Clear Sky Science · en
A survey on large language models in biology and chemistry
Teaching Computers the Language of Molecules
Modern biology and chemistry now generate more data than any human could read. This article explains how large language models—the same kind of AI behind chatbots—are being repurposed to read and write the “languages” of DNA, proteins and small molecules. For a lay reader, the appeal is clear: these tools promise faster drug discovery, better understanding of diseases and even computers that help plan and run experiments in the lab.
From Words and Sentences to Genes and Molecules
Language models were originally built to predict the next word in a sentence. Scientists realized that many biological and chemical records, such as protein sequences or linear encodings of molecules, also look like strings. If an AI can learn patterns in natural language, it might also learn patterns that link a gene sequence to its role in a cell, or a chemical formula to its properties. The review shows how researchers carefully convert complex three-dimensional molecules and cells into one-dimensional strings, graphs or point clouds that an AI can handle. This design step is crucial, because the way information is represented limits what the model can learn and what kinds of discoveries it can make. 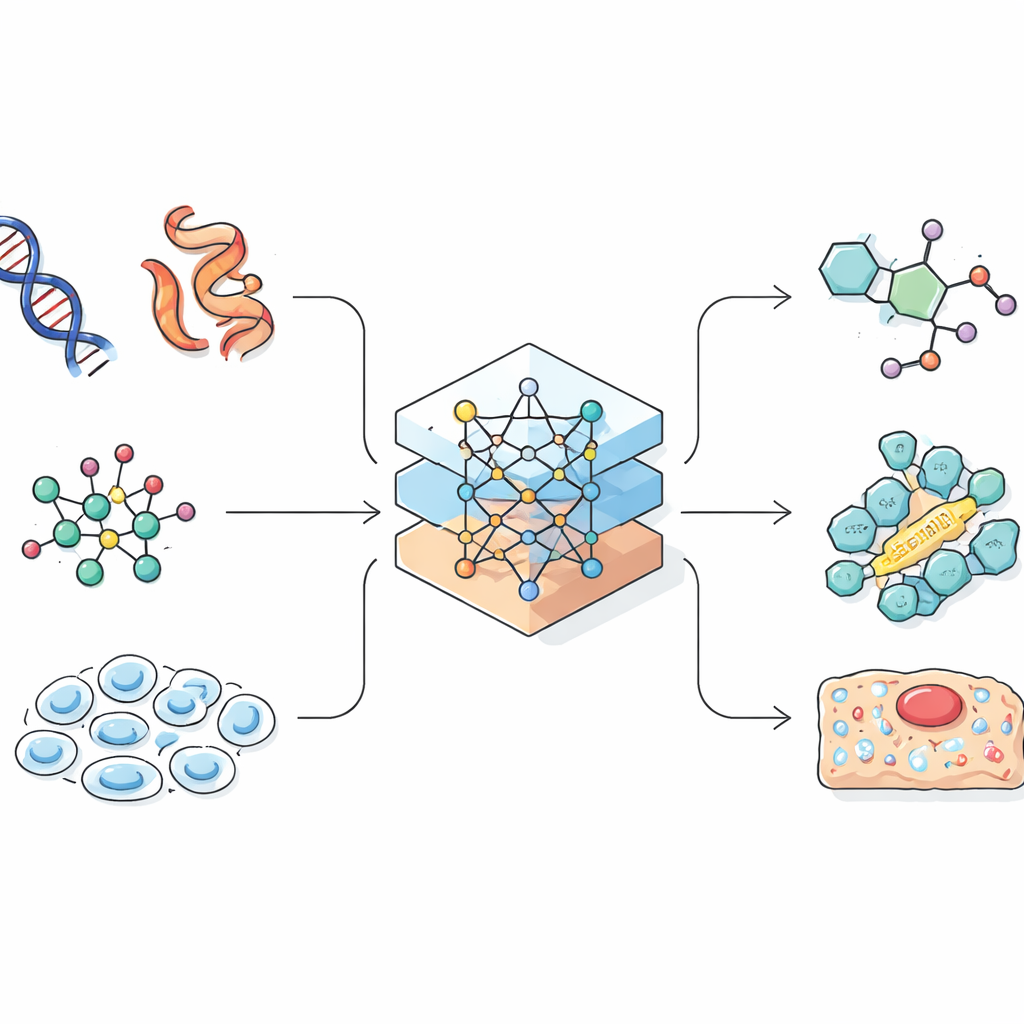
Reading Proteins, DNA and the Life of Single Cells
One major focus is on “biological language models” that work with living systems. For proteins, models trained on millions of sequences can now predict how a linear chain of amino acids will fold into a three-dimensional structure, rivaling painstaking lab techniques. Some models go further, suggesting new protein designs that never existed in nature but might act as drugs or industrial enzymes. For DNA and RNA, researchers adapt language modeling to handle long strings built from just four letters, enabling AI to spot control regions in the genome or to predict the effects of mutations. At the cell level, new approaches treat each cell’s gene activity profile like a document whose “words” are genes, allowing models to cluster cell types, forecast how cells respond to treatments and connect lab data to prior biological knowledge.
Giving Chemistry Its Own Digital Grammar
Chemical language models tackle the world of small molecules, such as drug candidates. Here, chemists use compact text-like codes to describe structures, which can be fed to language models much like sentences. Encoder-style models focus on understanding: they learn a rich internal fingerprint for each molecule that helps predict properties like solubility or toxicity. Decoder-style models focus on creation: they generate brand new molecules, step by step, while being nudged toward desired traits. Paired models that translate one sequence into another are used to predict the outcome of reactions or suggest ways to synthesize a target compound. More advanced systems mix text, two-dimensional drawings, three-dimensional shapes and graphs so that the AI can reason across many ways of describing the same chemistry.
How These Models Learn and Improve
Under the hood, bio‑chemical language models rely on clever training tricks. They often start with self-supervised learning, in which the AI learns to guess missing pieces of input, forcing it to grasp underlying structure without human labels. Multitask training lets a single model practice many related problems at once, strengthening its general skills. Other designs let the model look up external databases while answering questions, grounding its outputs in real chemistry and biology and reducing made-up claims. Afterwards, smaller rounds of supervised training tune the model on specific tasks such as predicting drug safety or planning a reaction. The review also surveys the large public datasets and benchmarks that make it possible to judge whether a new model is truly better, rather than just bigger. 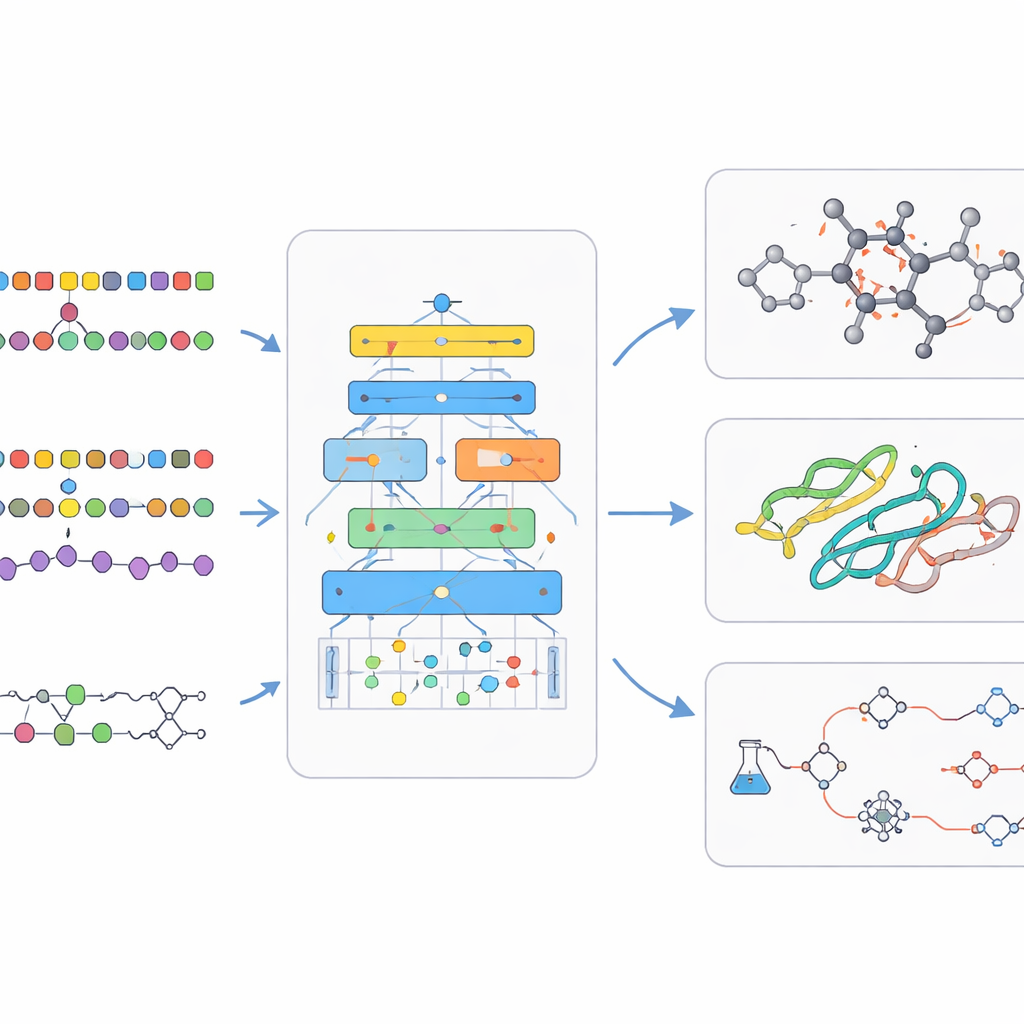
Toward AI Lab Assistants and Responsible Use
Beyond standalone models, the authors highlight a shift toward interactive “agentic” systems. In these setups, a language model can call specialized tools—for example, a program that checks reactions, searches the literature or controls lab robots—and chain their outputs together. Early demonstrations show such agents proposing synthesis routes, designing experiments and even steering automated laboratories. The review concludes that, if paired with strong safeguards, transparent evaluation and careful attention to ethics and regulation, these bio‑chemical language models could become core infrastructure for science. For non-experts, the key message is that AI is learning to read and write the code of life and matter, with the potential to shorten the path from idea to medicine, material or biological insight.
Citation: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Keywords: large language models, drug discovery, protein structure, chemical language models, genomics