Clear Sky Science · sv
Översikt över intrångsdetektion med övervakad maskininlärning och flerkriterieutvärdering
Varför det är viktigt att vakta de digitala dörrarna
Varje gång vi surfar på webben, skickar ett meddelande eller strömmar en film arbetar osynliga säkerhetssystem i bakgrunden för att hålla hackare ute. Dessa intrångsdetekteringssystem sållar genom enorma mängder nätverkstrafik för att hitta tecken på attacker. Men det finns många sätt att bygga sådana detektorer, och varje val innebär kompromisser i hastighet, noggrannhet och tillförlitlighet. Den här artikeln tar en praktisk fråga: med alla dessa alternativ, vilka intrångsdetektionsmetoder är faktiskt bäst, och hur kan vi jämföra dem rättvist?
Hur datorer lär sig känna igen inkräktare
Modern intrångsdetektion förlitar sig ofta på övervakad maskininlärning, där algoritmer tränas på tidigare exempel på ”normal” och ”attack”‑anslutningar. När modellerna är tränade försöker de märka ny trafik som säker eller misstänkt. Artikeln förklarar vanliga algoritmfamiljer som används för detta arbete, såsom k‑närmsta grannar, beslutsträd, Random Forest, supportvektormaskiner, neurala nätverk och Naïve Bayes. Var och en har styrkor och svagheter: vissa hanterar många attribut väl, andra glänser med röriga eller obalanserade data, och några är snabba men mindre precisa. Verkliga system beror också starkt på stödjande steg som att rensa data, koda textfält som siffror, normalisera skalor och välja de mest informativa funktionerna.
Varför det är svårare att jämföra detektorer än det ser ut
Vid första anblick kan valet av den ”bästa” intrångsdetektorn verka lika enkelt som att välja den med högst noggrannhet. Författarna visar varför det är missvisande. Intrångsdatamängder är ofta starkt obalanserade, med betydligt mer normal trafik än attacker, så noggrannhet kan dölja allvarliga blindfläckar. Många andra mått finns—som precision, återkallning (recall), falsk alarm‑frekvens, F‑mått med flera—tillsammans med mycket praktiska hänsyn som träningstid och hur snabbt en modell kan flagga en live‑anslutning. Att förbättra ett mått kan försämra ett annat; till exempel kan lite högre noggrannhet göra modellen för långsam för realtidsanvändning. Dessutom använder studier i litteraturen olika datamängder, olika attacker och olika förbehandlings‑pipelines, vilket gör sida‑vid‑sida‑jämförelser svåra.
En poängtavla som väger många behov samtidigt
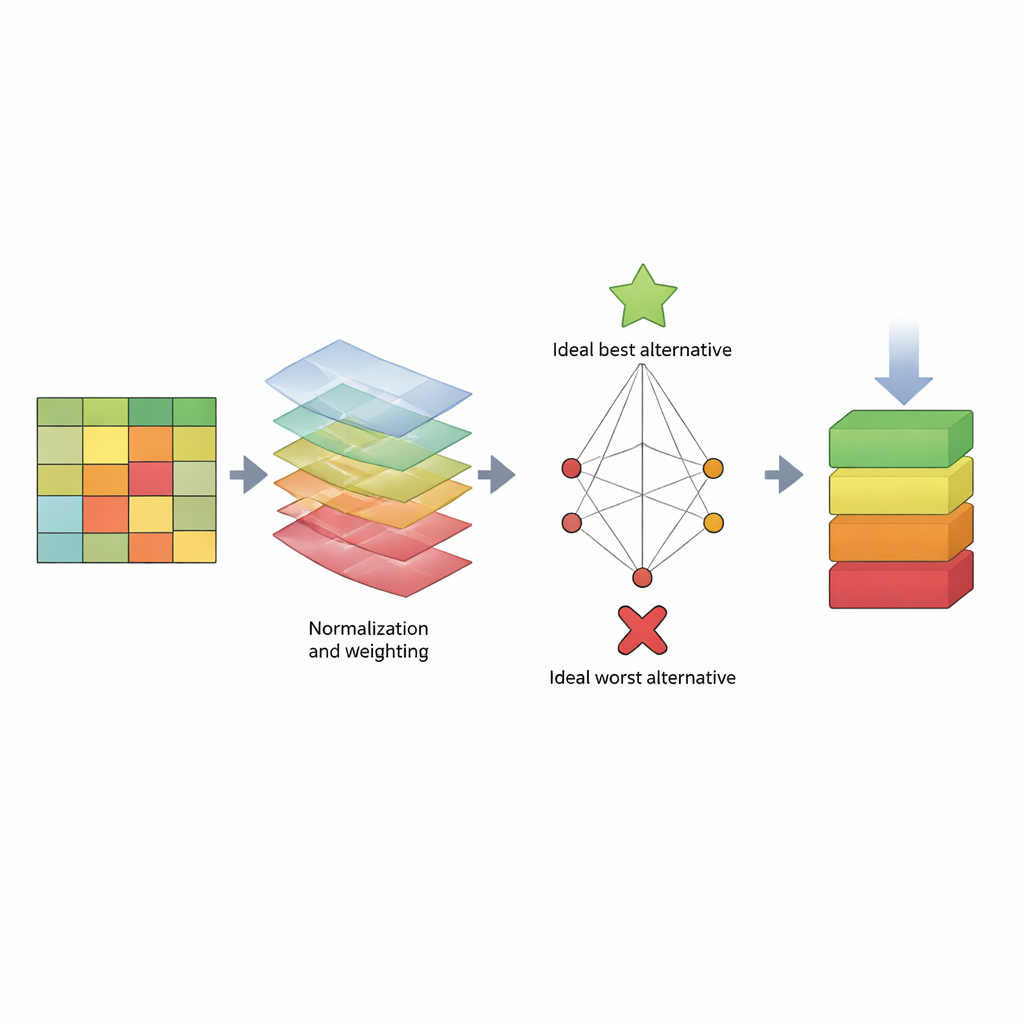
För att hantera detta föreslår artikeln en strukturerad ”poängtavla” baserad på en beslutsmetod kallad TOPSIS. Istället för att fokusera på ett enda tal behandlar TOPSIS varje algoritm som ett alternativ och varje prestandamått som ett kriterium. Vissa kriterier är ”fördelar” (högre är bättre, som recall), medan andra är ”kostnader” (lägre är bättre, som beräkningstid). Författarna grupperar dessa i tre breda hänsyn: hur modellen beter sig på träningsdata (modellbias), hur väl den förutsäger ny data (prediktionsbias) och hur mycket tid den förbrukar. De tilldelar sedan olika viktmönster för att spegla olika utvärderarpreferenser—till exempel någon som värderar att fånga attacker högst, någon som prioriterar hastighet, eller någon som söker balans. Genom att använda tre välkända datamängder (KDD, NSL‑KDD och CICIDS2017) bygger de en stor resultatstabell, normaliserar siffrorna så att de blir jämförbara, applicerar valda vikter och beräknar hur nära varje algoritm kommer ett idealiskt ”bäst” respektive ett idealiskt ”sämst” detektor.
Vad rankningarna avslöjar om populära metoder
Över många viktstilar och alla tre datamängder framträder ett tydligt mönster. Trädbaserade metoder—i synnerhet Random Tree, C4.5‑beslutsträd och Random Forest—hamnar upprepade gånger i toppen eller nära toppen av rankningarna. De kombinerar starka detektionsresultat med rimliga tränings‑ och testtider och förblir konkurrenskraftiga även när utvärderarpreferenser skiftar. I kontrast rankas Naïve Bayes konsekvent i botten, särskilt på de mer utmanande NSL‑KDD‑ och CICIDS2017‑mängderna. Dess enkla antagande att funktioner är oberoende håller inte för komplex nätverkstrafik, vilket leder till dålig hantering av subtila, högdimensionella attackmönster. Studien visar också att medan förändringar i kriteriernas vikt kan omfördela mitten av fältet, förblir de bästa och sämsta aktörerna i stort sett stabila.
Vad detta betyder för nätverkssäkerhet
För icke‑specialister är slutsatsen att det inte finns någon enskild ”magisk” intrångsdetektor, men vi kan jämföra alternativ på ett disciplinerad och transparent sätt. Genom att behandla modellval som ett flerkriteriebeslut—snarare än en tävling om rå noggrannhet—visar författarna att vissa algoritmfamiljer, särskilt trädbaserade, är tillförlitligt starka val i många situationer, medan andra är riskfyllda. Deras TOPSIS‑baserade ramverk fungerar som ett återanvändbart betygssystem: när nya datamängder och algoritmer dyker upp kan de kopplas in i samma process för att visa vilka verktyg som bäst balanserar att snabbt fånga attacker, begränsa falska larm och förbli beräkningsmässigt praktiska.
Citering: Abu-Shareha, A.A., Abualhaj, M.M., Hussein, A. et al. Supervised machine learning intrusion detection review and multi-criteria evaluation. Sci Rep 16, 14525 (2026). https://doi.org/10.1038/s41598-026-44773-1
Nyckelord: intrångsdetektion, säkerhet inom maskininlärning, nätverksattacker, algoritmutvärdering, flerkriteriebeslutsfattande