Clear Sky Science · fr
Revue des systèmes de détection d’intrusion supervisés et évaluation multicritère
Pourquoi il est important de protéger les portes numériques
Chaque fois que nous naviguons sur le web, envoyons un message ou regardons un film en streaming, des systèmes de sécurité invisibles travaillent en coulisses pour tenir les pirates à distance. Ces systèmes de détection d’intrusion filtrent d’immenses volumes de trafic réseau pour repérer des signes d’attaque. Mais il existe de nombreuses façons de concevoir de tels détecteurs, et chacune implique des compromis en matière de rapidité, de précision et de fiabilité. Cet article pose une question pratique : avec toutes ces options, quelles méthodes de détection d’intrusion sont réellement les meilleures, et comment les comparer de manière équitable ?
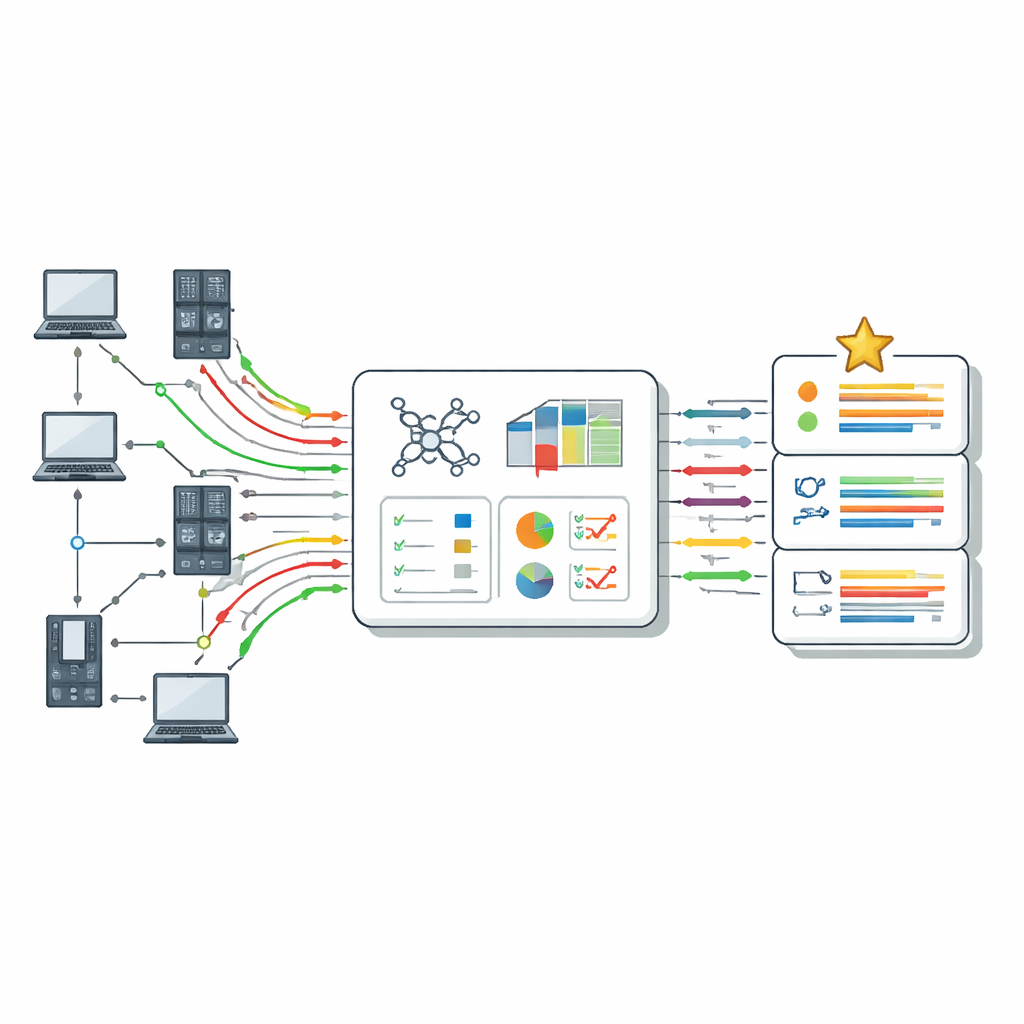
Comment les ordinateurs apprennent à repérer les intrus
La détection d’intrusion moderne repose souvent sur l’apprentissage supervisé, où des algorithmes sont entraînés sur des exemples passés de connexions « normales » et « d’attaque ». Une fois entraînés, ces modèles tentent d’étiqueter le nouveau trafic comme sûr ou suspect. L’article décrit les familles d’algorithmes couramment utilisées pour cette tâche, telles que k‑nearest neighbors, les arbres de décision, les forêts aléatoires, les machines à vecteurs de support, les réseaux neuronaux et le Naïve Bayes. Chacun présente des forces et des faiblesses : certains gèrent bien un très grand nombre de caractéristiques, d’autres excellent avec des données bruitées ou déséquilibrées, et certains sont rapides mais moins précis. Les systèmes réels dépendent également fortement d’étapes de support comme le nettoyage des données, le codage des champs textuels en nombres, la normalisation des échelles et la sélection des caractéristiques les plus informatives.
Pourquoi comparer les détecteurs est plus difficile qu’il n’y paraît
À première vue, choisir le « meilleur » détecteur d’intrusion pourrait sembler aussi simple que retenir celui qui atteint la plus grande précision. Les auteurs montrent pourquoi cela est trompeur. Les jeux de données d’intrusion sont souvent fortement déséquilibrés, avec bien plus de trafic normal que d’attaques, de sorte que la précision peut masquer des lacunes graves. De nombreuses autres mesures existent — comme la précision (precision), le rappel (recall), le taux de fausses alertes, la F‑mesure, et plus encore — en plus de préoccupations très pratiques comme le temps d’entraînement et la rapidité avec laquelle un modèle peut signaler une connexion en direct. Améliorer une mesure peut en détériorer une autre ; par exemple, grappiller un peu de précision peut rendre le modèle trop lent pour une utilisation en temps réel. De plus, les études publiées utilisent des jeux de données différents, des mixes d’attaques différents et des pipelines de prétraitement différents, rendant les comparaisons côte à côte difficiles.
Une fiche d’évaluation qui pèse plusieurs besoins à la fois
Pour traiter ce problème, l’article propose une « fiche d’évaluation » structurée basée sur une méthode de décision appelée TOPSIS. Plutôt que de se focaliser sur un seul chiffre, TOPSIS considère chaque algorithme comme une alternative et chaque mesure de performance comme un critère. Certains critères sont des « bénéfices » (plus c’est élevé, mieux c’est, comme le rappel), tandis que d’autres sont des « coûts » (plus c’est bas, mieux c’est, comme le temps de calcul). Les auteurs regroupent ces critères en trois grandes préoccupations : le comportement du modèle sur les données d’entraînement (biais du modèle), la qualité de sa prédiction sur des données nouvelles (biais de prédiction) et son coût en temps. Ils attribuent ensuite différents schémas de pondération pour refléter diverses préférences d’évaluateur — par exemple, quelqu’un qui privilégie la détection des attaques, quelqu’un qui privilégie la rapidité, ou quelqu’un qui recherche un équilibre. En utilisant trois jeux de données bien connus (KDD, NSL‑KDD et CICIDS2017), ils construisent un grand tableau de résultats, normalisent les valeurs pour les rendre comparables, appliquent les pondérations choisies et calculent la proximité de chaque algorithme par rapport à un détecteur « idéal » meilleur et à un détecteur « idéal » pire.
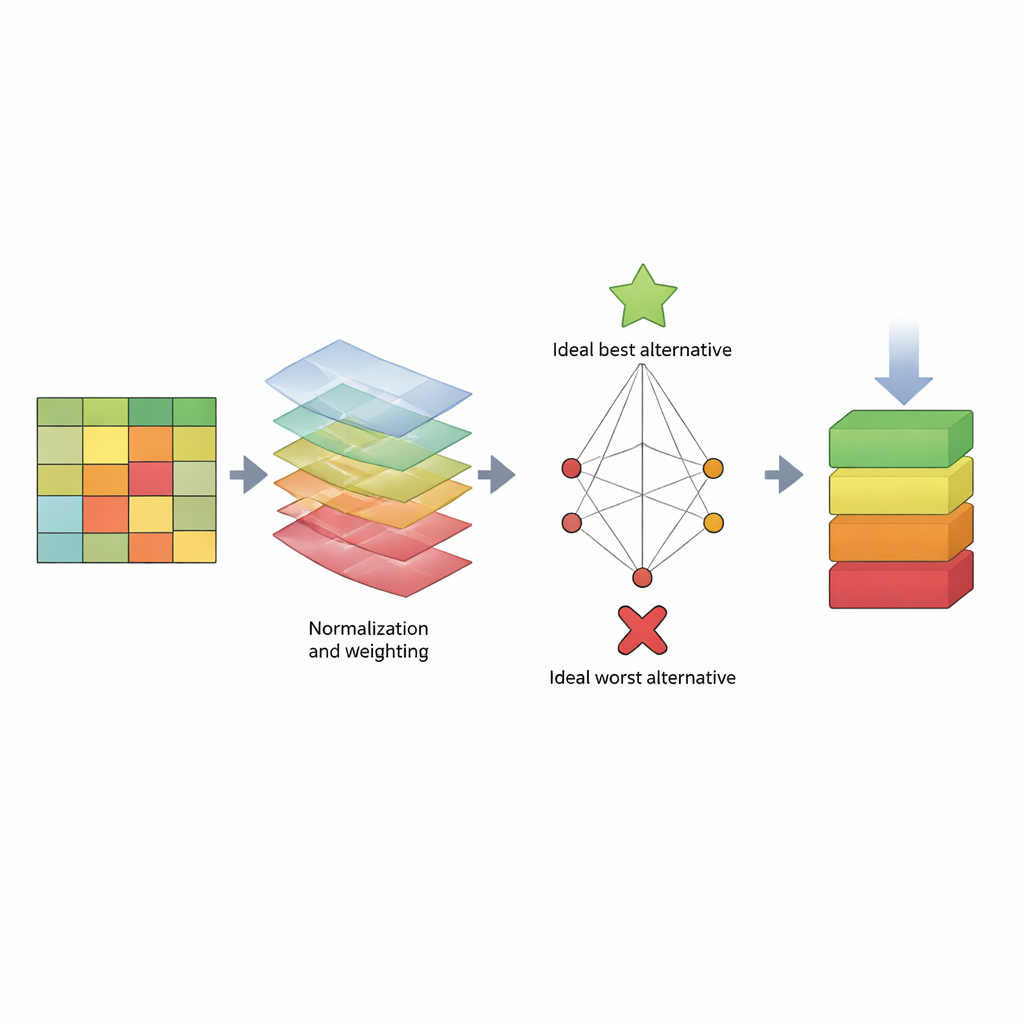
Ce que les classements révèlent sur les méthodes populaires
Dans de nombreux styles de pondération et pour les trois jeux de données, un schéma clair émerge. Les méthodes basées sur les arbres — en particulier Random Tree, les arbres de décision C4.5 et Random Forest — se retrouvent à plusieurs reprises en tête ou près du sommet des classements. Elles combinent de bons scores de détection avec des temps d’entraînement et de test raisonnables, et elles restent compétitives même lorsque les préférences des évaluateurs changent. En revanche, l’approche Naïve Bayes se classe systématiquement parmi les derniers, surtout sur les jeux de données plus difficiles NSL‑KDD et CICIDS2017. Son hypothèse simple d’indépendance des caractéristiques ne tient pas pour le trafic réseau complexe, ce qui conduit à une mauvaise gestion des schémas d’attaque subtils et de haute dimension. L’étude montre aussi que si la modification de l’importance des critères peut réorganiser le centre du classement, les meilleurs et les pires performeurs restent globalement stables.
Ce que cela signifie pour la sécurisation des réseaux
Pour les non‑spécialistes, la conclusion est qu’il n’existe pas de détecteur d’intrusion « magique » unique, mais que l’on peut comparer les options de manière rigoureuse et transparente. En traitant le choix du modèle comme une décision multicritère — plutôt que comme une simple compétition de précision brute — les auteurs montrent que certaines familles d’algorithmes, notamment celles basées sur les arbres, constituent des choix fiables dans de nombreuses conditions, tandis que d’autres sont plus risquées. Leur cadre basé sur TOPSIS agit comme un système d’évaluation réutilisable : à mesure que de nouveaux jeux de données et algorithmes apparaissent, ils peuvent être intégrés au même processus pour révéler quels outils offrent le meilleur compromis entre détection rapide des attaques, limitation des fausses alertes et faisabilité computationnelle.
Citation: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Mots-clés: détection d’intrusion, sécurité apprentissage automatique, attaques réseau, évaluation d’algorithme, prise de décision multicritère