Clear Sky Science · tr
Denetimli makine öğrenimi saldırı tespiti incelemesi ve çok ölçütlü değerlendirme
Dijital kapıları korumanın önemi
İnternette gezinirken, mesaj gönderirken veya film izlerken, görünmez güvenlik sistemleri arka planda bilgisayar korsanlarını uzak tutmak için çalışır. Bu saldırı tespit sistemleri, saldırı belirtilerini yakalamak için ağ trafiği okyanuslarını eleyip inceler. Ancak bu tür algılayıcılar oluşturmanın pek çok yolu vardır ve her birinin hız, doğruluk ve güvenilirlik açısından ödünleşmeleri bulunur. Bu makale pratik bir soru sorar: tüm bu seçenekler göz önüne alındığında hangi saldırı tespit yöntemleri gerçekten en iyisidir ve bunları adil biçimde nasıl karşılaştırabiliriz?
Bilgisayarlar saldırganları nasıl öğrenir
Modern saldırı tespiti genellikle denetimli makine öğrenimine dayanır; bu yaklaşımlarda algoritmalar geçmişteki “normal” ve “saldırı” bağlantı örnekleri üzerinde eğitilir. Eğitildikten sonra bu modeller yeni trafiği güvenli veya şüpheli olarak etiketlemeye çalışır. Makale bu iş için kullanılan yaygın algoritma ailelerini —k‑en yakın komşu, karar ağaçları, rastgele ormanlar, destek vektör makineleri, sinir ağları ve Naïve Bayes gibi— açıklar. Her birinin güçlü ve zayıf yönleri vardır: bazıları çok sayıda özellik ile iyi başa çıkar, bazıları düzensiz veya dengesiz verilerde öne çıkar, bazıları ise hızlı ama daha az doğru olur. Gerçek dünya sistemleri ayrıca veri temizleme, metin alanlarını sayılara dönüştürme, ölçekleri normalize etme ve en bilgilendirici özellikleri seçme gibi destekleyici adımlara da büyük oranda bağımlıdır.
Algılayıcıları karşılaştırmak göründüğünden daha zordur
İlk bakışta “en iyi” saldırı algılayıcısını seçmek en yüksek doğruluğa sahip olanı seçmek kadar basit görünebilir. Yazarlar bunun neden yanıltıcı olduğunu gösterir. Saldırı veri kümeleri genellikle son derece dengesizdir; normal trafikten çok daha az saldırı vardır, dolayısıyla doğruluk ciddi kör noktaları gizleyebilir. Kesinlik, geri çağırma, yanlış alarm oranı, F‑ölçüsü gibi birçok başka ölçüt vardır; ayrıca eğitim süresi ve bir modelin canlı bir bağlantıyı ne kadar hızlı işaretleyebildiği gibi çok pratik endişeler de bulunur. Bir ölçütte iyileşmek diğerini kötüleştirebilir; örneğin biraz daha yüksek doğruluk elde etmek modeli gerçek zamanlı kullanım için çok yavaş hale getirebilir. Buna ek olarak, literatür çalışmalarında farklı veri kümeleri, farklı saldırı karışımları ve farklı ön işleme yöntemleri kullanılır; bu da yan yana karşılaştırmaları zorlaştırır.
Birçok ihtiyacı aynı anda tartan puan tahtası
Bunu ele almak için makale TOPSIS adı verilen bir karar verme yöntemine dayalı yapılandırılmış bir “puan tahtası” önerir. Tek bir sayıya odaklanmak yerine TOPSIS her algoritmayı bir alternatif, her performans ölçütünü ise bir kriter olarak ele alır. Bazı kriterler “fayda”dır (yüksek olması daha iyidir, örneğin geri çağırma), bazıları ise “maliyet”tir (düşük olması daha iyidir, örneğin hesaplama süresi). Yazarlar bunları üç geniş endişe başlığında gruplar: modelin eğitim verisi üzerindeki davranışı (model yanlılığı), yeni veriyi ne kadar iyi tahmin ettiği (tahmin yanlılığı) ve ne kadar zaman tükettiği. Ardından farklı değerlendirici tercihlerini yansıtmak için çeşitli ağırlık desenleri atarlar—örneğin saldırıları yakalamaya en çok önem veren biri, hıza önem veren biri veya denge arayan biri gibi. KDD, NSL‑KDD ve CICIDS2017 olmak üzere üç tanınmış veri kümesini kullanarak büyük bir sonuç tablosu oluştururlar, sayıları karşılaştırılabilir hâle getirmek için normalize ederler, seçilen ağırlıkları uygularlar ve her algoritmanın ideal “en iyi” ve ideal “en kötü” algılayıcıya ne kadar yakın olduğunu hesaplarlar.
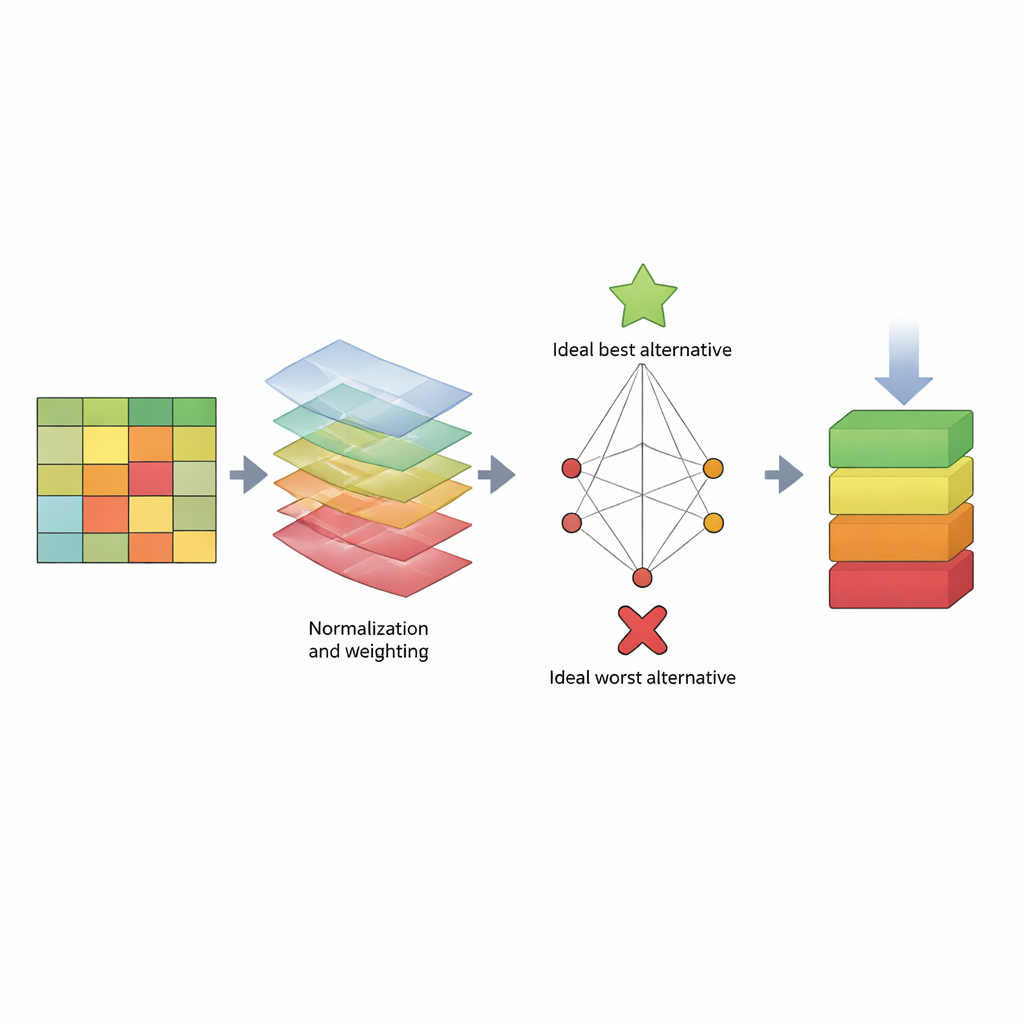
Popüler yöntemler hakkında sıralamalar ne gösteriyor
Çeşitli ağırlıklandırma stilleri ve üç veri setinin tamamı boyunca belirgin bir desen ortaya çıkar. Ağaç tabanlı yöntemler—özellikle Random Tree, C4.5 karar ağaçları ve Random Forest—sıralamalarda tekrar tekrar en üst sıralarda veya ona yakın yerlerde bulunur. Bunlar güçlü tespit skorlarını makul eğitim ve test süreleriyle birleştirir ve değerlendirici tercihleri değişse bile rekabetçi kalırlar. Buna karşılık Naïve Bayes yaklaşımı, özellikle daha zorlu NSL‑KDD ve CICIDS2017 veri kümelerinde sürekli olarak sondan yakın sıralarda yer alır. Özelliklerin bağımsız davrandığına dair basit varsayımı karmaşık ağ trafiği için geçerli olmaz ve bu da ince, yüksek boyutlu saldırı örüntülerinin kötü işlenmesine yol açar. Çalışma ayrıca farklı kriterlerin öneminin değiştirilmesinin ortadaki grubu yeniden düzenleyebileceğini; ancak en iyi ve en kötü performans gösterenlerin büyük ölçüde sabit kaldığını gösterir.
Ağ güvenliği için bunun anlamı
Uzman olmayanlar için çıkarılacak ders şudur: tek bir “sihirli” saldırı algılayıcısı yoktur, ancak seçenekleri disiplinli ve şeffaf bir biçimde karşılaştırabiliriz. Model seçimlerini ham doğruluk yarışması yerine çok ölçütlü bir karar olarak ele alarak yazarlar, özellikle ağaç tabanlı algoritma ailelerinin pek çok durumda güvenilir güçlü seçimler olduğunu; bazı yöntemlerin ise risk taşıdığını gösterir. TOPSIS tabanlı çerçeveleri yeniden kullanılabilir bir derecelendirme sistemi gibi çalışır: yeni veri kümeleri ve algoritmalar ortaya çıktıkça aynı sürece eklenebilir ve hangi araçların saldırıları hızlı yakalama, yanlış alarmları sınırlama ve hesaplama açısından pratik kalma dengesini en iyi sunduğunu ortaya koyar.
Atıf: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Anahtar kelimeler: saldırı tespiti, makine öğrenimi güvenliği, ağ saldırıları, algoritma değerlendirmesi, çok ölçütlü karar verme