Clear Sky Science · nl
Beoordeling van detectie van indringers met toezicht en multicriteria-evaluatie
Waarom het bewaken van digitale deuren ertoe doet
Elke keer dat we op internet surfen, een bericht sturen of een film streamen, werken onzichtbare beveiligingssystemen achter de schermen om hackers buiten te houden. Deze inbraakdetectiesystemen ziften door zeeën van netwerkverkeer om tekenen van aanvallen te ontdekken. Er zijn echter veel manieren om zulke detectors te bouwen, en elk heeft afwegingen op het gebied van snelheid, nauwkeurigheid en betrouwbaarheid. Dit artikel stelt een praktische vraag: gezien al deze opties, welke inbraakdetectiemethoden zijn in de praktijk echt het beste, en hoe kunnen we ze eerlijk vergelijken?
Hoe computers leren indringers te herkennen
Moderne inbraakdetectie berust vaak op supervised machine learning, waarbij algoritmen worden getraind op eerdere voorbeelden van “normale” en “aanval”-verbindingen. Nadat ze zijn getraind, proberen deze modellen nieuw verkeer te labelen als veilig of verdacht. Het artikel legt de gebruikelijke families algoritmen uit die voor deze taak worden gebruikt, zoals k‑nearest neighbors, beslissingsbomen, random forests, support vector machines, neurale netwerken en Naïve Bayes. Elke familie heeft sterke en zwakke punten: sommige gaan goed om met enorme aantallen kenmerken, andere presteren beter bij rommelige of ongebalanceerde gegevens, en weer andere zijn snel maar minder nauwkeurig. Reële systemen zijn ook sterk afhankelijk van ondersteunende stappen zoals het opschonen van data, het coderen van tekstvelden als nummers, het normaliseren van schalen en het selecteren van de meest informatieve kenmerken.
Waarom het vergelijken van detectors lastiger is dan het lijkt
Op het eerste gezicht lijkt het kiezen van de “beste” inbraakdetector misschien eenvoudig: kies degene met de hoogste nauwkeurigheid. De auteurs laten zien waarom dit misleidend is. Inbraakdatasets zijn vaak sterk ongebalanceerd, met veel meer normaal verkeer dan aanvallen, zodat nauwkeurigheid ernstige blinde vlekken kan verbergen. Er bestaan veel andere maatstaven—zoals precisie, recall, valse-alarmfrequentie, F‑maat en meer—naast zeer praktische overwegingen zoals trainingstijd en hoe snel een model een live-verbinding kan signaleren. Het verbeteren van de ene maat kan een andere verslechteren; bijvoorbeeld het winnen van iets extra nauwkeurigheid kan het model te traag maken voor realtime gebruik. Daarbovenop gebruiken studies in de literatuur verschillende datasets, verschillende aanvalsmixen en verschillende preprocessing-pijplijnen, waardoor directe vergelijkingen lastig worden.
Een scorekaart die veel behoeften tegelijk weegt
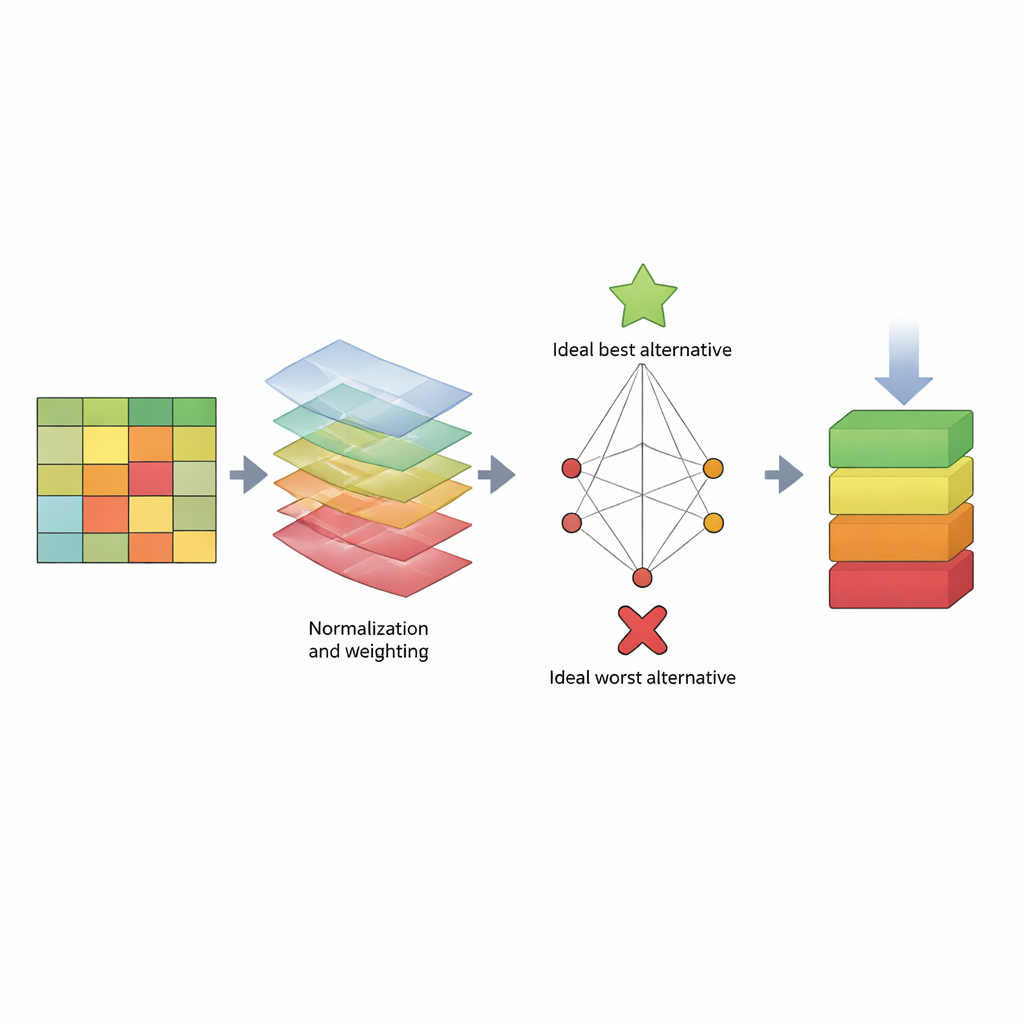
Om dit aan te pakken, stelt het artikel een gestructureerde “scorekaart” voor gebaseerd op een beslissingsmethode genaamd TOPSIS. In plaats van te focussen op één enkele waarde behandelt TOPSIS elk algoritme als een alternatief en elke prestatiemaat als een criterium. Sommige criteria zijn “benefits” (hoger is beter, zoals recall), terwijl andere “costs” zijn (lager is beter, zoals rekentijd). De auteurs groeperen deze in drie brede zorgen: hoe het model zich gedraagt op trainingsdata (modelbias), hoe goed het nieuwe data voorspelt (predictiebias) en hoeveel tijd het verbruikt. Vervolgens wijzen ze verschillende gewichtspatronen toe om uiteenlopende voorkeuren van beoordelaars te weerspiegelen—bijvoorbeeld iemand die vooral geeft om het detecteren van aanvallen, iemand die snelheid belangrijk vindt, of iemand die een evenwicht zoekt. Met behulp van drie bekende datasets (KDD, NSL‑KDD en CICIDS2017) bouwen ze een grote resultaatentabel, normaliseren de cijfers zodat ze vergelijkbaar zijn, passen de gekozen gewichten toe en berekenen hoe dicht elk algoritme bij een ideale “beste” en een ideale “slechtste” detector komt.
Wat de ranglijsten onthullen over populaire methoden
Over veel gewichtsinstellingen en alle drie datasets heen verschijnt een duidelijk patroon. Boomgebaseerde methoden—met name Random Tree, C4.5 beslissingsbomen en Random Forest—bevinden zich herhaaldelijk aan of nabij de top van de ranglijsten. Ze combineren sterke detectiescores met redelijke trainings- en testtijden en blijven competitief zelfs wanneer de voorkeuren van beoordelaars verschuiven. Daarentegen staat de Naïve Bayes-benadering consequent laag in de ranglijst, vooral op de uitdagendere NSL‑KDD- en CICIDS2017-datasets. De simpele aanname dat kenmerken onafhankelijk gedragen is niet geldig voor complex netwerkverkeer, wat leidt tot slechte omgang met subtiele, hoogdimensionale aanvalspatronen. De studie laat ook zien dat het veranderen van het belang van verschillende criteria de middenmoot kan herschikken, maar dat de beste en slechtste presteerders grotendeels stabiel blijven.
Wat dit betekent voor het beveiligen van netwerken
Voor niet‑specialisten is de kernboodschap dat er geen enkel “magisch” inbraakdetectiesysteem bestaat, maar dat we opties op een gedisciplineerde, transparante manier kunnen vergelijken. Door modelkeuze te behandelen als een multicriteria-beslissing—in plaats van een strijd om ruwe nauwkeurigheid—tonen de auteurs aan dat bepaalde algoritmefamilies, vooral boomgebaseerde, betrouwbaar sterke keuzes zijn onder veel omstandigheden, terwijl andere risicovol zijn. Hun TOPSIS-gebaseerde raamwerk fungeert als een herbruikbaar beoordelingssysteem: naarmate nieuwe datasets en algoritmen verschijnen, kunnen ze in hetzelfde proces worden ingeplugd om te onthullen welke tools het beste evenwicht bieden tussen het snel opsporen van aanvallen, het beperken van valse alarmen en het praktisch blijven qua rekenkosten.
Bronvermelding: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Trefwoorden: inbraakdetectie, machine learning beveiliging, netwerk aanvallen, algoritme-evaluatie, multi-criteria beslissingsvorming