Clear Sky Science · sv
En översikt över stora språkmodeller inom biologi och kemi
Att lära datorer molekylernas språk
Modern biologi och kemi genererar nu mer data än vad någon människa kan läsa igenom. Den här artikeln förklarar hur stora språkmodeller — samma sorts AI som ligger bakom chattbotar — omorienteras för att läsa och skriva DNA:s, proteiners och småmolekylers ”språk”. För en allmän läsare är lockelsen tydlig: dessa verktyg lovar snabbare läkemedelsupptäckt, bättre förståelse av sjukdomar och till och med datorer som hjälper till att planera och genomföra experiment i laboratoriet.
Från ord och meningar till gener och molekyler
Språkmodeller byggdes ursprungligen för att förutsäga nästa ord i en mening. Forskare insåg att många biologiska och kemiska register, såsom proteinsekvenser eller linjära kodningar av molekyler, också ser ut som strängar. Om en AI kan lära sig mönster i naturligt språk kan den kanske också lära sig mönster som kopplar en gensekvens till dess roll i en cell, eller en kemisk formel till dess egenskaper. Översikten visar hur forskare omsorgsfullt konverterar komplexa tredimensionella molekyler och celler till endimensionella strängar, grafer eller punktskyar som en AI kan hantera. Detta designsteg är avgörande, eftersom sättet information representeras på begränsar vad modellen kan lära sig och vilka slags upptäckter den kan göra. 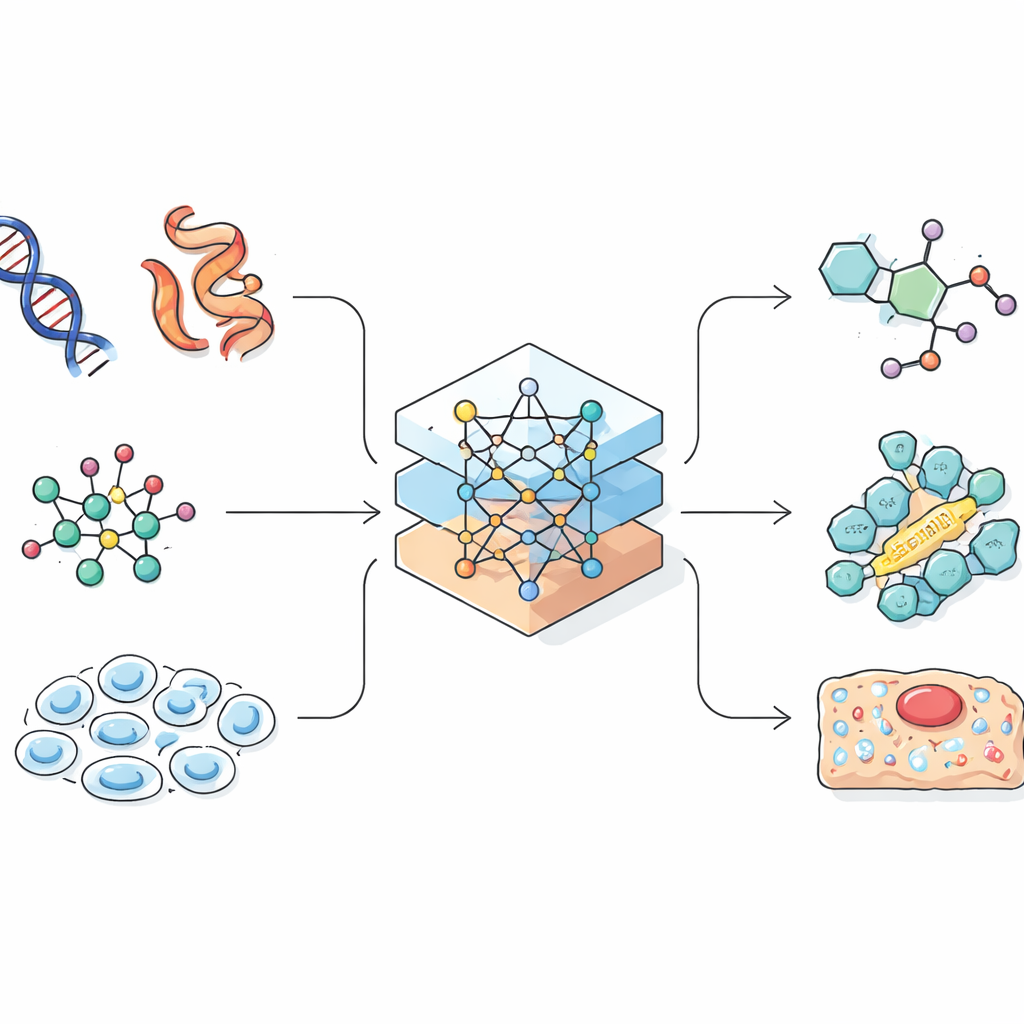
Att läsa proteiner, DNA och enskilda cellers liv
En huvudfokus ligger på ”biologiska språkmodeller” som arbetar med levande system. För proteiner kan modeller tränade på miljontals sekvenser nu förutsäga hur en linjär kedja av aminosyror veckar sig till en tredimensionell struktur, och konkurrera med mödosamma laboratorietekniker. Vissa modeller går längre och föreslår nya proteinstrukturdesigner som aldrig funnits i naturen men kan fungera som läkemedel eller industriella enzymer. För DNA och RNA anpassar forskare språkmodellering för att hantera långa strängar byggda av endast fyra bokstäver, vilket gör det möjligt för AI att upptäcka kontrollregioner i genomet eller förutsäga effekter av mutationer. På cellnivå behandlar nya angreppssätt varje cells genaktivitetsprofil som ett dokument vars ”ord” är gener, vilket gör att modeller kan klustra celltyper, förutsäga hur celler svarar på behandlingar och koppla laboratoriedata till befintlig biologisk kunskap.
Att ge kemin sin egen digitala grammatik
Kemiska språkmodeller tar sig an världen av små molekyler, som läkemedelskandidater. Här använder kemister kompakta textliknande koder för att beskriva strukturer, vilka kan matas in i språkmodeller ungefär som meningar. Encoder‑stil modeller fokuserar på förståelse: de lär sig ett rikt internt fingeravtryck för varje molekyl som hjälper till att förutsäga egenskaper som löslighet eller toxicitet. Decoder‑stil modeller fokuserar på skapande: de genererar helt nya molekyler steg för steg, samtidigt som de styrs mot önskade egenskaper. Parade modeller som översätter en sekvens till en annan används för att förutsäga utfall av reaktioner eller föreslå sätt att syntetisera en målförening. Mer avancerade system blandar text, tvådimensionella ritningar, tredimensionella former och grafer så att AI:n kan resonera över flera sätt att beskriva samma kemi.
Hur dessa modeller lär sig och förbättras
Under huven förlitar sig bio‑kemiska språkmodeller på smarta träningsknep. De börjar ofta med självövervakad inlärning, där AI:n lär sig att gissa saknade delar av indata och tvingas förstå underliggande struktur utan mänskliga etiketter. Multitask‑träning låter en enda modell öva många besläktade problem samtidigt och stärker dess generella förmågor. Andra konstruktioner låter modellen slå upp externa databaser medan den svarar, vilket förankrar dess utdata i verklig kemi och biologi och minskar påhittade påståenden. Därefter finjusteras modellen i mindre omgångar med övervakad träning för specifika uppgifter som att förutsäga läkemedelssäkerhet eller planera en reaktion. Översikten täcker också stora publika dataset och benchmarks som gör det möjligt att bedöma om en ny modell verkligen är bättre, och inte bara större. 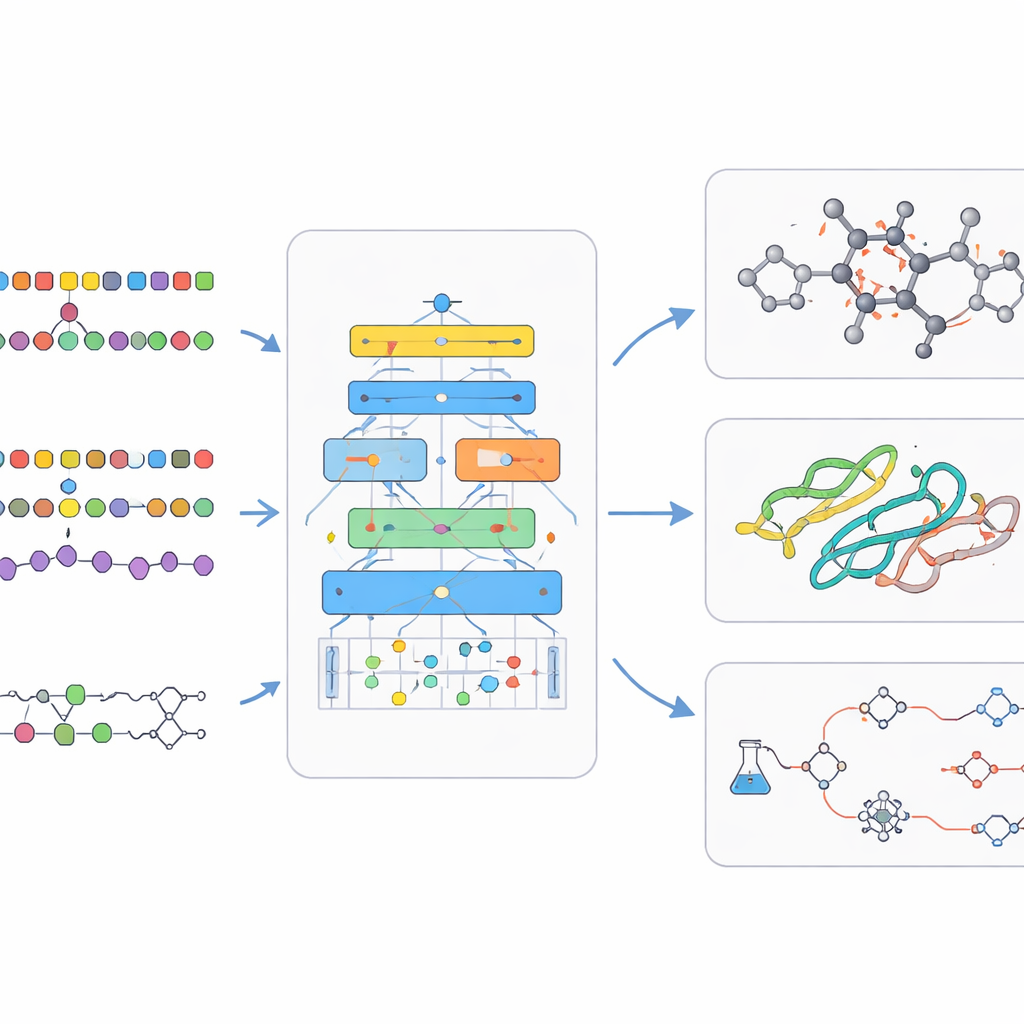
Mot AI‑labassistenter och ansvarsfull användning
Bortom fristående modeller lyfter författarna fram en förskjutning mot interaktiva ”agentiska” system. I dessa uppsättningar kan en språkmodell anropa specialiserade verktyg — till exempel ett program som kontrollerar reaktioner, söker i litteraturen eller styr labbrobotar — och kedja ihop deras resultat. Tidiga demonstrationer visar sådana agenter som föreslår syntesvägar, designar experiment och till och med styr automatiserade laboratorier. Översikten avslutar med att konstatera att, om de paras med starka skyddsåtgärder, transparent utvärdering och noggrann uppmärksamhet på etik och reglering, kan dessa bio‑kemiska språkmodeller bli kärninfrastruktur för vetenskapen. För icke‑experter är huvudbudskapet att AI lär sig läsa och skriva livets och materiens kod, med potential att förkorta vägen från idé till läkemedel, material eller biologisk insikt.
Citering: Ashyrmamatov, I., Gwak, S.J., Jin, SY. et al. A survey on large language models in biology and chemistry. Exp Mol Med 58, 970–980 (2026). https://doi.org/10.1038/s12276-025-01583-1
Nyckelord: stora språkmodeller, läkemedelsupptäckt, proteinstruktur, kemiska språkmodeller, genomik