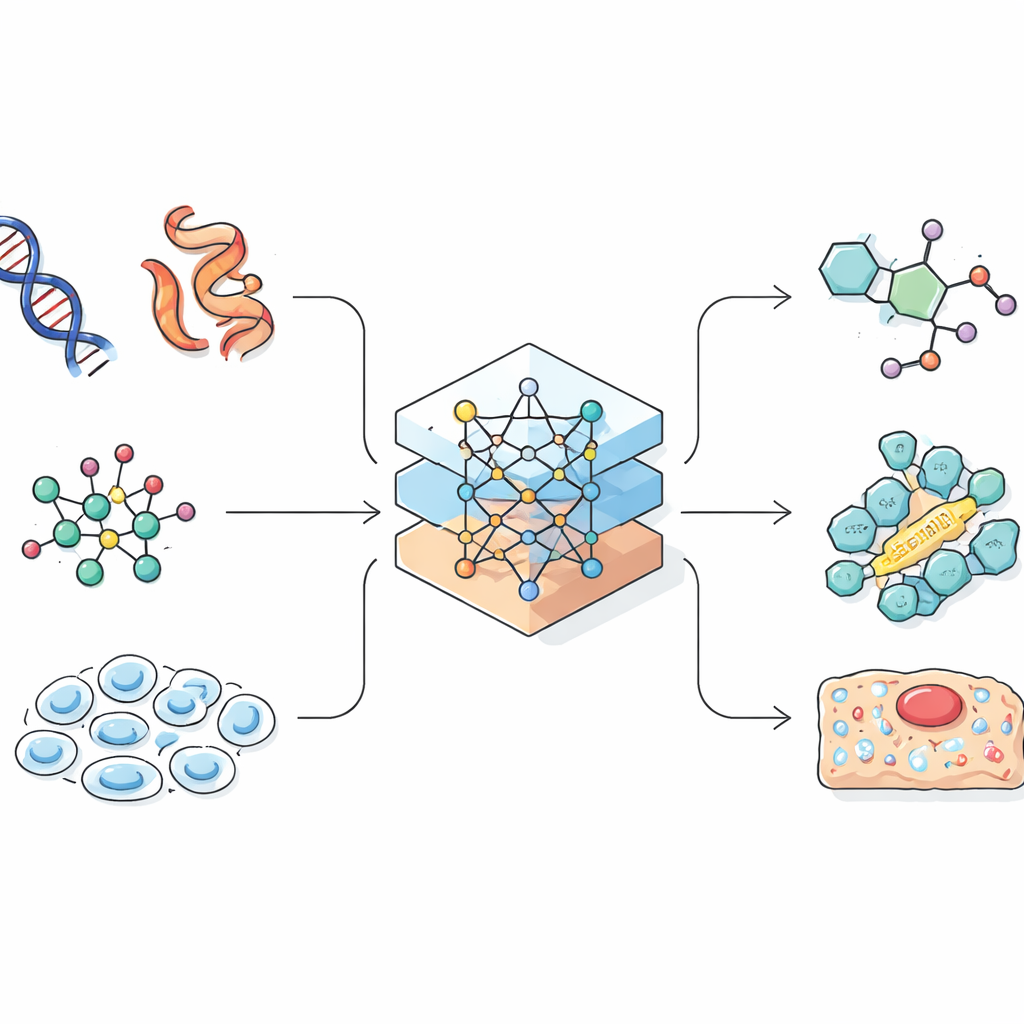
Leer proteínas, ADN y la vida de células individuales
Un foco importante son los “modelos de lenguaje biológico” que trabajan con sistemas vivos. Para las proteínas, modelos entrenados con millones de secuencias pueden ahora predecir cómo una cadena lineal de aminoácidos se plegará en una estructura tridimensional, rivalizando con técnicas de laboratorio laboriosas. Algunos modelos van más allá y proponen nuevos diseños de proteínas que nunca existieron en la naturaleza pero que podrían actuar como fármacos o enzimas industriales. Para el ADN y el ARN, los investigadores adaptan el modelado de lenguaje para manejar largas cadenas formadas por solo cuatro letras, lo que permite a la IA detectar regiones reguladoras del genoma o predecir los efectos de mutaciones. A nivel celular, nuevos enfoques tratan el perfil de actividad génica de cada célula como un documento cuyas “palabras” son genes, lo que permite a los modelos agrupar tipos celulares, prever cómo responden las células a tratamientos y conectar datos de laboratorio con el conocimiento biológico previo.
Darle a la química su propia gramática digital
Los modelos de lenguaje químicos abordan el mundo de las moléculas pequeñas, como los candidatos a fármacos. Aquí, los químicos usan códigos compactos tipo texto para describir estructuras, que pueden introducirse en modelos de lenguaje de forma similar a las oraciones. Los modelos de estilo encoder se centran en la comprensión: aprenden una huella interna rica para cada molécula que ayuda a predecir propiedades como solubilidad o toxicidad. Los modelos de estilo decoder se centran en la creación: generan nuevas moléculas paso a paso, mientras se les orienta hacia rasgos deseados. Modelos pareados que traducen una secuencia a otra se usan para predecir el resultado de reacciones o sugerir maneras de sintetizar un compuesto objetivo. Sistemas más avanzados combinan texto, dibujos bidimensionales, formas tridimensionales y grafos para que la IA pueda razonar a través de múltiples maneras de describir la misma química.
Cómo aprenden y mejoran estos modelos
En el fondo, los modelos bio‑químicos de lenguaje se apoyan en trucos de entrenamiento ingeniosos. A menudo comienzan con aprendizaje auto-supervisado, en el que la IA aprende a adivinar piezas faltantes del input, obligándola a captar la estructura subyacente sin etiquetas humanas. El entrenamiento multitarea permite que un único modelo practique muchos problemas relacionados a la vez, fortaleciendo sus habilidades generales. Otros diseños permiten que el modelo consulte bases de datos externas mientras responde preguntas, anclando sus salidas en química y biología reales y reduciendo afirmaciones inventadas. Posteriormente, pequeñas rondas de entrenamiento supervisado afinan el modelo en tareas específicas, como predecir la seguridad de un fármaco o planificar una reacción. La revisión también repasa los grandes conjuntos de datos públicos y los benchmarks que hacen posible juzgar si un nuevo modelo es realmente mejor, en lugar de simplemente más grande. 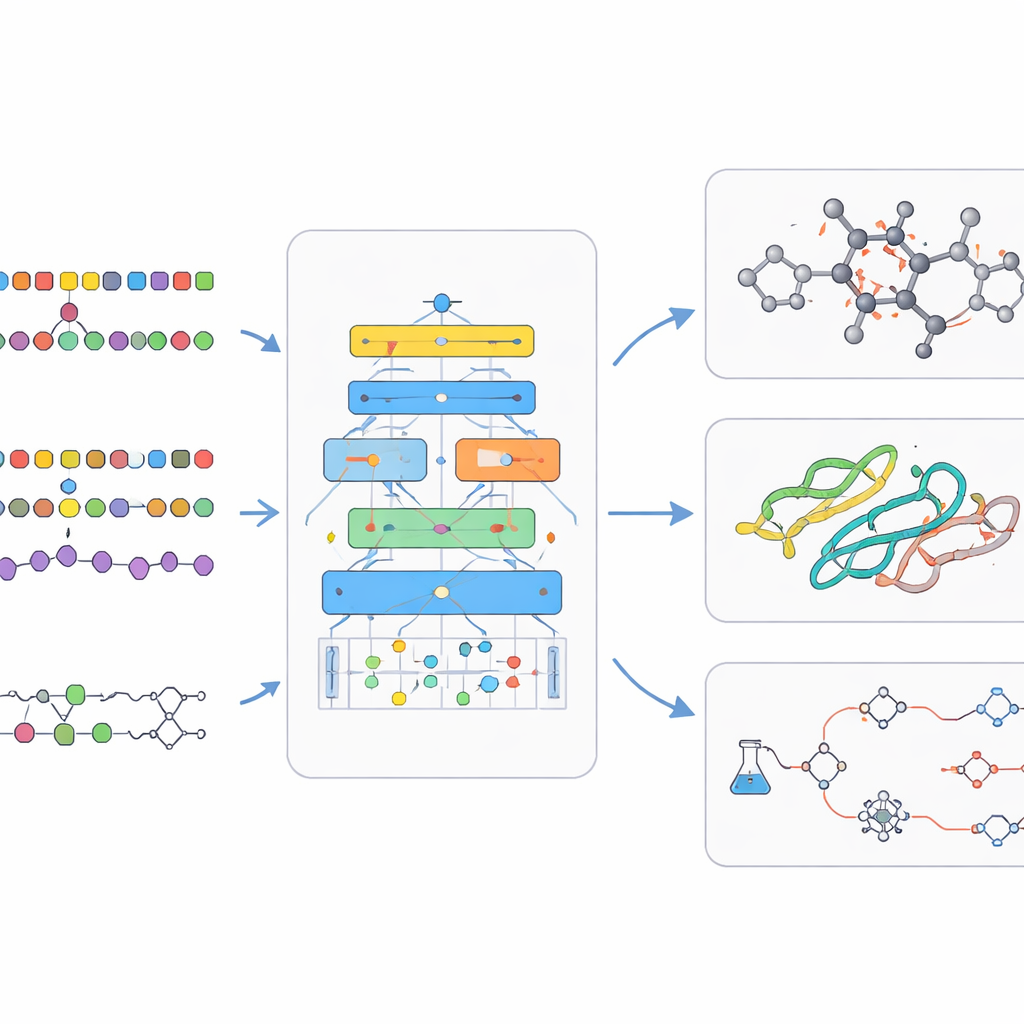
Hacia asistentes de laboratorio con IA y un uso responsable
Más allá de los modelos aislados, los autores destacan un cambio hacia sistemas interactivos “agentes”. En estas configuraciones, un modelo de lenguaje puede invocar herramientas especializadas —por ejemplo, un programa que verifica reacciones, busca en la literatura o controla robots de laboratorio— y encadenar sus salidas. Demostraciones tempranas muestran a tales agentes proponiendo rutas de síntesis, diseñando experimentos e incluso dirigiendo laboratorios automatizados. La revisión concluye que, si se combinan con salvaguardas sólidas, evaluación transparente y atención cuidadosa a la ética y la regulación, estos modelos de lenguaje bio‑químicos podrían convertirse en infraestructura central para la ciencia. Para los no expertos, el mensaje clave es que la IA está aprendiendo a leer y escribir el código de la vida y la materia, con el potencial de acortar el camino de la idea al medicamento, material o insight biológico.
Cita: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Palabras clave: modelos de lenguaje grande, descubrimiento de fármacos, estructura de proteínas, modelos de lenguaje químico, genómica