Clear Sky Science · pt
Uma revisão sobre grandes modelos de linguagem em biologia e química
Ensinando aos Computadores a Linguagem das Moléculas
A biologia e a química modernas agora geram mais dados do que qualquer pessoa conseguiria ler. Este artigo explica como grandes modelos de linguagem — o mesmo tipo de IA por trás de chatbots — estão sendo reaproveitados para ler e escrever as “linguagens” do DNA, das proteínas e das pequenas moléculas. Para um leitor leigo, o apelo é claro: essas ferramentas prometem acelerar a descoberta de fármacos, melhorar a compreensão de doenças e até oferecer computadores que ajudam a planejar e executar experimentos no laboratório.
Das Palavras e Sentenças aos Genes e Moléculas
Modelos de linguagem foram originalmente construídos para prever a próxima palavra em uma frase. Os cientistas perceberam que muitos registros biológicos e químicos, como sequências de proteínas ou codificações lineares de moléculas, também se parecem com cadeias de caracteres. Se uma IA pode aprender padrões na linguagem natural, ela talvez também aprenda padrões que ligam uma sequência gênica ao seu papel na célula, ou uma fórmula química às suas propriedades. A revisão mostra como os pesquisadores convertem cuidadosamente moléculas tridimensionais complexas e células em sequências unidimensionais, grafos ou nuvens de pontos que uma IA consegue manipular. Essa etapa de projeto é crucial, porque a forma como a informação é representada limita o que o modelo pode aprender e que tipos de descobertas ele pode fazer. 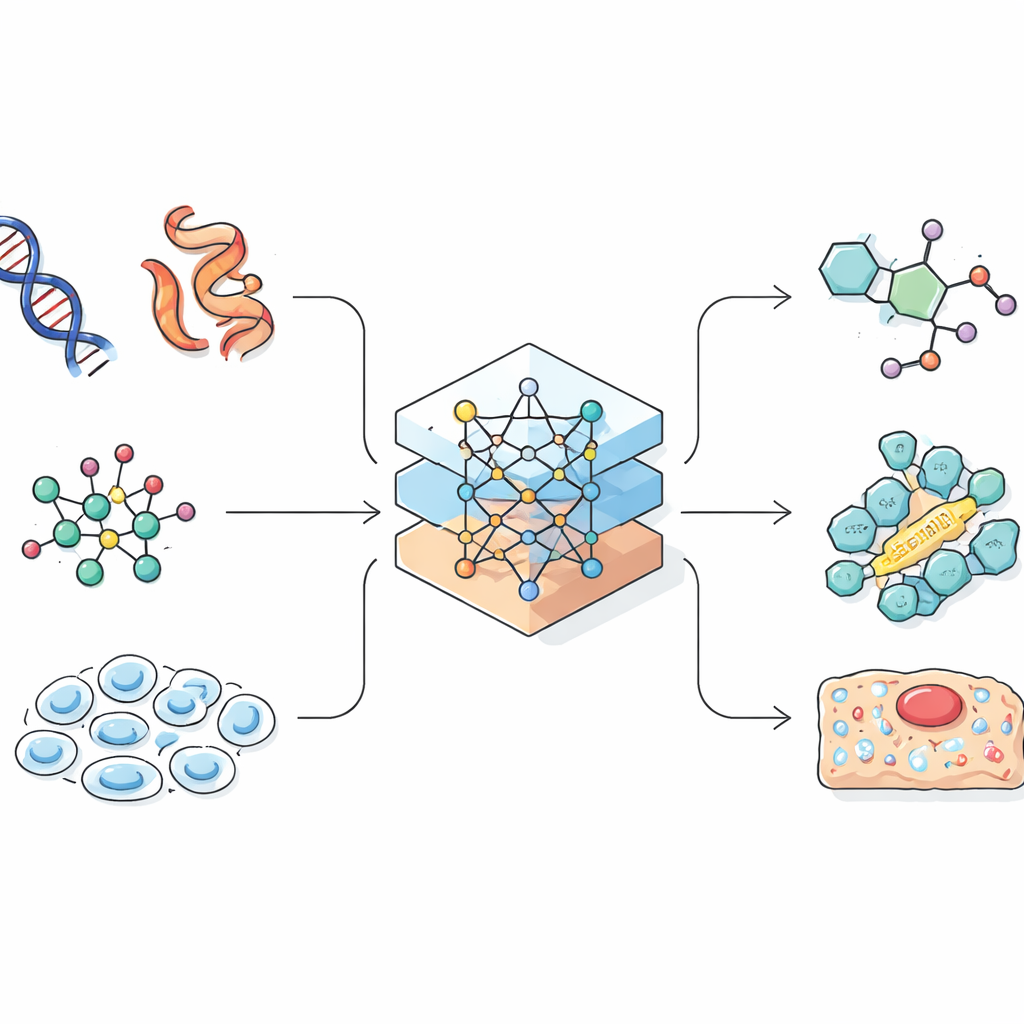
Lendo Proteínas, DNA e a Vida de Células Individuais
Um foco importante são os “modelos de linguagem biológica” que trabalham com sistemas vivos. Para proteínas, modelos treinados em milhões de sequências já conseguem prever como uma cadeia linear de aminoácidos se dobrará em uma estrutura tridimensional, rivalizando técnicas laboriosas de laboratório. Alguns modelos vão além, sugerindo novos designs de proteínas que nunca existiram na natureza, mas que podem funcionar como fármacos ou enzimas industriais. Para DNA e RNA, os pesquisadores adaptam o modelamento de linguagem para lidar com longas sequências formadas por apenas quatro letras, permitindo que a IA identifique regiões de controle no genoma ou preveja os efeitos de mutações. No nível celular, novas abordagens tratam o perfil de atividade gênica de cada célula como um documento cujas “palavras” são genes, permitindo aos modelos agrupar tipos celulares, prever como as células respondem a tratamentos e conectar dados de laboratório ao conhecimento biológico prévio.
Dando à Química Sua Própria Gramática Digital
Modelos de linguagem química lidam com o mundo das pequenas moléculas, como candidatos a fármacos. Aqui, químicos usam códigos compactos semelhantes a texto para descrever estruturas, que podem ser alimentados aos modelos de linguagem como se fossem sentenças. Modelos do tipo encoder focam em compreensão: aprendem uma impressão digital interna rica para cada molécula que ajuda a prever propriedades como solubilidade ou toxicidade. Modelos do tipo decoder focam na criação: geram moléculas inteiramente novas, passo a passo, sendo guiados em direção a traços desejados. Modelos pareados que traduzem uma sequência em outra são usados para prever o resultado de reações ou sugerir maneiras de sintetizar um composto alvo. Sistemas mais avançados misturam texto, desenhos bidimensionais, formas tridimensionais e grafos para que a IA possa raciocinar através de várias formas de descrever a mesma química.
Como Esses Modelos Aprendem e Melhoram
Por trás das cenas, os modelos bio‑químicos de linguagem dependem de artifícios de treinamento inteligentes. Frequentemente começam com aprendizado auto-supervisionado, no qual a IA aprende a adivinhar partes ausentes do input, forçando-a a captar a estrutura subjacente sem rótulos humanos. Treinamento multitarefa permite que um único modelo pratique muitos problemas relacionados ao mesmo tempo, fortalecendo suas habilidades gerais. Outros projetos permitem que o modelo consulte bancos de dados externos enquanto responde perguntas, fundamentando suas saídas na química e biologia reais e reduzindo afirmações inventadas. Depois, rodadas menores de treinamento supervisionado afinam o modelo em tarefas específicas, como prever segurança de fármacos ou planejar uma reação. A revisão também analisa os grandes conjuntos de dados públicos e benchmarks que tornam possível avaliar se um novo modelo é realmente melhor, e não apenas maior. 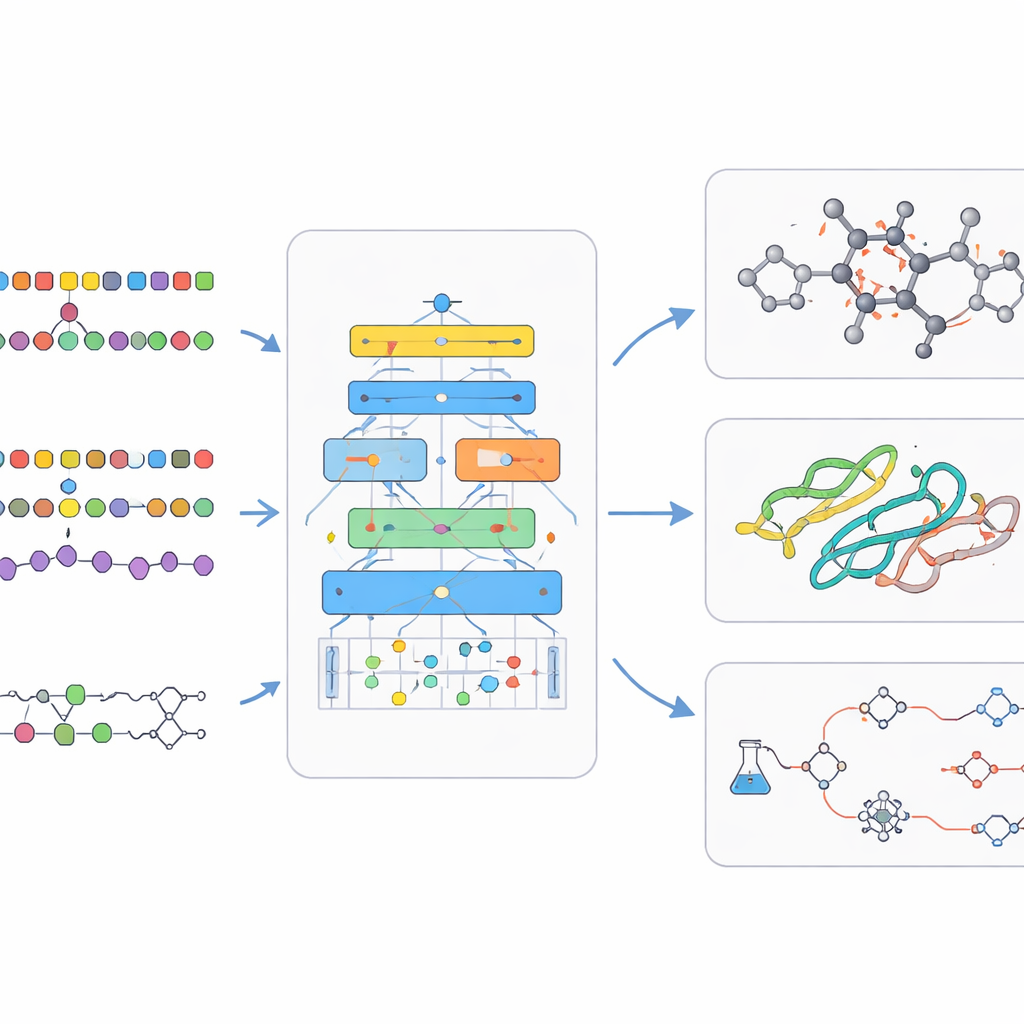
Rumo a Assistentes de Laboratório por IA e Uso Responsável
Além dos modelos isolados, os autores destacam uma mudança rumo a sistemas interativos “agentes”. Nesses arranjos, um modelo de linguagem pode chamar ferramentas especializadas — por exemplo, um programa que verifica reações, busca a literatura ou controla robôs de laboratório — e encadear suas saídas. Demonstrações iniciais mostram tais agentes propondo rotas de síntese, desenhando experimentos e até operando laboratórios automatizados. A revisão conclui que, se combinados com salvaguardas fortes, avaliação transparente e atenção cuidadosa à ética e à regulação, esses modelos bio‑químicos de linguagem podem se tornar infraestrutura central para a ciência. Para não especialistas, a mensagem principal é que a IA está aprendendo a ler e escrever o código da vida e da matéria, com potencial para encurtar o caminho da ideia até um remédio, material ou insight biológico.
Citação: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Palavras-chave: grandes modelos de linguagem, descoberta de fármacos, estrutura de proteínas, modelos de linguagem química, genômica