Clear Sky Science · pl
Przegląd nadzorowanego wykrywania włamań z uczeniem maszynowym i ocena wielokryterialna
Dlaczego ochrona cyfrowych drzwi ma znaczenie
Za każdym razem, gdy przeglądamy sieć, wysyłamy wiadomość lub oglądamy film, niewidoczne systemy zabezpieczeń pracują w tle, żeby trzymać hakerów z daleka. Systemy wykrywania włamań przeszukują oceany ruchu sieciowego, aby wychwycić sygnały ataków. Istnieje jednak wiele sposobów budowy takich detektorów, z różnymi kompromisami w zakresie szybkości, dokładności i niezawodności. W artykule postawiono praktyczne pytanie: spośród tych opcji, które metody wykrywania włamań są rzeczywiście najlepsze i jak można je porównywać w uczciwy sposób?
Jak komputery uczą się rozpoznawać intruzów
Współczesne wykrywanie włamań często opiera się na nadzorowanym uczeniu maszynowym, gdzie algorytmy są trenowane na przeszłych przykładach połączeń „normalnych” i „atakujących”. Po wytrenowaniu modele próbują oznaczać nowy ruch jako bezpieczny lub podejrzany. Artykuł objaśnia typowe rodziny algorytmów używanych do tego zadania, takie jak k‑najbliższych sąsiadów, drzewa decyzyjne, lasy losowe, maszyny wektorów nośnych, sieci neuronowe i Naiwny Bayes. Każdy z nich ma swoje mocne i słabe strony: jedne radzą sobie dobrze z ogromną liczbą cech, inne sprawdzają się przy chaotycznych lub niezrównoważonych danych, a niektóre są szybkie, lecz mniej dokładne. Systemy w praktyce silnie zależą też od kroków wspomagających, takich jak czyszczenie danych, kodowanie pól tekstowych na liczby, normalizacja skal i wybór najbardziej informatywnych cech.
Dlaczego porównywanie detektorów jest trudniejsze, niż się wydaje
Pozornie wybór „najlepszego” detektora włamań mógłby wydawać się tak prosty jak wybranie tego z najwyższą dokładnością. Autorzy pokazują, dlaczego to mylące. Zbiory danych dotyczące włamań są często silnie niezrównoważone, z wielokrotnie większą liczbą ruchu normalnego niż ataków, więc dokładność może ukrywać poważne luki. Istnieje wiele innych miar — takich jak precyzja, recall (czułość), wskaźnik fałszywych alarmów, miara F i inne — oraz bardzo praktyczne kwestie, jak czas trenowania i jak szybko model może oznaczyć połączenie na żywo. Poprawa jednej miary może pogorszyć inną; na przykład uzyskanie nieco większej dokładności może sprawić, że model stanie się zbyt wolny do użycia w czasie rzeczywistym. Do tego badania w literaturze korzystają z różnych zbiorów danych, różnych proporcji ataków i różnych pipeline’ów przetwarzania wstępnego, co utrudnia porównania bezpośrednie.
Karta wyników uwzględniająca wiele potrzeb naraz
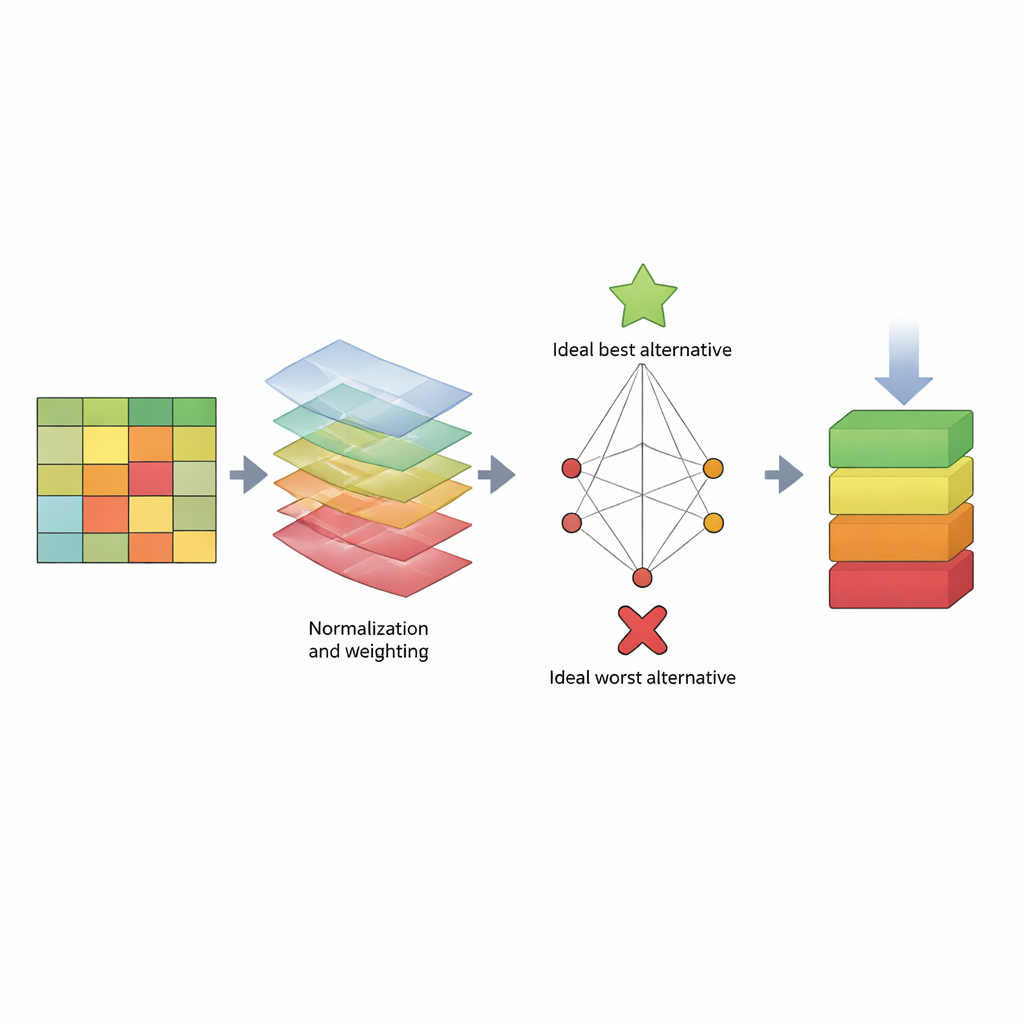
Aby sprostać temu wyzwaniu, artykuł proponuje uporządkowaną „kartę wyników” opartą na metodzie podejmowania decyzji zwanej TOPSIS. Zamiast skupiać się na jednej liczbie, TOPSIS traktuje każdy algorytm jako alternatywę, a każdą miarę wydajności jako kryterium. Niektóre kryteria to „korzyści” (im wyżej, tym lepiej, jak recall), inne to „koszty” (im niżej, tym lepiej, jak czas obliczeń). Autorzy grupują je w trzy szerokie obszary: jak model zachowuje się na danych treningowych (błąd modelu), jak dobrze przewiduje nowe dane (błąd predykcji) oraz ile czasu zużywa. Następnie przypisują różne wzorce wag, aby odzwierciedlić preferencje oceniających — na przykład ktoś, komu najbardziej zależy na wykrywaniu ataków, ktoś dbający o szybkość lub ktoś szukający kompromisu. Korzystając z trzech dobrze znanych zbiorów danych (KDD, NSL‑KDD i CICIDS2017), tworzą dużą tabelę wyników, normalizują liczby, by były porównywalne, stosują wybrane wagi i obliczają, jak blisko każdy algorytm znajduje się idealnego „najlepszego” i idealnego „najgorszego” detektora.
Co rankingi mówią o popularnych metodach
We wszystkich stylach ważenia i we wszystkich trzech zbiorach danych wyłania się wyraźny wzorzec. Metody oparte na drzewach — szczególnie Random Tree, drzewa decyzyjne C4.5 i Random Forest — wielokrotnie zajmują miejsca na szczycie rankingu lub blisko niego. Łączą silne wyniki wykrywania z rozsądnymi czasami trenowania i testowania oraz pozostają konkurencyjne nawet przy zmianie preferencji oceniającego. Natomiast podejście Naiwnego Bayesa konsekwentnie plasuje się w dolnej części rankingu, szczególnie na trudniejszych zbiorach NSL‑KDD i CICIDS2017. Jego proste założenie o niezależnym zachowaniu cech nie sprawdza się w złożonym ruchu sieciowym, co prowadzi do słabego radzenia sobie z subtelnymi, wysokowymiarowymi wzorcami ataków. Badanie pokazuje też, że choć zmiana wagi różnych kryteriów może przetasować środkową część zestawienia, najlepsi i najsłabsi wykonawcy pozostają w dużej mierze stabilni.
Co to oznacza dla zabezpieczania sieci
Dla niezajmujących się tematem specjalistów główne przesłanie jest takie, że nie istnieje pojedynczy „magiczny” detektor włamań, ale możemy porównywać opcje w zdyscyplinowany i przejrzysty sposób. Traktując wybór modelu jako decyzję wielokryterialną — zamiast konkursu surowej dokładności — autorzy pokazują, że pewne rodziny algorytmów, zwłaszcza oparte na drzewach, są solidnymi wyborami w wielu warunkach, podczas gdy inne mogą być ryzykowne. Ich ramy oparte na TOPSIS działają jak wielokrotnego użytku system oceny: gdy pojawią się nowe zbiory danych i algorytmy, można je podłączyć do tego samego procesu, aby ujawnić, które narzędzia oferują najlepszy kompromis między szybkim wykrywaniem ataków, ograniczaniem fałszywych alarmów i praktycznością obliczeniową.
Cytowanie: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Słowa kluczowe: wykrywanie włamań, bezpieczeństwo uczenia maszynowego, ataki sieciowe, ocena algorytmów, wielokryterialne podejmowanie decyzji