Clear Sky Science · tr
Görüntü süper çözünürlüğü için hibrit dikkatle optimize edilmiş hiyerarşik çok ölçekli dönüştürücü mimarisi
Bulanık Başlangıçlardan Daha Keskin Görüntüler
Uydu fotoğraflarından şehir görüntülerine, MRI taramalarından akıllı telefon çekimlerine kadar pek çok görüntü istediğimizden daha bulanık başlar. Görüntü süper çözünürlüğü, düşük çözünürlüklü bir versiyondan keskin, ayrıntılı bir resim yeniden oluşturmayı amaçlayan bir dizi tekniktir. Bu makale, daha eski yöntemlerin genellikle bulanıklaştırdığı veya kaybettiği ince dokuları ve kenarları geri kazanmak için modern yapay zeka araçlarının zekice bir karışımını kullanan yeni bir yaklaşım sunuyor.
Görüntüleri Keskinleştirmenin Zor Olmasının Nedeni
Bulanık bir görüntüyü keskin hale getirmek kulağa basit geliyor, ama bu klasik bir “ters problem”tir: aynı bulanık görüntüyü üretebilecek birçok farklı yüksek çözünürlüklü sahne vardır. Zorluk, gerçeğe en yakın versiyonu tahmin etmektir. İnterpolasyon gibi basit hileler görüntüleri hızla büyütebilir ama genellikle düzgün, yapay görünen sonuçlar üretir. Geleneksel matematiksel modeller daha iyi sonuç verebilir, ancak yavaştırlar ve büyütme oranı arttıkça zorlanırlar. Konvolüsyonel sinir ağlarına ya da daha yeni Dönüştürücü (Transformer) modellerine dayanan güçlü derin öğrenme sistemleri bile karmaşık sahnelerde, özellikle yoğun şehir blokları veya çizgi roman sanatında, ince çizgileri, dokuları ve tekrarlayan desenleri kaçırma eğilimindedir.
Üç Aşamalı Yeni Bir Süper Çözünürlük İşlem Hattı
Bu eksikliklerle başa çıkmak için yazarlar Hiyerarşik Çok Ölçekli Dönüştürücü (HMT) mimarisini öneriyor. Bu mimari bir görüntüyü üç ana aşamada işler. İlk olarak, yüzeysel bir özellik çıkarıcı kenarlar ve basit dokular gibi temel desenleri yakalar; aynı zamanda standart bir yukarı örnekleme adımı orijinal yapıyı rehber olarak korur. 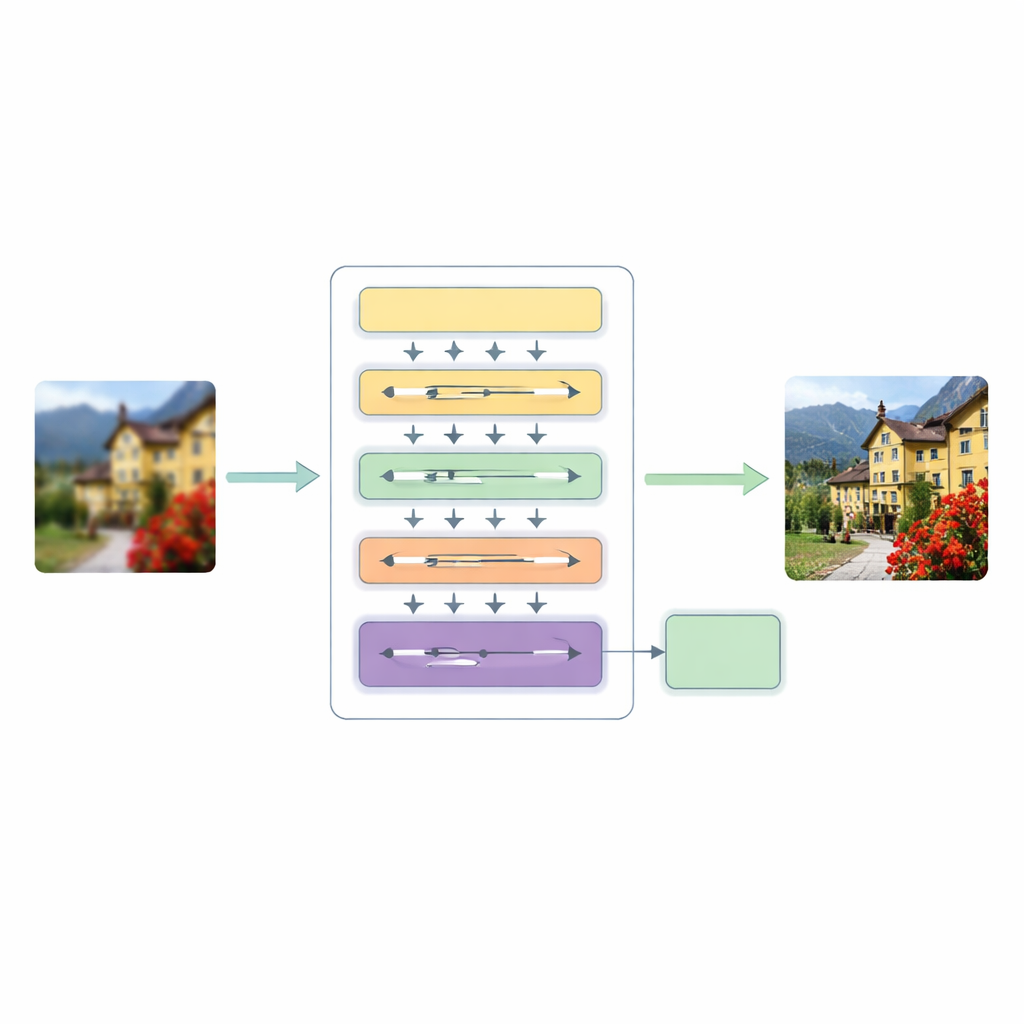
Küresel Desenleri Yerel Ayrıntılarla Harmanlamak
Bu sistemin kalbi, görüntüye iki tamamlayıcı şekilde bakan hibrit bir dikkat mekanizmasıdır. Bir dal, Fourier dönüşümü kullanarak görüntüyü geniş renk bölgeleri ve tekrarlayan yapılar gibi küresel desenler açısından analiz eden frekans alanında çalışır. Diğer dal ise yakın zamanda önerilen bir “durum uzayı” (state space) modelleme fikrini uzatarak görüntü boyunca birden fazla yönde tarama yapar ve geleneksel kendi-dikkati (self-attention)ın ağır maliyeti olmadan uzun menzilli ilişkileri yakalar. Bu iki görüşü birleştirerek ağ hem bir sahnenin genel düzenini hem de uzak ama ilişkili pikseller arasındaki ince ilişkileri anlayabilir; üstelik hesaplama yükünü makul düzeyde tutar.
Her Görüntüye Uçtan Uca Uyarlama
Aynı zamanda model, görüntünün en çok ihtiyaç duyduğu yerlere odaklanan Dinamik Konvolüsyonel Dikkat (Dynamic Convolutional Attention) kavramını tanıtır. Bu yöntem özellik kanallarını küçük gruplara ayırır ve her girişe farklı tepki veren, uzak bölgeleri bağlayabilen hafif, görüntüye bağımlı filtreler uygular. Bazı filtreler katmanlar arasında paylaşılırken diğerleri görüntüye göre uyarladığı için sistem maliyeti büyük oranda artırmadan esneklik kazanır. Dinamik bir füzyon modülü daha sonra kodlayıcı–kod çözücü ağlarda genellikle bulunan sert kısayol bağlantıların yerini alarak modelin farklı ölçek ve derinliklerden gelen bilgiyi ne kadar güçlü karıştıracağına karar vermesini sağlar. 
Pratikte Ne Kadar İyi Çalışıyor?
Araştırmacılar yöntemlerini doğal fotoğraflar, düz çizgiler ve tekrarlayan pencerelerle dolu şehir sahneleri ve ince mürekkep darbeleriyle dolu yüksek kontrastlı manga sayfaları dahil yaygın kullanılan görüntü setleri üzerinde test ettiler. Birkaç standart kıyaslama ve yakınlaştırma faktörü boyunca yaklaşımları tutarlı şekilde önde gelen süper çözünürlük sistemleriyle eşleşti veya onları geride bıraktı; netlik ve yapısal benzerlik ölçümlerinde biraz daha yüksek puanlar elde etti. Görsel karşılaştırmalar yeni modelin ince dokuları daha iyi koruduğunu, kenarlar çevresindeki bulanıklığı azalttığını ve karmaşık tekrarlayan desenleri daha sadık şekilde işlediğini gösteriyor; üstelik parametre ve hesaplama sayısını makul bir aralıkta tutuyor.
Çok Sayıda Gerçek Dünya Kullanımı İçin Daha Net Görüntüler
Günlük ifadeyle, bu çalışma bir görüntüyü yakınlaştırırken eksik ayrıntıları “doldurmanın” daha güvenilir bir yolunu sunuyor. Küresel desen analizi, yönlü bağlam ve uyarlanabilir filtrelemeyi dikkatli şekilde birleştirerek önerilen mimari, mevcut birçok araçtan daha keskin ve uyumlu sonuçlar üretiyor. Bu, şehir planlaması ve afet izleme gibi uygulamalardan tıbbi görüntüleme ve tüketici fotoğrafçılığına kadar, daha net görüntülere ihtiyaç duyulan fakat yalnızca düşük çözünürlüklü verilerin mevcut olduğu pek çok alanda fayda sağlayabilir.
Atıf: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Anahtar kelimeler: görüntü süper çözünürlüğü, derin öğrenme, dönüştürücü ağlar, dikkat mekanizmaları, bilgisayarlı görme