Clear Sky Science · it
Revisione dei sistemi di rilevamento delle intrusioni con apprendimento supervisionato e valutazione multicriterio
Perché proteggere le porte digitali è importante
Ogni volta che navighiamo sul web, inviamo un messaggio o guardiamo un film in streaming, sistemi di sicurezza invisibili lavorano dietro le quinte per tenere fuori gli hacker. Questi sistemi di rilevamento delle intrusioni setacciano oceani di traffico di rete per individuare segnali di attacco. Ma esistono molti modi per costruire tali rilevatori, e ciascuno comporta compromessi in termini di velocità, accuratezza e affidabilità. Questo articolo pone una domanda pratica: date tutte queste opzioni, quali metodi di rilevamento delle intrusioni sono effettivamente i migliori e come possiamo confrontarli in modo equo?
Come i computer imparano a individuare gli intrusi
Il rilevamento delle intrusioni moderno si basa spesso sull’apprendimento automatico supervisionato, in cui gli algoritmi vengono addestrati su esempi passati di connessioni “normali” e “di attacco”. Una volta addestrati, questi modelli cercano di etichettare il nuovo traffico come sicuro o sospetto. L’articolo spiega le famiglie di algoritmi più comuni per questo compito, come k‑nearest neighbors, alberi decisionali, random forest, support vector machines, reti neurali e Naïve Bayes. Ognuno ha punti di forza e limiti: alcuni gestiscono molto bene un gran numero di feature, altri brillano con dati sporchi o sbilanciati, e alcuni sono veloci ma meno accurati. I sistemi reali dipendono inoltre da passaggi di supporto come la pulizia dei dati, la codifica di campi testuali in numeri, la normalizzazione delle scale e la selezione delle feature più informative.
Perché confrontare i rilevatori è più difficile di quanto sembri
A prima vista, scegliere il rilevatore di intrusioni “migliore” potrebbe sembrare semplice come prendere quello con l’accuratezza più alta. Gli autori mostrano perché questo è fuorviante. I dataset per intrusioni sono spesso fortemente sbilanciati, con molto più traffico normale che attacchi, perciò l’accuratezza può nascondere gravi punti ciechi. Esistono molte altre misure—come precisione, richiamo (recall), tasso di falsi allarmi, F‑measure e altre—insieme a preoccupazioni molto pratiche come il tempo di addestramento e la rapidità con cui un modello può segnalare una connessione live. Migliorare una misura può peggiorarne un’altra; per esempio, ottenere un po’ più di accuratezza potrebbe rendere il modello troppo lento per l’uso in tempo reale. Inoltre, gli studi in letteratura usano dataset diversi, mix di attacchi differenti e pipeline di preprocessing diverse, rendendo difficili i confronti testa a testa.
Un tabellone di valutazione che pesa molte esigenze insieme
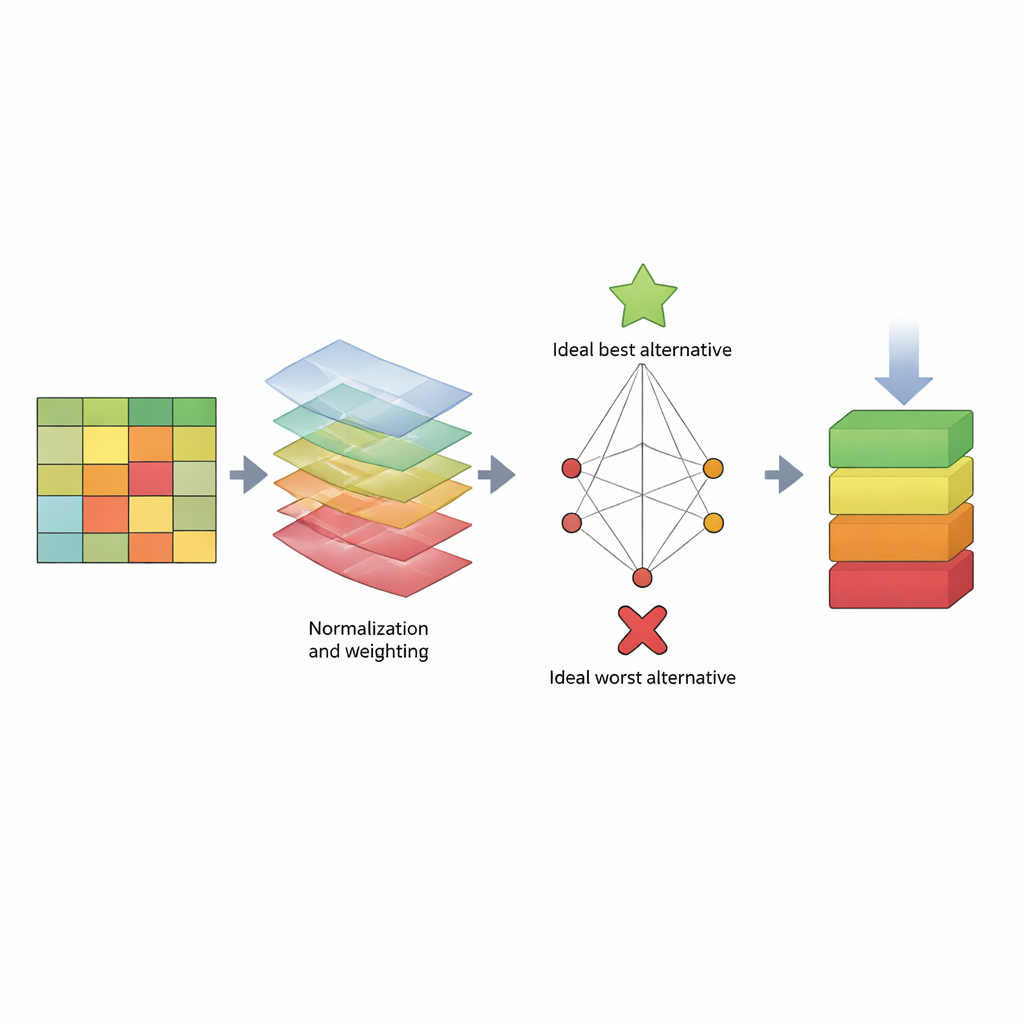
Per affrontare il problema, l’articolo propone un “tabellone di valutazione” strutturato basato su un metodo decisionale chiamato TOPSIS. Invece di concentrarsi su un singolo numero, TOPSIS tratta ogni algoritmo come un’alternativa e ogni misura di performance come un criterio. Alcuni criteri sono “benefici” (più è alto meglio è, come il recall), mentre altri sono “costi” (più è basso meglio è, come il tempo di calcolo). Gli autori raggruppano questi criteri in tre ampie preoccupazioni: come si comporta il modello sui dati di addestramento (bias del modello), quanto bene predice nuovi dati (bias di predizione) e quanto tempo consuma. Assegnano poi diversi schemi di pesi per riflettere varie preferenze degli valutatori—per esempio, chi dà priorità alla rilevazione degli attacchi, chi punta alla velocità o chi cerca un equilibrio. Usando tre dataset noti (KDD, NSL‑KDD e CICIDS2017), costruiscono una ampia tabella di risultati, normalizzano i numeri in modo che siano confrontabili, applicano i pesi scelti e calcolano quanto ciascun algoritmo si avvicina a un ideale “migliore” e a un ideale “peggiore” rilevatore.
Cosa rivelano le classifiche sui metodi più diffusi
Attraverso molti stili di pesatura e tutti e tre i dataset, emerge un pattern chiaro. I metodi basati su alberi—in particolare Random Tree, gli alberi decisionali C4.5 e Random Forest—si collocano ripetutamente ai vertici o vicini alla cima delle classifiche. Combinano solide prestazioni di rilevamento con tempi di addestramento e test ragionevoli, e restano competitivi anche quando le preferenze degli valutatori cambiano. Al contrario, l’approccio Naïve Bayes si classifica costantemente verso il fondo, soprattutto nei più impegnativi dataset NSL‑KDD e CICIDS2017. La sua semplice assunzione di indipendenza fra le feature non regge per il traffico di rete complesso, portando a una scarsa gestione di pattern di attacco sottili e ad alta dimensionalità. Lo studio mostra inoltre che, mentre cambiare l’importanza dei diversi criteri può rimescolare la parte centrale della classifica, i migliori e i peggiori rimangono in gran parte stabili.
Cosa significa questo per la sicurezza delle reti
Per i non specialisti, il messaggio principale è che non esiste un singolo rilevatore di intrusioni “magico”, ma possiamo confrontare le opzioni in modo disciplinato e trasparente. Trattando la scelta del modello come una decisione multicriterio—piuttosto che come una gara basata sulla sola accuratezza—gli autori dimostrano che certe famiglie di algoritmi, in particolare quelle basate su alberi, sono scelte affidabili in molte condizioni, mentre altre sono rischiose. Il loro framework basato su TOPSIS funziona come un sistema di valutazione riutilizzabile: man mano che appaiono nuovi dataset e algoritmi, possono essere inseriti nello stesso processo per rivelare quali strumenti offrono il miglior equilibrio tra rilevare rapidamente gli attacchi, limitare i falsi allarmi e mantenere la praticità computazionale.
Citazione: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Parole chiave: rilevamento delle intrusioni, sicurezza e machine learning, attacchi di rete, valutazione degli algoritmi, decisione multicriterio