Clear Sky Science · ru
Обзор методов обнаружения вторжений с обучением с учителем и их многокритериальная оценка
Почему важно охранять цифровые двери
Каждый раз, когда мы просматриваем веб‑страницы, отправляем сообщение или смотрим фильм, невидимые системы безопасности работают за кулисами, чтобы не допустить хакеров. Системы обнаружения вторжений просеивают океаны сетевого трафика в поисках признаков атак. Но существуют разные подходы к построению таких детекторов, и каждый из них имеет компромиссы по скорости, точности и надежности. В этой статье поставлен практический вопрос: из всех доступных вариантов какие методы обнаружения вторжений действительно лучшие и как их справедливо сравнивать?
Как компьютеры учатся замечать злоумышленников
Современное обнаружение вторжений часто опирается на контролируемое (supervised) машинное обучение, где алгоритмы обучают на примерах «нормальных» и «атакующих» соединений. После обучения модели пытаются пометить новый трафик как безопасный или подозрительный. В статье объясняются распространённые семейства алгоритмов для этой задачи: k‑ближайших соседей, решающие деревья, случайный лес, опорные векторы, нейронные сети и наивный Байес. У каждого есть свои сильные и слабые стороны: одни хорошо работают с огромным числом признаков, другие эффективны при грязных или несбалансированных данных, а третьи быстры, но менее точны. В реальных системах большое значение имеют вспомогательные этапы — очистка данных, кодирование текстовых полей числами, нормализация масштабов и выбор наиболее информативных признаков.
Почему сравнивать детекторы сложнее, чем кажется
На первый взгляд выбор «лучшего» детектора может показаться простым: взять тот, у которого выше точность. Авторы показывают, почему это вводит в заблуждение. Наборы данных для обнаружения вторжений часто сильно несбалансированы: нормального трафика намного больше, чем атак, поэтому точность может скрывать серьёзные слепые зоны. Существуют и другие метрики — точность (precision), полнота (recall), частота ложных тревог, F‑мера и прочие — плюс практические соображения, например время обучения и скорость, с которой модель способна пометить живое соединение. Улучшение одной метрики может ухудшить другую: например, небольшое повышение точности может сделать модель слишком медленной для работы в реальном времени. К тому же в литературе исследования используют разные наборы данных, разные сочетания атак и разные этапы предобработки, что затрудняет сравнительные выводы.
Шкала оценок, учитывающая множество требований одновременно
Чтобы решить эту проблему, авторы предлагают структурированную «шкалу» на основе метода принятия решений TOPSIS. Вместо того чтобы опираться на одно число, TOPSIS рассматривает каждый алгоритм как альтернативу, а каждую меру производительности — как критерий. Некоторые критерии — это «выгоды» (чем больше, тем лучше, например полнота), другие — «затраты» (чем меньше, тем лучше, например время вычислений). Авторы группируют их в три широкие категории: поведение модели на обучающей выборке (смещение модели), насколько хорошо она предсказывает новые данные (смещение предсказания) и сколько времени она потребляет. Затем они задают разные схемы весов, отражающие предпочтения оценщиков — например, кто-то, кто больше всего ценит обнаружение атак, кто‑то ориентирован на скорость, или кто‑то ищет баланс. Используя три хорошо известных набора данных (KDD, NSL‑KDD и CICIDS2017), они формируют большую таблицу результатов, нормализуют показатели для сопоставимости, применяют выбранные веса и вычисляют, насколько близко каждый алгоритм к идеальному «лучшему» и идеальному «худшему» детектору.
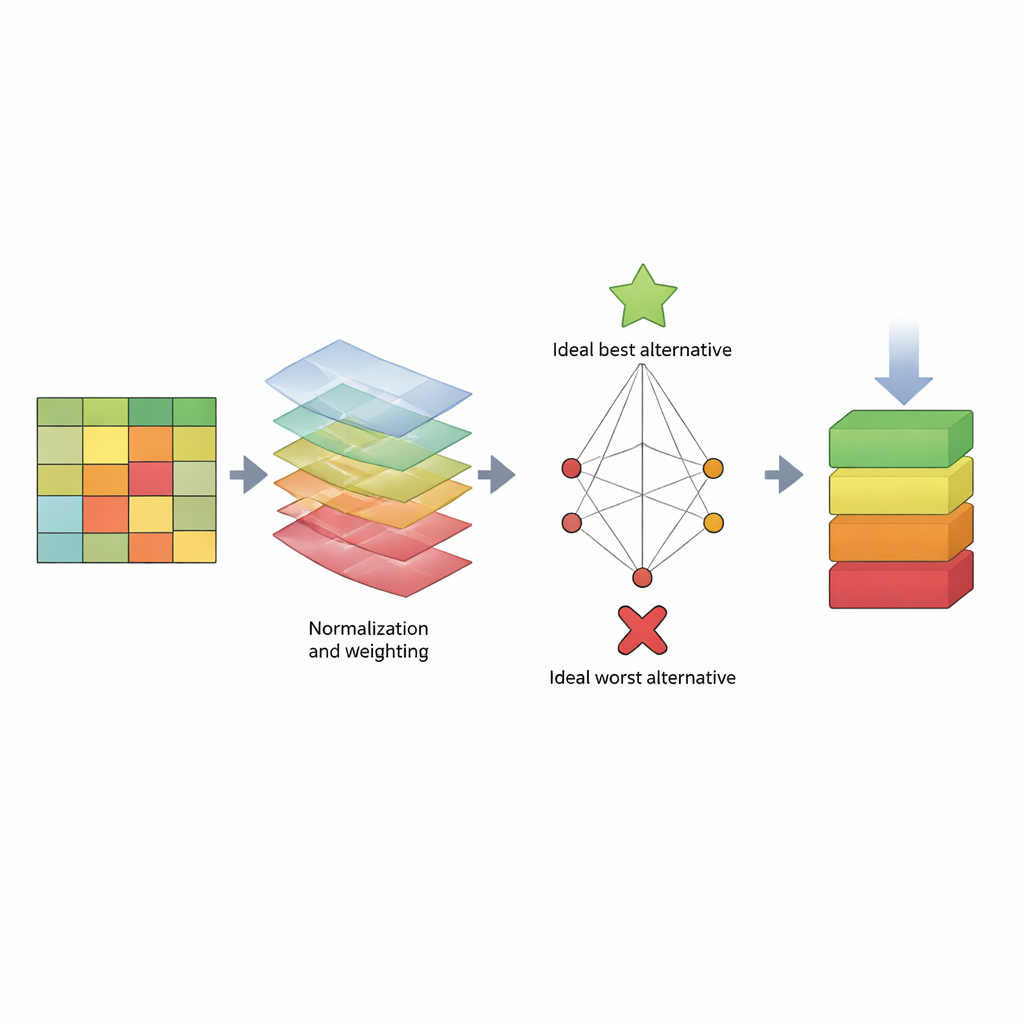
Что показывают рейтинги популярных методов
Во всех стилях взвешивания и для всех трёх наборов данных проявляется чёткая картина. Методы на основе деревьев — особенно Random Tree, решающие деревья C4.5 и Random Forest — неоднократно оказываются в верхней части рейтингов. Они сочетают сильные показатели обнаружения с приемлемым временем обучения и тестирования и сохраняют конкурентоспособность при смене предпочтений оценщика. Напротив, наивный Байес стабильно попадает ближе к низу, особенно на более сложных наборах NSL‑KDD и CICIDS2017. Его простое предположение о независимости признаков не выдерживает для сложного сетевого трафика, что приводит к плохой обработке тонких, высокоразмерных шаблонов атак. Исследование также показывает, что изменение важности разных критериев может перемешать среднюю часть рейтинга, но лидеры и аутсайдеры остаются в целом стабильными.
Что это означает для защиты сетей
Для неспециалистов вывод таков: не существует единственного «волшебного» детектора вторжений, но варианты можно сравнивать дисциплинированно и прозрачно. Рассматривая выбор модели как многокритериальное решение, а не как соревнование по чистой точности, авторы показывают, что определённые семейства алгоритмов, особенно методы на основе деревьев, являются надёжным выбором в широком спектре условий, тогда как другие представляют риск. Их подход на основе TOPSIS выступает как повторно применимая система рейтингов: по мере появления новых наборов данных и алгоритмов их можно подключать к той же процедуре, чтобы выяснить, какие инструменты предлагают наилучший баланс между быстрой детекцией атак, ограничением ложных срабатываний и практичностью с точки зрения вычислений.
Цитирование: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Ключевые слова: обнаружение вторжений, безопасность машинного обучения, сетевые атаки, оценка алгоритмов, многокритериальное принятие решений