Clear Sky Science · de
Überblick über überwachtes maschinelles Lernen zur Eindringungserkennung und Multikriterienbewertung
Warum das Bewachen digitaler Türen wichtig ist
Jedes Mal, wenn wir im Web surfen, eine Nachricht senden oder einen Film streamen, arbeiten unsichtbare Sicherheitssysteme im Hintergrund, um Hacker fernzuhalten. Diese Eindringungserkennungssysteme durchforsten Ozeane von Netzwerkverkehr, um Hinweise auf Angriffe zu entdecken. Es gibt jedoch viele Möglichkeiten, solche Detektoren zu konstruieren, und jede bringt Kompromisse bei Geschwindigkeit, Genauigkeit und Zuverlässigkeit mit sich. Dieses Papier stellt eine praktische Frage: Angesichts all dieser Optionen, welche Methoden der Eindringungserkennung sind tatsächlich die besten, und wie kann man sie fair vergleichen?
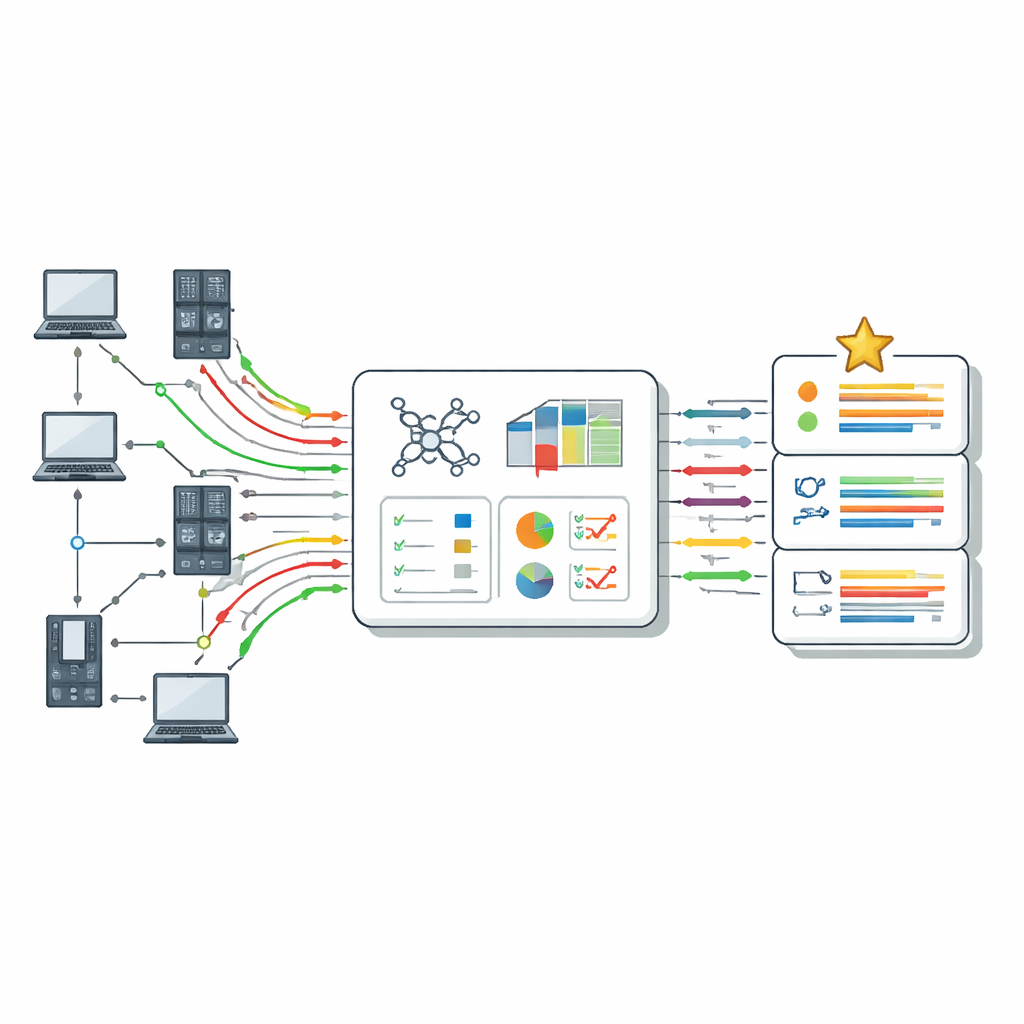
Wie Computer lernen, Eindringlinge zu erkennen
Moderne Eindringungserkennung beruht oft auf überwachtem maschinellen Lernen, bei dem Algorithmen anhand vergangener Beispiele für „normalen“ und „angreifenden“ Verkehr trainiert werden. Nach dem Training versuchen diese Modelle, neuen Verkehr als sicher oder verdächtig zu kennzeichnen. Das Papier erklärt die gängigen Algorithmusfamilien für diese Aufgabe, wie k‑Nearest Neighbors, Entscheidungsbäume, Random Forests, Support Vector Machines, neuronale Netze und Naïve Bayes. Jede hat Stärken und Schwächen: Manche kommen gut mit sehr vielen Merkmalen zurecht, andere glänzen bei unordentlichen oder unausgewogenen Daten, und einige sind schnell, aber weniger genau. Reale Systeme hängen außerdem stark von unterstützenden Schritten ab, wie der Bereinigung von Daten, der Umwandlung von Textfeldern in Zahlen, der Normierung von Skalen und der Auswahl der aussagekräftigsten Merkmale.
Warum der Vergleich von Detektoren schwieriger ist, als er scheint
Auf den ersten Blick scheint die Wahl des „besten“ Eindringungsdetektors so einfach wie die Entscheidung für das Modell mit der höchsten Genauigkeit. Die Autoren zeigen, warum das irreführend ist. Eindringungsdatensätze sind oft stark unausgeglichen, mit weit mehr normalem Verkehr als Angriffen, sodass die Genauigkeit ernsthafte Blindenflecken verbergen kann. Es gibt viele weitere Maße—wie Präzision, Trefferquote (Recall), Fehlalarmrate, F‑Maß und mehr—neben sehr praktischen Aspekten wie Trainingszeit und wie schnell ein Modell eine Live‑Verbindung markieren kann. Die Verbesserung einer Kennzahl kann eine andere verschlechtern; zum Beispiel kann ein kleiner Gewinn an Genauigkeit das Modell für den Echtzeiteinsatz zu langsam machen. Darüber hinaus verwenden Studien in der Fachliteratur unterschiedliche Datensätze, verschiedene Angriffsmischungen und unterschiedliche Vorverarbeitungs‑Pipelines, was direkte Vergleiche erschwert.
Eine Ergebnisliste, die viele Bedürfnisse gleichzeitig gewichtet
Um dem zu begegnen, schlägt das Papier eine strukturierte „Scorecard“ vor, die auf einer Entscheidungsmethode namens TOPSIS basiert. Anstatt sich auf eine einzige Zahl zu konzentrieren, behandelt TOPSIS jeden Algorithmus als eine Alternative und jede Leistungskennzahl als ein Kriterium. Manche Kriterien sind „Nutzen“ (höher ist besser, etwa Recall), andere sind „Kosten“ (niedriger ist besser, etwa Rechenzeit). Die Autoren bündeln diese in drei breite Anliegen: wie das Modell sich auf Trainingsdaten verhält (Modellbias), wie gut es neue Daten vorhersagt (Vorhersagebias) und wie viel Zeit es verbraucht. Dann weisen sie unterschiedliche Gewichtsmuster zu, um verschiedene Präferenzen von Bewertern widerzuspiegeln—zum Beispiel jemanden, dem es vor allem darauf ankommt, Angriffe zu erkennen, jemanden, dem Geschwindigkeit wichtig ist, oder jemanden, der ein Gleichgewicht sucht. Anhand von drei bekannten Datensätzen (KDD, NSL‑KDD und CICIDS2017) erstellen sie eine große Ergebnistabelle, normieren die Zahlen, damit sie vergleichbar sind, wenden die gewählten Gewichte an und berechnen, wie nah jeder Algorithmus an einem idealen „besten“ bzw. einem idealen „schlechtesten“ Detektor liegt.
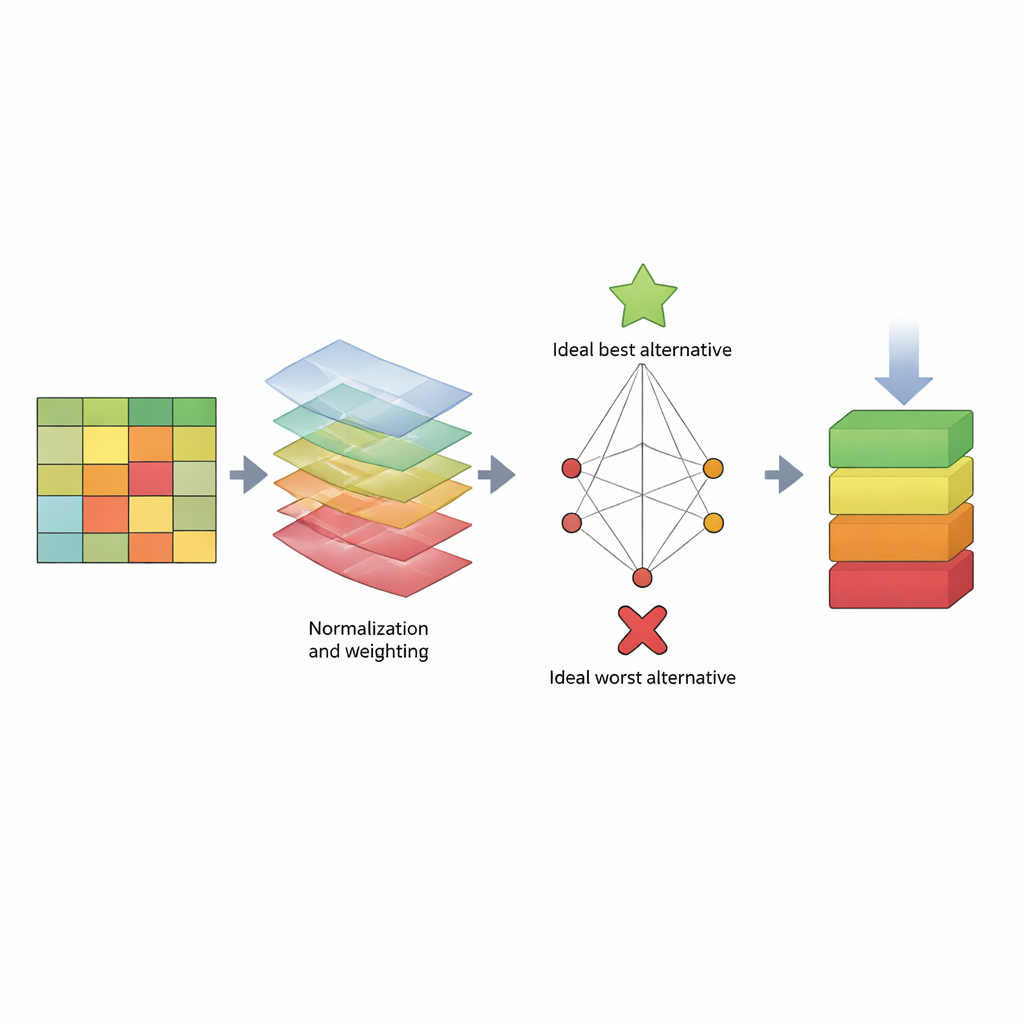
Was die Rangfolgen über gängige Methoden verraten
Über viele Gewichtungsvarianten und alle drei Datensätze hinweg zeigt sich ein klares Muster. Baum‑basierte Methoden—insbesondere Random Tree, C4.5‑Entscheidungsbäume und Random Forest—finden sich wiederholt an der Spitze oder in deren Nähe. Sie kombinieren starke Erkennungswerte mit angemessenen Trainings‑ und Testzeiten und bleiben wettbewerbsfähig, selbst wenn sich die Präferenzen der Bewerter verschieben. Im Gegensatz dazu landet der Naïve‑Bayes‑Ansatz konsequent eher im unteren Bereich, besonders bei den anspruchsvolleren NSL‑KDD‑ und CICIDS2017‑Datensätzen. Seine einfache Annahme, dass Merkmale unabhängig voneinander sind, trifft bei komplexem Netzwerkverkehr nicht zu und führt zu schlechtem Umgang mit subtilen, hochdimensionalen Angriffsmustern. Die Studie zeigt außerdem, dass das Verändern der Bedeutung verschiedener Kriterien das Mittelfeld durcheinanderwirbeln kann, die besten und schlechtesten Performer aber weitgehend stabil bleiben.
Was das für die Netzwerksicherung bedeutet
Für Nicht‑Spezialisten lautet die Kernaussage, dass es keinen einzelnen „magischen“ Eindringungsdetektor gibt, aber man Optionen diszipliniert und transparent vergleichen kann. Indem die Modellauswahl als Multikriterienentscheidung behandelt wird—statt als Wettbewerb reiner Genauigkeit—zeigen die Autoren, dass bestimmte Algorithmusfamilien, vor allem baumbasierte, über viele Bedingungen hinweg verlässlich starke Optionen sind, während andere riskanter sind. Ihr TOPSIS‑basiertes Framework fungiert wie ein wiederverwendbares Bewertungssystem: Wenn neue Datensätze und Algorithmen erscheinen, können sie in denselben Prozess eingespeist werden, um aufzuzeigen, welche Werkzeuge das beste Gleichgewicht zwischen schneller Angriffserkennung, Begrenzung von Fehlalarmen und praktikabler Rechenbarkeit bieten.
Zitation: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Schlüsselwörter: Eindringungserkennung, Sicherheit im maschinellen Lernen, Netzwerkangriffe, Algorithmusbewertung, Multikriterien-Entscheidungsfindung