Clear Sky Science · es
Revisión de detección de intrusiones con aprendizaje supervisado y evaluación multicriterio
Por qué importa proteger las puertas digitales
Cada vez que navegamos por la web, enviamos un mensaje o retransmitimos una película, sistemas de seguridad invisibles trabajan entre bastidores para mantener a los atacantes fuera. Estos sistemas de detección de intrusiones filtran océanos de tráfico de red para detectar señales de ataque. Pero existen muchas formas de construir esos detectores, y cada una conlleva compromisos en velocidad, precisión y fiabilidad. Este artículo plantea una pregunta práctica: dadas todas estas opciones, ¿qué métodos de detección de intrusiones son realmente los mejores y cómo podemos compararlos de manera justa?
Cómo aprenden los ordenadores a detectar intrusos
La detección de intrusiones moderna suele apoyarse en el aprendizaje supervisado, donde los algoritmos se entrenan con ejemplos previos de conexiones “normales” y “de ataque”. Una vez entrenados, estos modelos intentan etiquetar el tráfico nuevo como seguro o sospechoso. El artículo explica familias comunes de algoritmos usadas para esta tarea, como k‑nearest neighbors, árboles de decisión, random forests, máquinas de soporte vectorial, redes neuronales y Naïve Bayes. Cada uno tiene fortalezas y debilidades: algunos manejan bien un gran número de características, otros destacan con datos desordenados o desequilibrados, y algunos son rápidos pero menos precisos. Los sistemas del mundo real también dependen en gran medida de pasos de apoyo como la limpieza de datos, la codificación de campos de texto como números, la normalización de escalas y la selección de las características más informativas.
Por qué comparar detectores es más difícil de lo que parece
A primera vista, elegir el detector de intrusiones “mejor” podría parecer tan sencillo como escoger el de mayor exactitud. Los autores muestran por qué esto es engañoso. Los conjuntos de datos de intrusiones suelen estar muy desequilibrados, con mucho más tráfico normal que ataques, por lo que la exactitud puede ocultar puntos ciegos graves. Existen muchas otras medidas —como precisión, recall, tasa de falsas alarmas, F‑measure y más— junto con preocupaciones muy prácticas como el tiempo de entrenamiento y la rapidez con la que un modelo puede señalar una conexión en tiempo real. Mejorar una medida puede empeorar otra; por ejemplo, exprimir un poco más de exactitud puede hacer que el modelo sea demasiado lento para uso en tiempo real. Además, los trabajos de la literatura usan distintos conjuntos de datos, mezclas de ataques y pipelines de preprocesado diferentes, lo que dificulta las comparaciones directas.
Una hoja de puntuación que valora muchas necesidades a la vez
Para abordar esto, el artículo propone una “hoja de puntuación” estructurada basada en un método de toma de decisiones llamado TOPSIS. En lugar de centrarse en un solo número, TOPSIS trata cada algoritmo como una alternativa y cada medida de rendimiento como un criterio. Algunos criterios son “beneficios” (mejor cuanto mayor, como recall), mientras que otros son “costes” (mejor cuanto menor, como el tiempo de cómputo). Los autores agrupan estos criterios en tres preocupaciones amplias: cómo se comporta el modelo con los datos de entrenamiento (sesgo del modelo), qué tan bien predice datos nuevos (sesgo de predicción) y cuánto tiempo consume. Luego asignan distintos patrones de ponderación para reflejar diversas preferencias del evaluador —por ejemplo, alguien que prioriza detectar ataques, alguien que valora la velocidad o alguien que busca un equilibrio. Usando tres conjuntos de datos bien conocidos (KDD, NSL‑KDD y CICIDS2017), construyen una gran tabla de resultados, normalizan los números para que sean comparables, aplican las ponderaciones elegidas y calculan qué tan cerca queda cada algoritmo de un detector “ideal” mejor y de uno “ideal” peor.
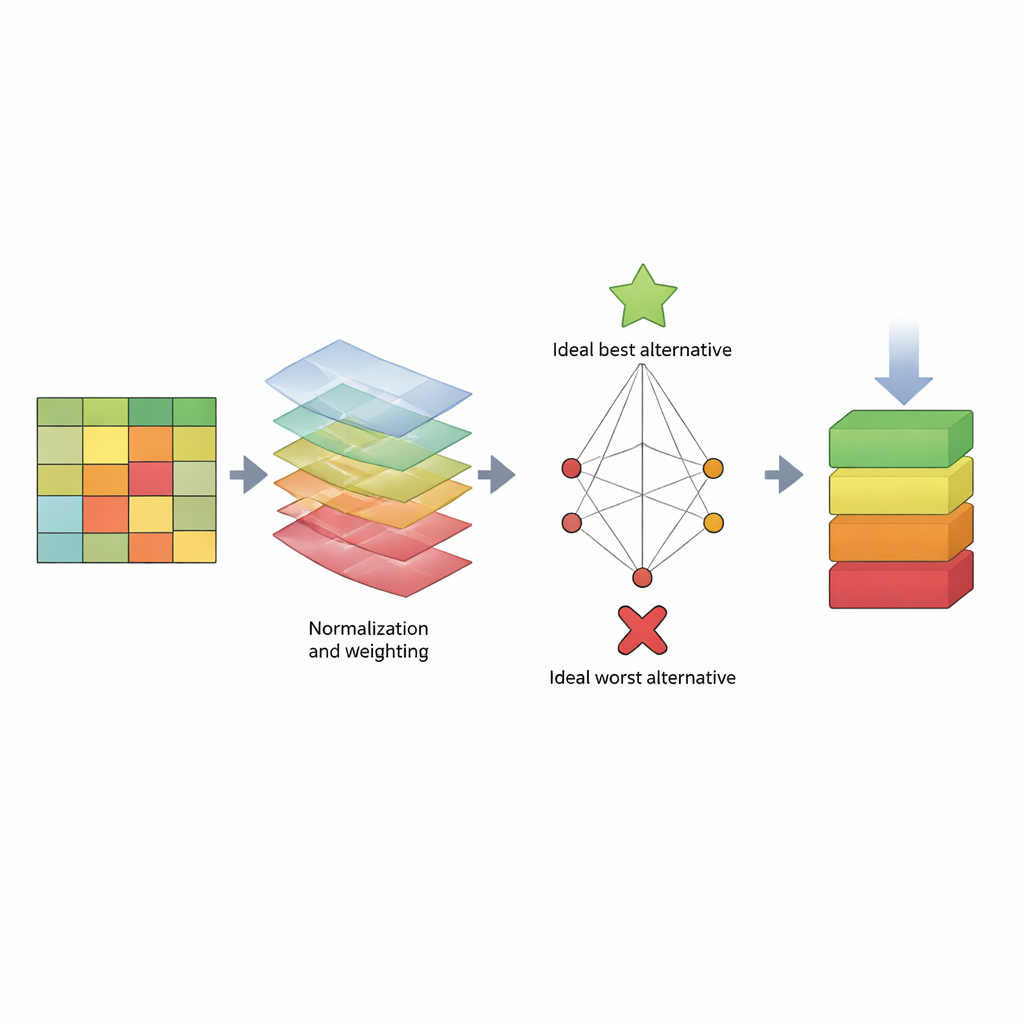
Qué revelan las clasificaciones sobre métodos populares
A través de muchos estilos de ponderación y los tres conjuntos de datos, emerge un patrón claro. Los métodos basados en árboles —particularmente Random Tree, árboles de decisión C4.5 y Random Forest— aparecen repetidamente en lo alto o cerca de la cima de las clasificaciones. Combinan buenas puntuaciones de detección con tiempos razonables de entrenamiento y prueba, y se mantienen competitivos incluso cuando cambian las preferencias del evaluador. En contraste, el enfoque Naïve Bayes se sitúa consistentemente en la parte baja, especialmente en los más desafiantes NSL‑KDD y CICIDS2017. Su suposición simple de que las características son independientes no se cumple en el tráfico de red complejo, lo que conduce a un manejo deficiente de patrones de ataque sutiles y de alta dimensionalidad. El estudio también muestra que, aunque cambiar la importancia de distintos criterios puede reorganizar la mitad del pelotón, los mejores y peores rendimientos permanecen en gran medida estables.
Qué significa esto para asegurar redes
Para no especialistas, la conclusión es que no existe un detector de intrusiones “mágico” único, pero sí podemos comparar opciones de forma disciplinada y transparente. Tratando la elección del modelo como una decisión multicriterio —en lugar de una contienda por la exactitud pura— los autores muestran que ciertas familias de algoritmos, especialmente las basadas en árboles, son opciones sólidas y fiables en muchas condiciones, mientras que otras resultan arriesgadas. Su marco basado en TOPSIS actúa como un sistema de valoración reutilizable: a medida que aparecen nuevos conjuntos de datos y algoritmos, se pueden integrar en el mismo proceso para revelar qué herramientas ofrecen el mejor equilibrio entre detectar ataques con rapidez, limitar falsas alarmas y mantenerse prácticas desde el punto de vista computacional.
Cita: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Palabras clave: detección de intrusiones, seguridad con aprendizaje automático, ataques de red, evaluación de algoritmos, toma de decisiones multicriterio