Clear Sky Science · es
Arquitectura transformadora jerárquica multiescala optimizada con atención híbrida para la superresolución de imágenes
Imágenes más nítidas a partir de comienzos borrosos
Desde fotos satelitales de ciudades hasta escáneres MRI y capturas de smartphones, muchas imágenes comienzan más borrosas de lo deseado. La superresolución de imagen es una familia de técnicas que intenta reconstruir una imagen nítida y detallada a partir de una versión de baja resolución. Este artículo presenta una nueva forma de hacerlo, usando una mezcla ingeniosa de herramientas de IA modernas para recuperar texturas finas y bordes que los métodos anteriores tienden a difuminar o perder.
Por qué es tan difícil lograr imágenes más nítidas
Convertir una imagen borrosa en una nítida parece sencillo, pero es un “problema inverso” clásico: muchas escenas en alta resolución pueden producir la misma imagen borrosa. El reto es adivinar la versión que más se aproxima a la realidad. Trucos simples como la interpolación pueden ampliar imágenes rápidamente, pero a menudo crean resultados suaves y de aspecto artificial. Los modelos matemáticos tradicionales pueden hacerlo mejor, aunque son lentos y presentan dificultades al aumentar el factor de zoom. Incluso los potentes sistemas de aprendizaje profundo, ya sean basados en redes convolucionales o en modelos Transformer más recientes, tienden a fallar en reproducir líneas diminutas, texturas y patrones repetidos, especialmente en escenas complejas como bloques urbanos densos o ilustraciones tipo cómic.
Una nueva tubería de superresolución en tres etapas
Para abordar estas limitaciones, los autores proponen una arquitectura Transformer Jerárquica Multiescala (HMT). Procesa la imagen en tres etapas principales. Primero, un extractor de características superficial captura patrones básicos como bordes y texturas simples, mientras que un paso estándar de sobremuestreo mantiene la estructura original como guía. 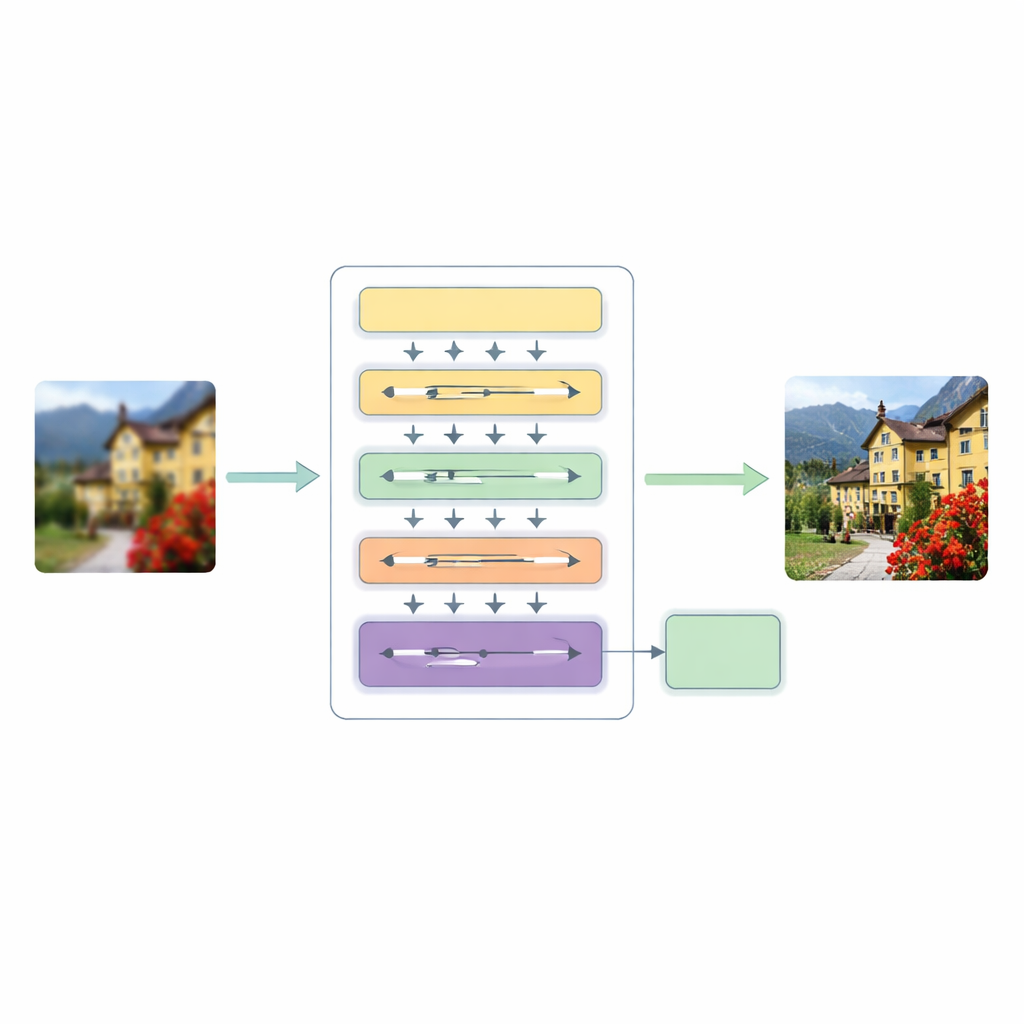
Mezclando patrones globales con detalles locales
El núcleo de este sistema es un mecanismo de atención híbrido que observa la imagen de dos maneras complementarias. Una rama trabaja en el dominio de la frecuencia, usando una transformada de Fourier para analizar la imagen en términos de patrones globales como grandes regiones de color y estructuras repetitivas. La otra rama amplía una idea reciente de modelado por “estado de espacio” para que pueda barrer la imagen en múltiples direcciones, captando relaciones de largo alcance sin el coste computacional elevado de la autoatención tradicional. Al fusionar estas dos visiones, la red puede comprender tanto la disposición general de una escena como las relaciones sutiles entre píxeles distantes pero correlacionados, todo ello manteniendo la computación en un nivel manejable.
Adaptándose a cada imagen sobre la marcha
En paralelo, el modelo introduce Atención Convolucional Dinámica, que centra su esfuerzo donde la imagen más lo necesita. Divide los canales de características en pequeños grupos y aplica filtros ligeros dependientes de la imagen que imitan los mejores aspectos de la atención: reaccionan de forma diferente a cada entrada y pueden conectar regiones distantes. Debido a que algunos filtros se comparten entre capas mientras que otros se adaptan por imagen, el sistema gana flexibilidad sin un gran aumento de coste. Un módulo de fusión dinámica sustituye las conexiones de atajo rígidas que suelen encontrarse en las redes encoder–decoder, permitiendo que el modelo decida con qué intensidad mezclar la información de distintas escalas y profundidades. 
¿Qué tan bien funciona en la práctica?
Los investigadores evaluaron su método en colecciones de imágenes ampliamente usadas, incluyendo fotos naturales, escenas urbanas ricas en líneas rectas y ventanas repetidas, y páginas de manga de alto contraste llenas de finos trazos de tinta. En varios benchmarks estándar y factores de zoom, su enfoque igualó o superó de forma consistente a los principales sistemas de superresolución, logrando puntuaciones ligeramente superiores en medidas de claridad y similitud estructural. Las comparaciones visuales muestran que el nuevo modelo preserva mejor las texturas diminutas, reduce el difuminado alrededor de los bordes y maneja los patrones repetidos complejos con mayor fidelidad, todo ello manteniendo su número de parámetros y el coste computacional dentro de un rango razonable.
Imágenes más claras para muchos usos del mundo real
En términos prácticos, este trabajo ofrece una forma más confiable de “rellenar” detalles faltantes al hacer zoom en una imagen. Al combinar cuidadosamente el análisis de patrones globales, el contexto direccional y el filtrado adaptativo, la arquitectura propuesta produce resultados más nítidos y coherentes que muchas herramientas existentes. Esto puede beneficiar aplicaciones que van desde la planificación urbana y la monitorización de desastres hasta la imagen médica y la fotografía de consumo, donde se necesitan imágenes más claras pero solo se dispone de datos de baja resolución.
Cita: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Palabras clave: superresolución de imagen, aprendizaje profundo, redes transformer, mecanismos de atención, visión por computadora