Clear Sky Science · en
Supervised machine learning intrusion detection review and multi-criteria evaluation
Why guarding digital doors matters
Every time we browse the web, send a message, or stream a movie, invisible security systems work behind the scenes to keep hackers out. These intrusion detection systems sift through oceans of network traffic to spot signs of attacks. But there are many ways to build such detectors, and each comes with trade‑offs in speed, accuracy, and reliability. This paper asks a practical question: given all these options, which intrusion detection methods are actually the best, and how can we compare them fairly?
How computers learn to spot intruders
Modern intrusion detection often relies on supervised machine learning, where algorithms are trained on past examples of “normal” and “attack” connections. Once trained, these models try to label new traffic as safe or suspicious. The paper explains common families of algorithms used for this job, such as k‑nearest neighbors, decision trees, random forests, support vector machines, neural networks, and Naïve Bayes. Each has strengths and weaknesses: some cope well with huge numbers of features, others shine with messy or imbalanced data, and some are fast but less accurate. Real‑world systems also depend heavily on supporting steps like cleaning data, encoding text fields as numbers, normalizing scales, and selecting the most informative features.
Why comparing detectors is harder than it looks
At first glance, picking the “best” intrusion detector might seem as simple as choosing the one with the highest accuracy. The authors show why this is misleading. Intrusion datasets are often highly imbalanced, with far more normal traffic than attacks, so accuracy can hide serious blind spots. Many other measures exist—such as precision, recall, false alarm rate, F‑measure, and more—alongside very practical concerns like training time and how quickly a model can flag a live connection. Improving one measure can worsen another; for example, squeezing out a bit more accuracy might make the model too slow for real‑time use. On top of that, studies in the literature use different datasets, different attack mixes, and different preprocessing pipelines, making side‑by‑side comparisons difficult.
A scorecard that weighs many needs at once
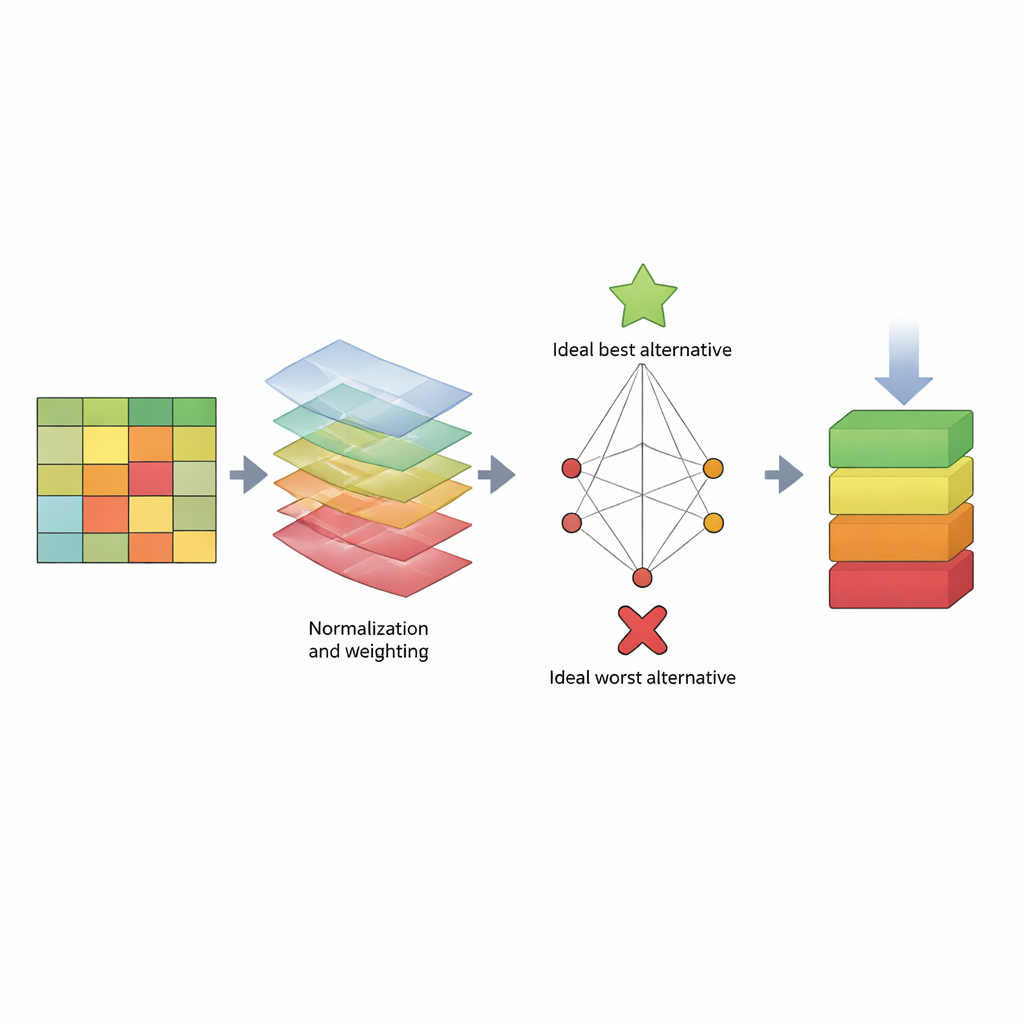
To tackle this, the paper proposes a structured “scorecard” based on a decision‑making method called TOPSIS. Instead of focusing on a single number, TOPSIS treats each algorithm as an alternative and each performance measure as a criterion. Some criteria are “benefits” (higher is better, like recall), while others are “costs” (lower is better, like computation time). The authors group these into three broad concerns: how the model behaves on training data (model bias), how well it predicts new data (prediction bias), and how much time it consumes. They then assign different weight patterns to reflect various evaluator preferences—for example, someone who cares most about catching attacks, someone who cares about speed, or someone seeking a balance. Using three well‑known datasets (KDD, NSL‑KDD, and CICIDS2017), they build a large results table, normalize the numbers so they are comparable, apply the chosen weights, and compute how close each algorithm comes to an ideal “best” and an ideal “worst” detector.
What the rankings reveal about popular methods
Across many weighting styles and all three datasets, a clear pattern emerges. Tree‑based methods—particularly Random Tree, C4.5 decision trees, and Random Forest—repeatedly land at or near the top of the rankings. They combine strong detection scores with reasonable training and testing times, and they remain competitive even when evaluator preferences shift. In contrast, the Naïve Bayes approach consistently ranks near the bottom, especially on the more challenging NSL‑KDD and CICIDS2017 datasets. Its simple assumption that features behave independently does not hold for complex network traffic, leading to poor handling of subtle, high‑dimensional attack patterns. The study also shows that while changing the importance of different criteria can reshuffle the middle of the pack, the best and worst performers remain largely stable.
What this means for securing networks
For non‑specialists, the take‑home message is that there is no single “magic” intrusion detector, but we can compare options in a disciplined, transparent way. By treating model choice as a multi‑criteria decision—rather than a contest of raw accuracy—the authors show that certain families of algorithms, especially tree‑based ones, are reliably strong choices across many conditions, while others are risky. Their TOPSIS‑based framework acts like a reusable rating system: as new datasets and algorithms appear, they can be plugged into the same process to reveal which tools offer the best balance of catching attacks quickly, limiting false alarms, and staying computationally practical.
Citation: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Keywords: intrusion detection, machine learning security, network attacks, algorithm evaluation, multi-criteria decision making